Fisher 분포의 임계값입니다. 피셔의 정확한 기준
이 예를 사용하여 결과 회귀 방정식의 신뢰성을 평가하는 방법을 고려해 보겠습니다. 동일한 테스트를 사용하여 회귀 계수가 동시에 0(a=0, b=0)과 같다는 가설을 테스트합니다. 즉, 계산의 본질은 질문에 대답하는 것입니다. 추가 분석 및 예측에 사용할 수 있습니까?
두 표본의 분산이 비슷한지 다른지 확인하려면 이 t-검정을 사용하세요.
따라서 분석의 목적은 특정 수준의 α에서 결과 회귀 방정식이 통계적으로 신뢰할 수 있다고 말할 수 있는 추정치를 얻는 것입니다. 이를 위해 결정계수 R 2 가 사용됨.
회귀 모델의 중요성 테스트는 Fisher의 F 테스트를 사용하여 수행됩니다. 이 테스트의 계산된 값은 연구 중인 지표의 원래 관찰 계열의 분산과 잔차 시퀀스의 분산에 대한 편견 없는 추정치의 비율로 확인됩니다. 이 모델의 경우.
k 1 =(m) 및 k 2 =(n-m-1) 자유도로 계산된 값이 주어진 유의 수준에서 표로 작성된 값보다 큰 경우 모델은 유의미한 것으로 간주됩니다.
여기서 m은 모형의 요인 수입니다.
쌍선형 회귀 분석의 통계적 유의성은 다음 알고리즘을 사용하여 평가됩니다.
1. 방정식 전체가 통계적으로 유의하지 않다는 귀무 가설이 제시됩니다. 유의 수준 α에서 H 0: R 2 =0입니다.
2. 다음으로 F 기준의 실제 값을 결정합니다. ![]()
![]()
여기서 쌍별 회귀의 경우 m=1입니다.
3. 표로 작성된 값은 총 제곱합(더 큰 분산)에 대한 자유도가 1이고 잔차에 대한 자유도가 1이라는 점을 고려하여 주어진 유의 수준에 대한 Fisher 분포표에서 결정됩니다. 선형 회귀 분석의 제곱합(더 작은 분산)은 n-2입니다(또는 Excel 함수 FRIST(probability,1,n-2)를 통해).
F 테이블은 주어진 자유도와 유의 수준 α를 갖는 무작위 요인의 영향을 받는 기준의 가능한 최대 값입니다. 유의 수준 α는 올바른 가설이 참일 경우 이를 기각할 확률입니다. 일반적으로 α는 0.05 또는 0.01로 간주됩니다.
4. F-검정의 실제 값이 표 값보다 작으면 귀무가설을 기각할 이유가 없다고 말합니다.
그렇지 않으면 귀무가설이 기각되고 확률(1-α)로 방정식 전체의 통계적 유의성에 대한 대립가설이 채택됩니다.
자유도 k 1 =1 및 k 2 =48, F 테이블 = 4인 기준의 테이블 값
결론: 실제 값 F > F 테이블이므로 결정 계수는 통계적으로 유의합니다( 발견된 회귀 방정식 추정치는 통계적으로 신뢰할 수 있습니다.) .
분산 분석
.회귀 방정식 품질 지표
예. 총 25개 무역 기업을 기반으로 다음 특성 간의 관계를 연구합니다. X - 제품 A 가격, 천 루블; Y는 무역 기업의 이익, 백만 루블입니다. 회귀 모델을 평가할 때 다음과 같은 중간 결과가 얻어졌습니다. ∑(y i -y x) 2 = 46000; ∑(y i -y avg) 2 = 138000. 이 데이터에서 어떤 상관관계 지표를 결정할 수 있습니까? 이 결과를 기반으로 이 지표의 값을 계산하고 다음을 사용합니다. 피셔의 F 테스트회귀 모델의 품질에 대한 결론을 도출합니다.
해결책. 이 데이터로부터 우리는 경험적 상관관계 비율을 결정할 수 있습니다:  , 여기서 ∑(y 평균 -y x) 2 = ∑(y i -y 평균) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000입니다.
, 여기서 ∑(y 평균 -y x) 2 = ∑(y i -y 평균) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000입니다.
θ 2 = 92,000/138000 = 0.67, θ = 0.816(0.7< η < 0.9 - связь между X и Y высокая).
피셔의 F 테스트: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 - 1 - 1) = 46. F 테이블(1; 23) = 4.27
실제 값 F > Ftable이므로 발견된 회귀 방정식의 추정치는 통계적으로 신뢰할 수 있습니다.
질문: 회귀 모델의 중요성을 테스트하는 데 어떤 통계가 사용됩니까?
답변: 전체 모델의 중요성을 확인하기 위해 F-통계(Fisher's test)가 사용됩니다.
목적.두 분산이 동일한 일반 모집단에 속하므로 둘이 동일하다는 가설을 검정합니다.
귀무 가설.에스 2 2 = 에스 1 2
대안 가설. 중요 영역이 어떻게 다른지에 따라 N A에 대해 다음과 같은 옵션이 있습니다.
1. 에스 1 2 > 에스 2 2 . 가장 일반적으로 사용되는 옵션은 HA입니다. 임계 영역은 F-분포의 위쪽 꼬리입니다.
2. 에스 1 2< S 2 2 . Критическая область - нижний хвост F-распределения. Ввиду частого отсутствия нижнего хвоста, в таблицах критическую область обычно сводят к варианту 1, меняя местами дисперсии.
3. 양면 S 1 2 ≠ S 2 2. 처음 두 가지의 조합.
전제 조건.데이터는 독립적이고 정규 분포를 따릅니다. 두 정규 모집단의 분산이 동일하다는 가설은 더 큰 분산과 작은 분산의 비율이 Fisher 분포의 임계값보다 작은 경우 허용됩니다.
F P = S 1 2 /S 2 2
메모. 설명된 검증 방법을 사용하면 Fpasch 값은 반드시 1보다 커야 합니다. 기준은 정규성 가정 위반에 민감합니다.
양측 대안 S 1 2 ≠S 2 2의 경우 다음 조건이 충족되면 귀무 가설이 허용됩니다.
F l - α /2< Fрасч < F α /2
예
열물리적 매개변수는 복잡한 온도 측정 방법을 사용하여 결정되었습니다. 그린몰트의 특성(TFC). 샘플을 준비하기 위해 캐러멜 맥아 제조 신기술에 따라 공기 건조(평균 습도 W=19%) 및 습식 4일 숙성 맥아(W=45%)를 채취했습니다. 실험에 따르면 습식 맥아의 열전도도 λ는 건식 맥아보다 약 2.5배 더 높으며 체적 열용량은 맥아의 수분 함량에 명확하게 의존하지 않는 것으로 나타났습니다. 따라서 F-test를 이용하여 습도를 고려하지 않고 평균값을 기준으로 데이터를 일반화할 수 있는 가능성을 확인하였다.
계산된 데이터는 표 5.1에 요약되어 있습니다.
표 5.1
F-기준 계산을 위한 데이터
W=45%에 대해 더 큰 분산 값이 얻어졌습니다. 즉, S 2 45 = S 1 2 , S 2 19 = S 2 2 , 그리고 F P = S 1 2 /S 2 2 =1.35. γ=0.95에서 자유도 f 1 =N 1 -1=5 f 2 =N 2 -1=4에 대한 표 5.2로부터 F KR =6.2를 결정합니다. “생 맥아의 수분 함량이 19~45% 범위에서 체적 열용량에 미치는 영향은 무시될 수 있다” 또는 “S 2 45 = S 2 19”로 공식화된 귀무가설은 95%의 신뢰확률로 확인됨, Fp 이후 Excel을 사용하여 Fisher 기준을 사용하여 두 분산이 동일한 모집단에 속한다는 가설을 테스트하는 예 밀 곡물의 수분 흡수 정도에 대한 두 개의 독립적인 샘플(표 5.2)에 대한 데이터가 제공됩니다. 저주파 자기장의 영향에 대한 연구가 수행되었습니다. 표 5.2 연구결과 이러한 표본 평균의 동일성에 대한 가설을 테스트하기 전에 이를 테스트하기 위해 선택할 기준을 알기 위해 분산의 동일성에 대한 가설을 테스트해야 합니다. 그림에서. 5.1은 Microsoft Excel 소프트웨어 제품을 사용하여 Fisher 기준을 사용하여 두 분산이 동일한 모집단에 속한다는 가설을 테스트하는 예를 보여줍니다. 그림 5.1 Fisher 기준을 사용하여 두 분산이 하나의 모집단에 속하는지 테스트하는 예 원본 데이터는 C열과 D열의 3~10행이 교차하는 셀에 있습니다. 다음을 수행해 보겠습니다. 1. 첫 번째와 두 번째 표본의 분포 법칙이 정규로 간주될 수 있는지 판단해 보겠습니다(각각 C열과 D열). 그렇지 않은 경우(적어도 하나의 샘플에 대해) 비모수적 테스트를 사용해야 합니다. 그렇다면 계속합니다. 2. 첫 번째 열과 두 번째 열의 분산을 계산합니다. 이를 위해 셀 SP와 D11에 =DISP(SZ:C10) 및 =DISP(DЗ:D10) 함수를 각각 배치합니다. 이러한 함수의 결과는 각각 각 열에 대해 계산된 분산 값입니다. 3. Fisher 기준에 대해 계산된 값을 찾습니다. 이렇게 하려면 더 큰 분산을 더 작은 분산으로 나누어야 합니다. F13 셀에 이 작업을 수행하는 수식 =C11/D11을 배치합니다. 4. 등분산 가설이 받아들여질 수 있는지 여부를 결정합니다. 예제에는 두 가지 방법이 나와 있습니다. 첫 번째 방법에 따르면 유의 수준(예: 0.05)을 설정하면 이 값과 해당 자유도에 대해 Fisher 분포의 임계값이 계산됩니다. 셀 F14에 =FPACPOBP(0.05;7;7) 함수를 입력합니다. 여기서 0.05는 지정된 유의 수준이고, 7은 분자의 자유도 수이고, 7(초)은 자유도 수입니다. 분모). 자유도는 실험 횟수에서 1을 뺀 값과 같습니다. 결과는 3.787051입니다. 이 값은 계산된 값인 1.81144보다 크기 때문에 등분산 귀무가설을 받아들여야 합니다. 두 번째 옵션에 따르면, 획득된 Fisher 기준의 계산값에 대해 해당 확률이 계산됩니다. 이렇게 하려면 F15 셀에 =FPACP(F13;7;7) 함수를 입력합니다. 결과 값 0.22566이 0.05보다 크므로 등분산 가설이 채택됩니다. 이는 특별한 기능을 통해 수행될 수 있습니다. 메뉴 항목을 순차적으로 선택 서비스
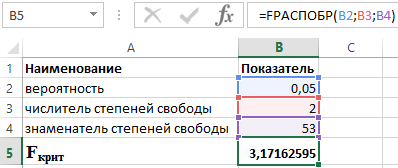
, 데이터 분석
. 다음 창이 나타납니다(그림 5.2). 그림 5.2 처리방법 선택창 이 창에서 " 분산을 위한 2-표본 F-mecm
" 결과적으로 그림과 같은 창이 나타납니다. 5.3. 여기에서는 첫 번째 변수와 두 번째 변수의 간격(셀 번호), 유의 수준(알파) 및 결과를 찾을 위치를 설정합니다. 필요한 모든 매개변수를 설정하고 확인을 클릭합니다. 작업 결과는 그림 1에 나와 있습니다. 5.4 이 함수는 일방적인 기준을 테스트하고 올바르게 수행한다는 점에 유의해야 합니다. 기준값이 1보다 큰 경우 상한임계값이 계산됩니다. 그림 5.3 매개변수 설정 창 기준 값이 1보다 작으면 하한 임계값이 계산됩니다. 기준 값이 상한 임계값보다 크거나 하한 임계값보다 작으면 분산 평등 가설이 기각된다는 점을 상기시켜 드립니다. 그림 5.4 등분산 검정 FISCHER 함수는 X에 대한 인수의 Fisher 변환을 반환합니다. 이 변환은 편향된 분포가 아닌 정규 분포를 갖는 함수를 생성합니다. FISCHER 함수는 상관계수를 사용하여 가설을 검정하는 데 사용됩니다. 이 기능을 사용할 때 변수 값을 설정해야 합니다. 이 기능이 결과를 생성하지 못하는 몇 가지 상황이 있다는 점을 즉시 언급할 가치가 있습니다. 이는 변수가 다음과 같은 경우에 가능합니다. FISCHER 함수를 수학적으로 설명하는 데 사용되는 방정식은 다음과 같습니다. Z"=1/2*ln(1+x)/(1-x) 3가지 구체적인 예를 사용하여 이 기능의 사용법을 살펴보겠습니다. 예 1. 상업 조직의 활동에 대한 데이터를 사용하여 제품 개발에 사용되는 이익 Y(백만 루블)와 비용 X(백만 루블) 간의 관계를 평가해야 합니다(표 1 참조). 표 1 – 초기 데이터: 이러한 문제를 해결하기 위한 계획은 다음과 같습니다. 이 문제를 엑셀에서 사용하는 함수로 해결한 결과는 그림 1과 같다. 그림 1 - 계산 예. 따라서 확률이 0.95인 경우 선형 상관 계수는 표준 오차가 0.205인 (-0.386)에서 (-0.990) 범위에 있습니다. 예 2. Fisher의 F 검정을 사용하여 다중 회귀 방정식의 통계적 유의성을 확인하고 결론을 도출합니다. 방정식 전체의 유의성을 확인하기 위해 결정 계수의 통계적 중요성에 대한 가설 H 0과 결정 계수의 통계적 유의성에 대한 반대 가설 H 1을 제시합니다. H1: R2 ≠ 0. Fisher의 F 테스트를 사용하여 가설을 테스트해 보겠습니다. 지표는 표 2에 나와 있습니다. 표 2 - 초기 데이터 이를 위해 Excel에서 다음 기능을 사용합니다. 더 빠르게(α;p;n-p-1) α = 0.05, p = 2, n = 53임을 알면 F crit에 대해 다음 값을 얻습니다(그림 2 참조). 그림 2 - 계산 예. 따라서 우리는 F 계산 > F 임계라고 말할 수 있습니다. 그 결과 결정계수의 통계적 유의성에 관한 가설 H1이 채택되었다. 예 3. 23개 기업의 데이터 사용: X는 제품 A의 가격, 천 루블입니다. Y는 무역 기업의 이익이며 백만 루블입니다. 회귀 모델은 다음과 같이 추정되었습니다: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. 이 데이터에서 어떤 상관관계 지표를 결정할 수 있습니까? 상관 지표의 값을 계산하고 Fisher의 테스트를 사용하여 회귀 모델의 품질에 대한 결론을 도출합니다. 다음 표현식에서 F crit을 결정해 보겠습니다. F 계산 = R 2 /23*(1-R 2) 여기서 R은 0.67과 같은 결정 계수입니다. 따라서 계산된 값 Fcalc = 46입니다. F crit를 결정하기 위해 Fisher 분포를 사용합니다(그림 3 참조). 그림 3 - 계산 예. 따라서 회귀 방정식의 결과 추정치는 신뢰할 수 있습니다. 피셔의 정확 검정은 두 가지 값을 갖는 특정 특성의 빈도를 특성화하는 두 가지 상대 지표를 비교하는 데 사용되는 기준입니다. Fisher의 정확 검정을 계산하기 위한 초기 데이터는 일반적으로 4개 필드 테이블 형식으로 그룹화됩니다. 기준이 처음 제안되었습니다. 로널드 피셔그의 저서 실험 설계에서. 이런 일이 1935년에 일어났습니다. Fischer 자신은 Muriel Bristol이 그에게 이러한 아이디어를 촉발시켰다고 주장했습니다. 1920년대 초 Ronald, Muriel 및 William Roach는 영국의 농업 실험 기지에 주둔했습니다. Muriel은 차와 우유를 컵에 붓는 순서를 결정할 수 있다고 주장했습니다. 당시에는 그녀의 진술이 사실인지 확인할 수 없었다. 이것이 피셔의 "귀무 가설"이라는 생각을 불러일으켰습니다. 목표는 Muriel이 다르게 준비된 차 한잔의 차이를 구별할 수 있다는 것을 증명하는 것이 아니었습니다. 여성이 무작위로 선택한다는 가설을 반박하기로 결정되었습니다. 귀무가설은 입증되거나 정당화될 수 없는 것으로 판단되었다. 그러나 이는 실험 중에 반박될 수 있다. 8잔을 준비했습니다. 처음 4개에는 먼저 우유를 채우고 나머지 4개에는 차로 채웁니다. 컵이 섞여 있었어요. 브리스톨은 차를 맛보고 차를 준비하는 방법에 따라 컵을 나누어 주겠다고 제안했습니다. 결과는 두 그룹이었을 것입니다. 역사는 실험이 성공했다고 말합니다. 피셔 테스트 덕분에 브리스톨이 직관적으로 행동할 확률은 0.01428로 줄어들었다. 즉, 70개 중 1개의 경우에 컵을 정확하게 식별하는 것이 가능했습니다. 하지만 그래도 마담이 우연히 결정한 확률을 0으로 줄일 수는 없습니다. 컵 수를 늘려도 마찬가지다. 이 이야기는 "귀무 가설"의 발전을 촉진했습니다. 동시에 Fisher의 정확한 기준이 제안되었으며, 그 핵심은 종속 변수와 독립 변수의 가능한 모든 조합을 열거하는 것입니다. Fisher의 정확 검정은 비교를 위해 주로 사용됩니다. 작은 샘플. 여기에는 두 가지 좋은 이유가 있습니다. 첫째, 기준 계산은 매우 번거롭고 시간이 오래 걸리거나 강력한 컴퓨팅 리소스가 필요할 수 있습니다. 둘째, 기준이 매우 정확하여(이름에도 반영됨) 관찰 횟수가 적은 연구에 사용할 수 있습니다. Fisher의 정확한 의학 테스트에는 특별한 위치가 있습니다. 이는 의료 데이터를 처리하는 중요한 방법이며 많은 과학 연구에서 적용되는 것으로 나타났습니다. 덕분에 특정 요인과 결과 사이의 관계를 연구하고, 두 대상 그룹 간의 병리학적 상태의 빈도를 비교하는 등의 작업이 가능합니다. Fisher의 정확 검정과 유사한 것은 Pearson 카이제곱 검정이며, Fisher의 정확 검정은 특히 작은 표본을 비교할 때 더 높은 검정력을 가지므로 이 경우 이점이 있습니다. 임신 중 산모의 흡연에 대한 선천성 기형(CDD) 아동의 출산 빈도 의존성을 연구하고 있다고 가정해 보겠습니다. 이를 위해 두 그룹의 임산부를 선정했는데, 그 중 하나는 임신 초기에 흡연을 한 여성 80명으로 구성된 실험그룹이고, 두 번째 그룹은 임신 전반에 걸쳐 건강한 생활방식을 유지한 여성 90명으로 구성된 비교그룹이었다. 초음파 데이터로 판단한 태아 선천기형의 경우 실험군은 10예, 비교군은 2예였다. 먼저 작곡을 해보자 4개 필드 비상표: Fisher의 정확 검정은 다음 공식을 사용하여 계산됩니다. 여기서 N은 두 그룹의 총 피험자 수입니다. ! - 팩토리얼(factorial)은 숫자와 숫자 시퀀스의 곱으로, 각 숫자는 이전 숫자보다 1씩 작습니다(예: 4! = 4 3 2 1). 계산 결과, P = 0.0137임을 알 수 있습니다. 이 방법의 장점은 결과 기준이 유의 수준의 정확한 값과 일치한다는 것입니다. 피. 즉, 본 실시예에서 얻은 0.0137의 값은 비교군 간 태아 선천기형 발생빈도의 차이에 대한 유의수준이다. 이 숫자를 의학 연구에서 일반적으로 0.05로 사용되는 중요 수준과 비교하면 됩니다. 우리의 예에서 P< 0,05, в связи с чем делаем вывод о наличии прямой взаимосвязи курения и вероятности развития ВПР плода. Частота возникновения врожденной патологии у детей курящих женщин 통계적으로 유의미하게 높은비흡연자보다 (우측) F 확률 분포의 역함수를 반환합니다. p = FRIST(x;...)이면 FRIST(p;...) = x입니다. F 분포는 두 데이터 세트의 분산 정도를 비교하는 F 테스트에 사용할 수 있습니다. 예를 들어, 미국과 캐나다의 소득 분포를 분석하여 두 국가의 소득 밀도가 유사한지 확인할 수 있습니다. 중요한:이 기능은 더 높은 정확성을 제공하고 해당 목적을 더 잘 반영하는 이름을 가진 하나 이상의 새로운 기능으로 대체되었습니다. 이 기능은 이전 버전과의 호환성을 위해 계속 사용되지만 향후 Excel 버전에서는 더 이상 사용하지 못할 수 있으므로 새로운 기능을 사용하는 것이 좋습니다. 새로운 기능에 대해 자세히 알아보려면 F.REV 기능 및 F.REV.PH 기능 문서를 참조하세요. FRIST(확률, 자유도1, 자유도2) FALTER 함수에 대한 인수는 아래에 설명되어 있습니다. 개연성- 필수 인수입니다. 누적 F 분포와 관련된 확률입니다. 자유도1- 필수 인수입니다. 자유도의 분자. 자유도2- 필수 인수입니다. 자유도의 분모입니다. 인수 중 하나라도 숫자가 아니면 FRATE는 #VALUE! 오류 값을 반환합니다. "확률"이라면< 0 или "вероятность" >1에서 FRIST 함수는 오류 값 #NUM!을 반환합니다. Degree_freedom1 또는 Degree_freedom2의 값이 정수가 아닌 경우 잘립니다. "degrees_freedom1"인 경우< 1 или "степени_свободы1" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. "degrees_freedom2"인 경우< 1 или "степени_свободы2" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!. FDIST 함수를 사용하여 F 분포의 임계값을 결정할 수 있습니다. 예를 들어, ANOVA 결과에는 일반적으로 F 통계량, F 확률 및 유의 수준 0.05에서 F 분포의 임계값에 대한 데이터가 포함됩니다. F의 임계값을 결정하려면 유의 수준을 FDIST 함수의 확률 인수로 사용해야 합니다. 확률 값이 주어지면 FDIST 함수는 FDIST(x,degrees_of_freedom1,degrees_of_freedom2) = 확률인 x 값을 검색합니다. 따라서 FDIST 함수의 정확도는 FDIST의 정확도에 따라 달라집니다. 검색을 위해 FRIST 함수는 반복 방법을 사용합니다. 100회 반복 후에도 검색이 종료되지 않으면 #N/A 오류 값이 반환됩니다. 다음 표의 샘플 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여넣습니다. 수식 결과를 표시하려면 해당 수식을 선택하고 F2를 누른 다음 Enter를 누르십시오. 필요한 경우 모든 데이터를 보려면 열 너비를 변경하세요.숫자 샘플 번호
경험
2 ,
0,027
0,075
0,036
0,4
0,1
0,08
0,12
0,105
0,32
0,075
0,45
0,12
0,049
0,06
0,105
0,075




Excel의 FISCHER 함수에 대한 설명
FISHER 함수를 이용한 이익과 비용의 관계 추정
№
엑스 와이
1
210,000,000.00 RUR 95,000,000.00 RUR
2
루블 1,068,000,000.00 76,000,000.00루피
3
루블 1,005,000,000.00 78,000,000.00루피
4
610,000,000.00 RUR 89,000,000.00 RUR
5
768,000,000.00루피 77,000,000.00루피
6
799,000,000.00 RUR 85,000,000.00루피
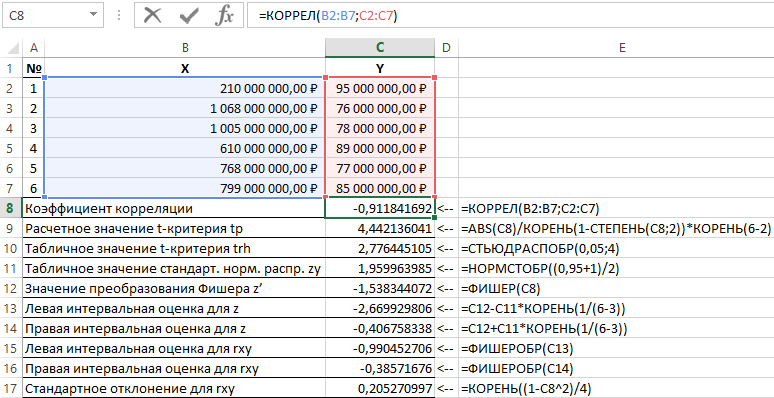
아니요. 지표 이름 계산식
1
상관 계수 =CORREL(B2:B7,C2:C7)
2
계산된 t-검정 값 tp =ABS(C8)/SQRT(1-POWER(C8,2))*SQRT(6-2)
3
t-검정 trh의 테이블 값 =스터디커버(0.05,4)
4
표준 정규 분포 zy의 테이블 값 =NORMSINV((0.95+1)/2)
5
Fisher z' 변환 값 =피셔(C8)
6
z에 대한 왼쪽 구간 추정값 =C12-C11*루트(1/(6-3))
7
z에 대한 우구간 추정 =C12+C11*루트(1/(6-3))
8
rxy의 왼쪽 간격 추정치 =피셔로브(C13)
9
rxy에 대한 올바른 간격 추정 =피셔로브(C14)
10
rxy의 표준편차 =ROOT((1-C8^2)/4)
FASTER 함수를 사용하여 회귀의 통계적 유의성 확인
Excel에서 상관관계 지표 값 계산

1. 기준 개발의 역사
2. Fisher의 정확 검정은 무엇에 사용됩니까?
3. Fisher의 정확 검정은 어떤 경우에 사용할 수 있습니까?
양측 테스트는 두 방향의 주파수 차이를 평가합니다. 즉, 대조군과 비교하여 실험군에서 현상의 빈도가 더 높고 더 낮을 가능성이 평가됩니다.4. Fisher의 정확 검정을 계산하는 방법은 무엇입니까?
5. Fisher의 정확 검정 값을 해석하는 방법은 무엇입니까?
통사론
노트
예