SQL — что это, для чего необходим язык, а также базовые функции для новичков. Основы T-SQL
Для этого понадобится установленная система управления базами данных (СУБД) DB2. Мы будем использовать диалект языка SQL, который используется именно в этой СУБД.
Первая команда, которую мы будем применять для создании базы данных - это команда CREATE DATABASE. Её синтаксис следующий:
CREATE TABLE ИМЯ_ТАБЛИЦЫ (имя_первого_столбца тип данных, ..., имя_последнего_столбца тип данных, первичный ключ, ограничения (не обязательно))
Так как наша база данных моделирует сеть аптек, то в ней есть такие сущности, как "Аптека" (таблица Pharmacy в нашем примере создания базы данных), "Препарат" (таблица Preparation в нашем примере создания базы данных), "Доступность (препаратов в аптеке)" (таблица Availability в нашем примере создания базы данных), "Клиент" (таблица Client в нашем примере создания базы данных) и другие, которые здесь подробно и разберём.
Разработке модели "сущность-связь" можно посвятить не одну статью, но если нас прежде всего интересуют команды языка SQL для создания базы данных и таблиц в ней, то условимся считать, что связи между сущностями уже нам понятны. На рисунке ниже приведено представление модели нашей базы данных с атрибутами сущностей (таблиц) и связями между таблицами.
Для увеличения рисунка можно нажать на него левой кнопкой мыши.
Как уже говорилось, в разбираемом здесь примере создания базы данных использовался вариант языка SQL, который используется в системе управления базами данных (СУБД) DB2. Он является регистронезависимым, то есть не имеет значение, набраны ли команды и отдельные слова в них строчными или прописными буквами. Для иллюстрации этой особенности приведены команды без особой системы набранные строчными и прописными буквами.
Теперь приступим к созданию команд. Первая наша команда SQL создаёт базу данных PHARMNETWORK:
Код SQL
CREATE DATABASE PHARMNETWORK
Описание таблицы PHARMACY (Аптека):
Пишем команду, которая создаёт таблицу PHARMACY (Аптека), значения первичного ключа PH_ID генерируются автоматически от 1 с шагом 1, вносится проверка на то, чтобы значения атрибута Address в этой таблице были уникальными:
Код SQL
CREATE TABLE PHARMACY(PH_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Address varchar(40) NOT NULL, PRIMARY KEY(PH_ID), CONSTRAINT PH_UNIQ UNIQUE(Address))
Описание таблицы GROUP (Группа препаратов):
Пишем команду, которая создаёт таблицу Group (Группа препаратов), значения первичного ключа GR_ID генерируются автоматически от 1 с шагом 1, проводится проверка уникальности наименования группы (для этого используется ключевое слово CONSTRAINT):
Код SQL
CREATE TABLE GROUP(GR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, PRIMARY KEY(GR_ID), CONSTRAINT GR_UNIQ UNIQUE(Name))
Описание таблицы PREPARATION (Препарат):
Команда, которая создаёт таблицу PREPARATION, значения первичного ключа PR_ID генерируются автоматически от 1 с шагом 1, определяется, что значения внешнего ключа GR_ID (Группа препаратов) не могут принимать значение NULL, определена проверка уникальности значений атрибута Name:
Код SQL
CREATE TABLE PREPARATION(PR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, GR_ID int NOT NULL, PRIMARY KEY(PR_ID), constraint PR_UNIQ UNIQUE(Name))
Далее нам требуется позаботиться об ограничениях целостности. Это очень удобно слелать с помощью команды alter table. Эта команда изучается на уроке SQL ALTER TABLE - изменение таблицы базы данных.
Теперь самое время создать таблицу AVAILABILITY (Доступность или Наличие препарата в аптеке). Её описание:
Пишем команду, которая создаёт таблицу AVAILABILITY. Определяются даты начала (не может быть NULL) и окончания (по умолчанию NULL).
Код SQL
CREATE TABLE AVAILABILITY(A_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL, QUANTITY INT NOT NULL, MART varchar(3) DEFAULT NULL, PRIMARY KEY(A_ID), CONSTRAINT AVA_UNIQ UNIQUE(PH_ID, PR_ID))
Создаём таблицу DEFICIT (Дефицит препарата в аптеке, то есть, неудовлетворённый запрос). Её описание:
Пишем команду, которая создаёт таблицу DEFICIT:
Код SQL
CREATE TABLE DEFICIT(D_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, Solution varchar(40) NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL)
Осталось немного. Мы уже дошли до команды, которая создаёт таблицу Employee (Сотрудник). Её описание:
Пишем команду, которая создаёт таблицу Employee (Сотрудник), с первичным ключом, генерируемым по тем же правилам, что и первичные ключи предыдущих таблиц, в которых они существуют. Внешним ключом PH_ID Сотрудник связан с PHARMACY (Аптекой).:
Код SQL
CREATE TABLE EMPLOYEE(E_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), F_Name varchar(40) NOT NULL, L_Name varchar(40) NOT NULL, POST varchar(40) NOT NULL, PH_ID INT NOT NULL, PRIMARY KEY(E_ID))
Очередь дошла до создании таблицы CLIENT (Клиент). Её описание:
Пишем команду, создающую таблицу CLIENT (Клиент), в отношении первичного ключа которого справедливо предыдущее описание. Особенность этой таблицы в том, что её атрибуты F_Name и L_Name имеют по умолчанию значение NULL. Это связано с тем, что клиенты могут быть как зарегистрированными, так и незарегистрированными. У последних значения имени и фамилии как раз и будут неопределёнными (то есть NULL):
Код SQL
CREATE TABLE CLIENT(C_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), FName varchar(40) DEFAULT NULL, LName varchar(40) DEFAULT NULL, DateReg varchar(20), PRIMARY KEY(C_ID))
Предпоследняя таблица в нашей базе данных - таблица BASKET (Корзина покупок). Её описание:
Пишем команду, создающую таблицу BASKET (Корзина покупок), так же с уникальным и инкрементируемым первичным ключом и связанную внешним ключами C_ID и E_ID с Клиентом и Сотрудником соответственно:
Код SQL
CREATE TABLE BASKET(BS_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), C_ID INT NOT NULL, E_ID INT NOT NULL, PRIMARY KEY(BS_ID))
И, наконец, последняя таблица в нашей базе данных - таблица BUYING (покупка). Её описание:
| Имя поля | Тип данных | Описание |
| B_ID | smallint | Идентификационный номер покупки |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| BS_ID | varchar(40) | Идентификационный номер корзины покупок |
| Price | varchar(20) | Цена |
| Date | varchar(20) | Дата |
Пишем команду, создающую таблицу BUYING (покупка), так же с уникальным и инкрементируемым первичным ключом и связанную внешними ключами BS_ID, PH_ID, PR_ID с Корзиной покупок, Аптекой и Препаратом соответственно:
Код SQL
CREATE TABLE BUYING(B_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), BS_ID INT NOT NULL, PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateB varchar(20) NOT NULL, Price Double NOT NULL, PRIMARY KEY(B_ID))
И совсем уже в завершение темы создания базы данных обещанное отступление о соблюдении ограничений целостности, когда решение - более сложное, чем написание команды. В нашем примере необходимо соблюдать следующее условие: при покупке единицы препарата значение количества этого препарата в таблице AVAILABILITY должно соответственно уменьшиться. Вообще говоря, для таких операций в языке SQL существуют особые средства, называемые триггерами. Но триггеры - вещь капризная: на практике они могут и не сработать или сработать не так, как предусмотрено. Поэтому разработчики по возможности ищут программные средства решения таких задач, пример которых упомянут в этом абзаце.
Аннотация: Определяется процесс создания базы данных. Описываются операторы создания, изменения базы данных. Рассматривается возможность указания имени файла или нескольких файлов для хранения данных, размеров и местоположения файлов. Анализируются операторы создания, изменения, удаления пользовательских таблиц. Приводится описание параметров для объявления столбцов таблицы. Дается понятие и характеристика индексов. Рассматриваются операторы создания и изменения индексов. Определяется роль индексов в повышении эффективности выполнения операторов SQL.
База данных
Создание базы данных
В различных СУБД процедура создания баз данных обычно закрепляется только за администратором баз данных . В однопользовательских системах принимаемая по умолчанию база данных может быть сформирована непосредственно в процессе установки и настройки самой СУБД. Стандарт SQL не определяет, как должны создаваться базы данных , поэтому в каждом из диалектов языка SQL обычно используется свой подход. В соответствии со стандартом SQL, таблицы и другие объекты базы данных существуют в некоторой среде. Помимо всего прочего, каждая среда состоит из одного или более каталогов , а каждый каталог – из набора схем . Схема представляет собой поименованную коллекцию объектов базы данных , некоторым образом связанных друг с другом (все объекты в базе данных должны быть описаны в той или иной схеме ). Объектами схемы могут быть таблицы , представления, домены, утверждения, сопоставления, толкования и наборы символов. Все они имеют одного и того же владельца и множество общих значений, принимаемых по умолчанию.
Стандарт SQL оставляет за разработчиками СУБД право выбора конкретного механизма создания и уничтожения каталогов , однако механизм создания и удаления схем регламентируется посредством операторов CREATE SCHEMA и DROP SCHEMA . В стандарте также указано, что в рамках оператора создания схемы должна существовать возможность определения диапазона привилегий, доступных пользователям создаваемой схемы . Однако конкретные способы определения подобных привилегий в разных СУБД различаются.
В настоящее время операторы CREATE SCHEMA и DROP SCHEMA реализованы в очень немногих СУБД. В других реализациях, например, в СУБД MS SQL Server, используется оператор CREATE DATABASE .
Создание базы данных в среде MS SQL Server
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных , а затем принадлежащий ей журнал транзакций . Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных ) и *.ldf . (для журнала транзакций ). В файле базы данных записываются сведения об основных объектах (таблицах , индексах , представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE . Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
<определение_базы_данных> ::= CREATE DATABASE имя_базы_данных [ <определение_файла> [,...n] ] [,<определение_группы> [,...n] ] ] [ LOG ON {<определение_файла>[,...n] } ] [ FOR LOAD | FOR ATTACH ]
Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf . В этом случае основная информация о базе данных располагается в первичном (PRIMARY ) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле . Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных .
Параметр PRIMARY определяет первичный файл . Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций . Имя файла для журнала транзакций генерируется на основе имени базы данных , и в конце к нему добавляются символы _log .
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
<определение_файла>::= ([ NAME=логическое_имя_файла,] FILENAME="физическое_имя_файла" [,SIZE=размер_файла ] [,MAXSIZE={max_размер_файла |UNLIMITED } ] [, FILEGROWTH=величина_прироста ])[,...n]
Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных . При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH ) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
<определение_группы>::=FILEGROUP имя_группы_файлов <определение_файла>[,...n]
Пример 3.1 . Создать базу данных , причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
CREATE DATABASE Archive ON PRIMARY (NAME=Arch1, FILENAME=’c:\user\data\archdat1.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Arch2, FILENAME=’c:\user\data\archdat2.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Arch3, FILENAME=’c:\user\data\archdat3.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20) LOG ON (NAME=Archlog1, FILENAME=’c:\user\data\archlog1.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20), (NAME=Archlog2, FILENAME=’c:\user\data\archlog2.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20) Пример 3.1. Создание базы данных.
Введение
Эта статья открывает небольшой цикл, посвященный азам взаимодействия с базами данных (БД) в Java и введению в SQL . Многие программы заняты обработкой и модификацией информации, её поддержкой в актуальном состоянии. Поскольку данные - весьма важная часть логики программ, то под них зачастую выделяют отдельное хранилище. Информация в нём структурирована и подчинена специальным правилам, чтобы обеспечить правильность обработки и хранения. Доступ к данным и их изменение осуществляется с помощью специального языка запросов - SQL (Structured Query Language). Система управления базами данных - это ПО, которое обеспечивает взаимодействие разных внешних программ с данными и дополнительные службы (журналирование, восстановление, резервное копирование и тому подобное), в том числе посредством SQL. То есть программная прослойка между данными и внешними программами с ними работающими. В этой части ответим на вопросы что такое SQL, что такое SQL сервер и создадим первую программу для взаимодействия с СУБД.Виды СУБД
Существует несколько видов СУБД по способу организации хранения данных:- Иерархические. Данные организованы в виде древовидной структуры. Пример - файловая система, которая начинается с корня диска и далее прирастает ветвями файлов разных типов и папок разной степени вложенности.
- Сетевые. Видоизменение иерархической, у каждого узла может быть больше одного родителя.
- Объектно-ориентированные. Данные организованы в виде классов/объектов c их атрибутами и принципами взаимодействия согласно ООП.
- Реляционные. Данные этого вида СУБД организованы в таблицах. Таблицы могут быть связаны друг с другом, информация в них структурирована.
SQL
Внешние программы формируют запросы к СУБД на языке управления данными Structured Query Language. Что такое SQL и чем отличается от привычных языков программирования? Одна из особенностей SQL – декларативность. То есть, SQL - декларативный язык . Это значит, что, вбивая команды, то есть, создавая запросы к SQL-серверу, мы описываем, что именно хотим получить, а не каким способом. Посылая серверу запрос SELECT * FROM CUSTOMER (приблизительный перевод с SQL на русский: «сделать выборку из таблицы COSTUMER, выборка состоит из всех строк таблица» ), мы получим данные по всем пользователям. Совершенно неважно, как и откуда сервер загрузит и сформирует интересующие нас данные. Главное – правильно сформулировать запрос.- Что такое SQL-Сервер и как он работает? Взаимодействие с СУБД происходит по клиент-серверному принципу. Некая внешняя программа посылает запрос в виде операторов и команд на языке SQL, СУБД его обрабатывает и высылает ответ. Для упрощения примем, что SQL Сервер = СУБД.
- Data Definition Language (DDL ) – определения данных. Создание структуры БД и её объектов;
- Data Manipulation Language(DML ) – собственно взаимодействие с данными: вставка, удаление, изменение и чтение;
- Transaction Control Language (TCL ) – управление транзакциями;
- Data Control Language(DCL ) – управление правами доступа к данным и структурам БД.
JDBC
В 80-е годы прошлого века персональные компьютеры типа PC XT/AT завоевали рынок. Во многом это произошло благодаря модульности их конструкции. Это означает, что пользователь мог довольно просто менять ту или иную составную часть своего компьютера (процессор, видеокарту, диски и тому подобное). Это замечательное свойство сохранилось и поныне: мы меняем видеокарту и обновляем драйвер (иногда он и вовсе обновляется сам, в автоматическом режиме). Чаще всего при таких манипуляциях ничего плохого не происходит, и существующие программы продолжат работать с обновившейся системой без переустановки. Аналогично и для работы в Java с СУБД. Для стандартизации работы с SQL-серверами взаимодействие с ней можно выполнять через единую точку - JDBC (Java DataBase Connectivity). Она представляет собой реализацию пакета java.sql для работы с СУБД. Производители всех популярных SQL-серверов выпускают для них драйверы JDBC. Рассмотрим схему ниже. Приложение использует экземпляры классов из java.sql . Затем мы передаем необходимые команды для получения/модификации данных. Далее java.sql через jdbc-драйвер взаимодействует с СУБД и возвращает нам готовый результат. Для перехода на СУБД другого производителя часто достаточно сменить JDBC и выполнить базовые настройки. Остальные части программы при этом не меняются.Первая программа
Приступим к практической части. Создадим Java-проект с помощью IDE JetBrains IntelliJ IDEA . Заметим, что редакция Ultimate Edition содержит в своём составе замечательный инструмент для работы с SQL и БД - Data Grip . Однако она платная для большинства пользователей. Так что нам для учебных целей остается использовать общедоступную IntelliJ IDEA Community Edition . Итак: Теперь мы умеем подключаться к СУБД и отключаться от неё. Каждый шаг отражается в консоли. При первом подключении к СУБД создаётся файл базы данных stockExchange.mv.db .Разбор кода
Собственно код: package sql. demo; import java. sql. *; public class StockExchangeDB { // Блок объявления констант public static final String DB_URL = "jdbc:h2:/c:/JavaPrj/SQLDemo/db/stockExchange" ; public static final String DB_Driver = "org.h2.Driver" ; public static void main (String args) { try { Class. forName (DB_Driver) ; //Проверяем наличие JDBC драйвера для работы с БД Connection connection = DriverManager. getConnection (DB_URL) ; //соединениесБД System. out. println ("Соединение с СУБД выполнено." ) ; connection. close () ; // отключение от БД System. out. println ("Отключение от СУБД выполнено." ) ; } catch (ClassNotFoundException e) { e. printStackTrace () ; // обработка ошибки Class.forName System. out. println ("JDBC драйвер для СУБД не найден!" ) ; } catch (SQLException e) { e. printStackTrace () ; // обработка ошибок DriverManager.getConnection System. out. println ("Ошибка SQL !" ) ; } } }Блок констант:
- DB_Driver : Здесь мы определили имя драйвера, которое можно узнать, например, кликнув мышкой на подключенную библиотеку и развернув её структуру в директории lib текущего проекта.
- DB_URL : Адрес нашей базы данных. Состоит из данных, разделённых двоеточием:
- Протокол=jdbc
- Вендор (производитель/наименование) СУБД=h2
- Расположение СУБД, в нашем случае путь до файла (c:/JavaPrj/SQLDemo/db/stockExchange). Для сетевых СУБД тут дополнительно указываются имена или IP адреса удалённых серверов, TCP/UDP номера портов и так далее.
Обработка ошибок:
Вызов методов нашего кода может вернуть ошибки, на которые следует обратить внимание. На данном этапе мы просто информируем о них в консоли. Заметим, что ошибки при работе с СУБД - это чаще всего SQLException .Логика работы:
- Class.forName (DB_Driver) – убеждаемся в наличии соответствующего JDBC-драйвера (который мы ранее загрузили и установили).
- DriverManager.getConnection (DB_URL) – устанавливаем соединение СУБД. По переданному адресу, JDBC сама определит тип и местоположение нашей СУБД и вернёт Connection, который мы можем использовать для связи с БД.
- connection.close() – закрываем соединение с СУБД и завершаем работу с программой.
Пример создания локальной базы данных Microsoft SQL Server в MS Visual Studio
В данной теме показано решение задачи создания базы данных типа SQL Server с помощью MS Visual Studio . Рассматриваются следующие вопросы:
- работа с окном Server Explorer в MS Visual Studio ;
- создание локальной базы данных типа SQL Server Database ;
- создание таблиц в базе данных;
- редактирование структур таблиц;
- связывание таблиц базы данных между собой;
- внесение данных в таблицы средствами MS Visual Studio .
Условие задачи
Используя средства MS Visual Studio создать базу данных типа MS SQL Server с именем Education. База данных содержит две таблицы Student и Session. Таблицы между собой связаны по некоторыму полю.
Структура первой таблицы «Student».
Структура второй таблицы “Session ”.

Выполнение
1. Загрузить MS Visual Studio .
2. Активировать окно Server Explorer .
Для работы с базами данных корпорация Microsoft предлагает облегченный сервер баз данных Microsoft SQL Server . Существуют разные версии Microsoft SQL Server , например: Microsoft SQL Server 2005 , Microsoft SQL Server 2008 , Microsoft SQL Server 2014 и прочие версии.
Загрузить эти версии можно с сайта Microsoft www.msdn.com .
Этот сервер отлично подходит для работы с базами данных. Он бесплатен и имеет графический интерфейс для создания и администрирования баз данных с помощью SQL Server Management Tool .
Прежде всего, перед созданием базы данных, нужно активировать утилиту Server Explorer . Для этого, в MS Visual Studio нужно вызвать (рис. 1)
View -> Server Explorer Рис. 1. Вызов Server Explorer
Рис. 1. Вызов Server Explorer
После вызова окно Server Explorer будет иметь приблизительный вид, как показано на рисунке 2.
 Рис. 2. Окно Server Explorer
Рис. 2. Окно Server Explorer
3. Создание базы данных “Education”.
Чтобы создать новую базу данных, базирующуюся на поставщике данных Microsoft SQL Server , нужно кликнуть на узле Data Connections, а потом выбрать “Create New SQL Server Database … ” (рис. 3).
 Рис. 3. Вызов команды создания базы данных SQL Server
Рис. 3. Вызов команды создания базы данных SQL Server
В результате откроется окно «Create New SQL Server Database » (рис. 4).
В окне (в поле «Server Name») указывается имя локального сервера, установленного на вашем компьютере. В нашем случае это имя “SQLEXPRESS ”.
В поле «New database name: » указывается имя создаваемой базы данных. В нашем случае это имя Education.
Опцию Use Windows Autentification нужно оставить без изменений и нажать кнопку OK .
 Рис. 4. Создание новой базы данных SQL Server 2008 Express
с помощью MS Visual Studio 2010
Рис. 4. Создание новой базы данных SQL Server 2008 Express
с помощью MS Visual Studio 2010
После выполненных действий, окно Server Explorer примет вид, как показано на рисунке 5. Как видно из рисунка 5, в список имеющихся баз данных добавлена база данных Education с именем
sasha-pc\sqlexpress.Education.dbo Рис. 5. Окно Server Explorer
после добавления базы данных Education
Рис. 5. Окно Server Explorer
после добавления базы данных Education
4. Объекты базы данных Education.
Если развернуть базу данных Education (знак «+ »), то можно увидеть список из следующих основных объектов:
- Database Diagrams – диаграммы базы данных. Диаграммы показывают связи между таблицами базы данных, отношения между полями разных таблиц и т.п.;
- Tables – таблицы, в которых помещаются данные базы данных;
- Views – представления. Отличие между представлениями и таблицами состоит в том, что таблицы баз данных содержат данные, а представления данных не содержат их, а содержимое выбирается из других таблиц или представлений;
- Stored procedures – хранимые процедуры. Они представляют собою группу связанных операторов на языке SQL, что обеспечивает дополнительную гибкость при работе с базой данных.
5. Создание таблицы Student.
На данный момент база данных Education абсолютно пустая и не содержит никаких объектов (таблиц, сохраненных процедур, представлений и т.д.).
Чтобы создать таблицу, нужно вызвать контекстное меню (клик правой кнопкой мышки) и выбрать команду “Add New Table ” (рисунок 6).
 Рис. 6. Команда добавления новой таблицы
Рис. 6. Команда добавления новой таблицы
Существует и другой вариант добавления таблицы базы данных с помощью команд меню Data:
Data -> Add New -> Table
Рис. 7. Альтернативный вариант добавления новой таблицы
В результате откроется окно добавления таблицы, которое содержит три столбца (рисунок 8). В первом столбце “Column Name” нужно ввести название соответствующего поля таблицы базы данных. Во втором столбце “Data Type” нужно ввести тип данных этого поля. В третьем столбце “ Allow Nulls ”указывается опция о возможности отсутствия данных в поле.
 Рис. 8. Окно создания новой таблицы
Рис. 8. Окно создания новой таблицы
С помощью редактора таблиц нужно сформировать таблицу Student как изображено на рисунке 9. Имя таблицы нужно задать при ее закрытии.
В редакторе таблиц можно задавать свойства полей в окне Column Properties. Для того, чтобы задать длину строки (nvchar) в символах, в окне Column Properties есть свойство Length. По умолчанию значения этого свойства равно 10.
 Рис. 9. Таблица Student
Рис. 9. Таблица Student
Следующим шагом нужно задать ключевое поле. Это осуществляется вызовом команды “Set Primary Key ” из контекстного меню поля Num_book. С помощью ключевого поля будут установлены связи между таблицами. В нашем случае ключевым полем есть номер зачетной книжки.
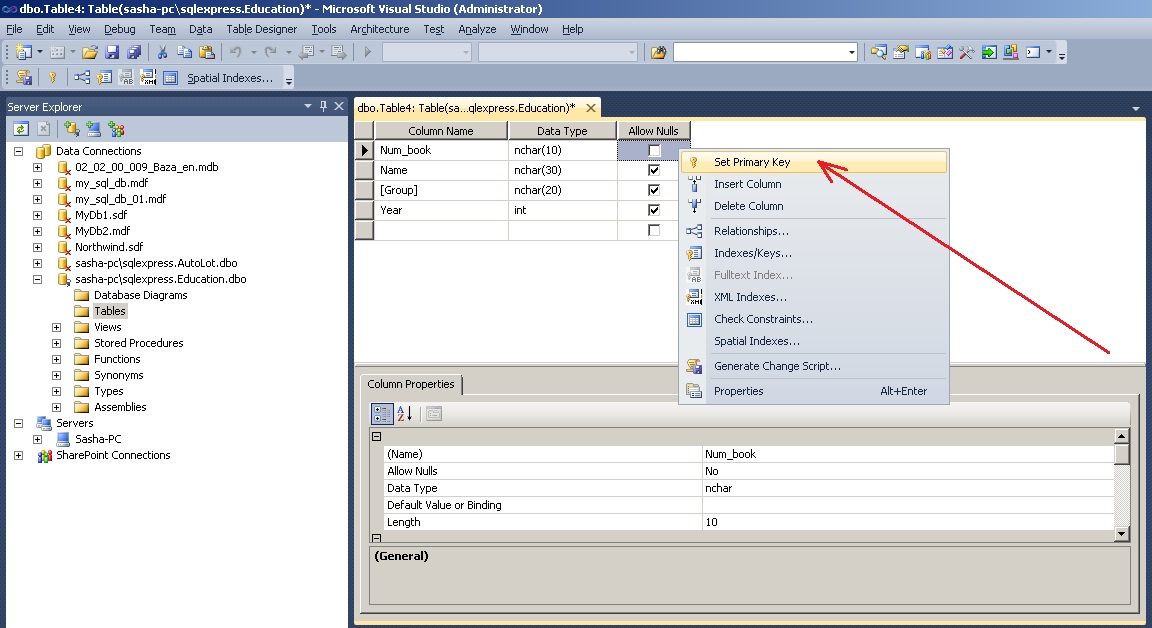 Рис. 10. Задание ключевого поля
Рис. 10. Задание ключевого поля
После установки первичного ключа окно таблицы будет иметь вид как изображено на рисунке 11.
 Рис. 11. Таблица Student
после окончательного формирования
Рис. 11. Таблица Student
после окончательного формирования
Теперь можно закрыть таблицу. В окне сохранения таблицы нужно задать ее имя – Student (рис. 12).
 Рис. 12. Ввод имени таблицы Student
Рис. 12. Ввод имени таблицы Student
6. Создание таблицы Session.
По образцу создания таблицы Student создается таблица Session.
На рисунке 13 изображен вид таблицы Session после окончательного формирования. Первичный ключ (Primary Key ) устанавливается в поле Num_book. Имя таблицы задается Session.

Рис. 13. Таблица Session
После выполненных действий, в окне Server Explorer будут отображаться две таблицы Student и Session.
Таким образом, в базу данных можно добавлять любое количество таблиц.
7. Редактирование структуры таблиц.
Бывают случаи, когда нужно изменить структуру таблицы базы данных.
Для того, чтобы вносить изменения в таблицы базы данных в MS Visual Studio, сначала нужно снять опцию “Prevent Saving changes that require table re-creation ” как показано на рисунке 14. Иначе, MS Visual Studio будет блокировать внесения изменений в ранее созданную таблицу. Окно Options, показанное на рисунке 14 вызывается из меню Tools в такой последовательности:
Tools -> Options -> Database Tools -> Table and Database Designers Рис. 14. Опция “Prevent Saving changes that require table re-creation
”
Рис. 14. Опция “Prevent Saving changes that require table re-creation
”
После настройки можно изменять структуру таблицы. Для этого используется команда “Open Table Definition ” (рисунок 15) из контекстного меню, которая вызывается для выбранной таблицы (правый клик мышкой).
 Рис. 15. Вызов команды “Open Table Definition
”
Рис. 15. Вызов команды “Open Table Definition
”
Также эта команда размещается в меню Data:
Data -> Open Table DefinitionПредварительно таблицу нужно выделить.
8. Установление связей между таблицами.
В соответствии с условием задачи, таблицы связаны между собою по полю Num_book.
Чтобы создать связь между таблицами, сначала нужно (рисунок 16):
- выделить объект Database Diagram;
- выбрать команду Add New Diagram из контекстного меню (или из меню Data).

Рис. 16. Вызов команды добавления новой диаграммы
В результате откроется окно добавления новой диаграммы Add Table (рисунок 17). В этом окне нужно выбрать последовательно две таблицы Session и Student и нажать кнопку Add.
 Рис. 17. Окно добавления таблиц к диаграмме
Рис. 17. Окно добавления таблиц к диаграмме
 Рис. 18. Таблицы Student
и Session
после добавления их к диаграмме
Рис. 18. Таблицы Student
и Session
после добавления их к диаграмме
Чтобы начать устанавливать отношение между таблицами, надо сделать клик на поле Num_book таблицы Student, а потом (не отпуская кнопку мышки) перетянуть его на поле Num_book таблицы Session.
В результате последовательно откроются два окна: Tables and Columns (рис. 19) и Foreign Key Relationship (рис. 20), в которых нужно оставить все как есть и подтвердить свой выбор на OK.
В окне Tables and Columns задается название отношения (FK_Session_Student ) и названия родительской (Student) и дочерней таблиц.
 Рис. 19. Окно Tables
and Columns
Рис. 19. Окно Tables
and Columns
 Рис. 20. Окно настройки свойств отношения
Рис. 20. Окно настройки свойств отношения
После выполненных действий будет установлено отношение между таблицами (рисунок 21).
 Рис. 21. Отношение между таблицами Student
и Session
Рис. 21. Отношение между таблицами Student
и Session
Сохранение диаграммы осуществляется точно также как и сохранение таблицы. Имя диаграммы нужно выбрать на свое усмотрение (например Diagram1).
После задания имени диаграммы откроется окно Save, в котором нужно подтвердить свой выбор (рисунок 22).
 Рис. 22. Подтверждение сохранения изменений в таблицах
Рис. 22. Подтверждение сохранения изменений в таблицах
9. Ввод данных в таблицы.
Система Microsoft Visual Studio разрешает непосредственно вносить данные в таблицы базы данных.
В нашем случае, при установлении связи (рис. 19) первичной (Primary Key Table ) избрана таблица Student. Поэтому, сначала нужно вносить данные в ячейки именно этой таблицы. Если попробовать сначала внести данные в таблицу Session, то система заблокирует такой ввод с выводом соответствующего сообщения.
Чтобы вызвать режим ввода данных в таблицу Student, нужно вызвать команду Show Table Data из контекстного меню (клик правой кнопкой мышки) или с меню Data (рис. 23).
 Рис. 23. Команда Show Table Data
Рис. 23. Команда Show Table Data
Откроется окно, в котором нужно ввести входные данные (рис. 24).
 Рис. 24. Ввод данных в таблице Student
Рис. 24. Ввод данных в таблице Student
После внесения данных в таблицу Student нужно внести данные в таблицу Session.
При внесении данных в поле Num_book таблицы Session нужно вводить точно такие же значения, которые введены в поле Num_book таблицы Student (поскольку эти поля связаны между собой).
Например, если в поле Num_book таблицы Student введены значения “101”, “102”, “103” (см. рис. 24), то следует вводить именно эти значения в поле Num_book таблицы Session. Если попробовать ввести другое значение, система выдаст приблизительно следующее окно (рис. 25).
 Рис. 25. Сообщение об ошибке ввода данных связанных таблиц Student
и Session
Рис. 25. Сообщение об ошибке ввода данных связанных таблиц Student
и Session
Таблица Session с введенными данными изображена на рисунке 26.
Microsoft SQL Server 005 - Пример создания «*.mdf» файла локальной базы данных Microsoft SQL Server в Microsoft Visual Studio
Инсталлируйте программное обеспечение SQL Server Management Studio. Это программное обеспечение можно бесплатно загрузить с сайта Microsoft. Оно позволяет вам подключаться и управлять вашим SQL сервером через графический интерфейс вместо того, чтобы использовать командную строку.
Запустите SQL Server Management Studio. При первом запуске программы вам будет предложено выбрать, к какому сервер подключаться. Если у вас уже есть сервер и вы работаете, имеете необходимые разрешения для подключения к нему, то можете ввести адрес сервера и идентификационную информацию. Если вы хотите создать локальную базу данных, установите имя базы данных Database Name как. и тип аутентификации как "Windows Authentication".
- Нажмите кнопку Подключить чтобы продолжить.
Определите место для папки Databases. После выполнения соединения с сервером (локальное или удаленное), откроется окно обозревателя объектов Object Explorer в левой стороне экрана. В верхней части дерева обозревателя объектов будет сервер, к которому вы подключены. Если дерево не расширено, нажмите на значок "+" рядом с ним. Определите место папки базы данных Databases.
Создайте новую базу данных. Щелкните правой кнопкой мыши по папке Databases и выберите пункт "New Database...". Появится окно, которое позволяет настроить базу данных перед ее созданием. Дайте имя базе данных, которое поможет вам идентифицировать ее. Большинство пользователей могут оставить значения остальных настроек по умолчанию.
- Вы заметите, что при вводе имени базы данных два дополнительных файла будут созданы автоматически: Data и Log. Файл данных (Data) вмещает все данные в вашей базе данных, в то время как файл журнала (Log) отслеживает изменения в базе данных.
- Нажмите кнопку OK, чтобы создать базу данных. Вы увидите вашу новую базу данных, которая появится в развернутой папке Databases. Она будет иметь значок цилиндра.
Создайте таблицу. База данных может только хранить данные, если вы создаете структуру для этих данных. Таблица содержит информацию, которую вы вводите в вашу базу данных, и вам нужно будет создать ее, прежде чем можете продолжить. Разверните новую базу данных в папке Databases, и щелкните правой кнопкой мыши на папке Tables и выберите пункт "New Table...".
- Windows откроется в остальной части экрана, позволяя вам управлять вашей новой таблицей.
Создайте Primary Key (первичный ключ). Настоятельно рекомендуется, чтобы вы создавали первичный ключ в качестве первого столбца в вашей таблице. Он действует как идентификационный номер, или номер записи, что позволит вам легко выводить эти записи позже. Для его создания введите "ID" в столбце Name field, тип int в поле Data Type и снимите флажок "Allow Nulls". Нажмите на значок Key iна панели инструментов, чтобы установить этот столбец в качестве Primary Key (первичного ключа).
- Вы же не хотите допустить нулевые значения, так как всегда хотите иметь запись по крайней мере "1". Если вы разрешите 0, ваша первая запись будет "0".
- В окне Column Properties прокрутите вниз, пока не найдете опцию Identity Specification. Разверните ее и установите "(ls Identity)" на "Yes". Эта опция автоматически увеличит значение столбца ID для каждой записи, автоматически нумеруя каждую новую запись.
Разберитесь, как устроены таблицы. Таблицы состоят из полей или столбцов. Каждый столбец представляет один из аспектов записи базы данных. Например, если вы создаете базу данных сотрудников, вы можете иметь столбец "FirstName", столбец "LastName", столбец "Address" и столбец "PhoneNumber".
Создайте остальные столбцы. Когда закончите заполнение полей для Primary Key, заметите, что новые поля появляются под ним. Это позволит вам войти в свой следующий столбец. Заполните поля, как считаете нужным, и убедитесь, что правильно выбрали тип данных для информации, которая будет введена в этом столбце:
- nchar(#) - это тип данных следует использовать для текста, как имена, адреса и т.д. Число в скобках – это максимальное количество символов, разрешенное для это го поля. Установление лимита гарантирует, что ваш размер базы данных остается управляемым. Номера телефонов должны быть сохранены в этом формате, так как вы не выполняете математические функции с ними.
- int - это целые числа, и обычно используются в поле идентификатора.
- decimal(x,y) - будут хранить числа в десятичной форме, а числа в скобках обозначают соответственно общее количество цифр и количество цифр после десятичной. Например, decimal(6,2) будет сохранять числа как 0000.00.
Сохраните вашу таблицу. Когда вы закончите создавать свои столбцы, то вам нужно сохранить таблицу перед вводом информации. Щелкните на значке Save на панели инструментов, а затем введите название таблицы. Рекомендуется присваивать имя таблице таким образом, чтобы оно помогло вам распознать содержимое, особенно для больших баз данных с несколькими таблицами.
Добавьте данные в вашу таблицу. После того, как вы сохранили таблицу, можете начать добавлять в нее данные. Откройте папку Tables в окне обозревателя объектов Object Explorer. Если вашей новой таблицы нет в списке, щелкните правой кнопкой мыши на папке Tables и выберите Refresh. Щелкните правой кнопкой мыши по таблице и выберите "Edit Top 200 Rows".