მოდით გავაუმჯობესოთ ჩვენი უნარები cURL-თან მუშაობისას. გადამისამართების აღმოჩენა ბრაუზერის მიხედვით
ეს სტატია დიდი ხნის წინ უნდა ყოფილიყო გადაწერილი (ძალიან ბევრი „შეჯამების დაზოგვა“), მაგრამ მე არასოდეს მიმიღია. დაე, აწონ-დაწონოს და შეგვახსენოს, როგორი სულელები ვართ ახალგაზრდობაში.
ნებისმიერი ინტერნეტ რესურსის წარმატების ერთ-ერთი მთავარი კრიტერიუმი მისი მუშაობის სისწრაფეა და ყოველწლიურად მომხმარებლები უფრო და უფრო მომთხოვნი ხდებიან ამ კრიტერიუმის თვალსაზრისით. PHP სკრიპტების მუშაობის ოპტიმიზაცია სისტემის სიჩქარის უზრუნველსაყოფად ერთ-ერთი მეთოდია.
ამ სტატიაში მინდა საზოგადოებას წარვუდგინო ჩემი რჩევები და ფაქტები სკრიპტის ოპტიმიზაციის შესახებ. ამ კრებულს საკმაოდ დიდი ხანია ვაგროვებ, რამდენიმე წყაროზეა დაფუძნებული და პირადი ექსპერიმენტები.
რატომ არის რჩევებისა და ფაქტების კრებული, ვიდრე მკაცრი წესები? რადგან, როგორც დავინახე, არ არსებობს „აბსოლუტურად სათანადო ოპტიმიზაცია" ბევრი ტექნიკა და წესი ურთიერთგამომრიცხავია და შეუძლებელია ყველა მათგანის დაცვა. თქვენ უნდა აირჩიოთ მეთოდების ნაკრები, რომლებიც მისაღები იქნება უსაფრთხოებისა და მოხერხებულობის დარღვევის გარეშე. მე დავიკავე სარეკომენდაციო პოზიცია და, შესაბამისად, მაქვს რჩევები და ფაქტები, რომლებსაც შეიძლება მიჰყვეთ ან არა.
დაბნეულობის თავიდან ასაცილებლად, ყველა რჩევა და ფაქტი დავყავი 3 ჯგუფად:
- კოდის ოპტიმიზაცია
- უსარგებლო ოპტიმიზაცია
ოპტიმიზაცია განაცხადის ლოგიკისა და ორგანიზაციის დონეზე
ამ ოპტიმიზაციის ჯგუფთან დაკავშირებული ბევრი რჩევა და ფაქტი ძალიან მნიშვნელოვანია და უზრუნველყოფს ძალიან დიდ დროს.- მუდმივად დააფიქსირეთ თქვენი კოდი სერვერზე (xdebug) და კლიენტზე (firebug) იდენტიფიცირებისთვის ბოსტნეულებიკოდი
აღსანიშნავია, რომ აუცილებელია როგორც სერვერის, ისე კლიენტის ნაწილი, რადგან არა ყველა სერვერის შეცდომებიშეგიძლიათ იპოვოთ თავად სერვერზე. - პროგრამაში გამოყენებული რაოდენობა მორგებული ფუნქციები, სიჩქარეზე არანაირად არ მოქმედებს
ეს საშუალებას აძლევს პროგრამას გამოიყენოს უამრავი მორგებული ფუნქცია. - გამოიყენეთ პერსონალური ფუნქციების აქტიური გამოყენება
დადებითი ეფექტი მიიღწევა იმის გამო, რომ ფუნქციების შიგნით ოპერაციები ხორციელდება მხოლოდ ლოკალური ცვლადებით. ამის ეფექტი უფრო მეტია, ვიდრე საბაჟო ფუნქციის გამოძახების ღირებულება. - მიზანშეწონილია „კრიტიკულად მძიმე“ ფუნქციების განხორციელება მესამე მხარის პროგრამირების ენაზე, როგორც PHP გაფართოება.
ეს მოითხოვს პროგრამირების უნარებს მესამე მხარის ენაზე, რაც მნიშვნელოვნად ზრდის განვითარების დროს, მაგრამ ამავე დროს იძლევა PHP-ის შესაძლებლობებს მიღმა ტექნიკის გამოყენების საშუალებას. - დამუშავება სტატიკური ფაილი html უფრო სწრაფია ვიდრე ინტერპრეტირებული php ფაილი
კლიენტზე დროის სხვაობა შეიძლება იყოს დაახლოებით 1 წამი, ამიტომ აზრი აქვს მკაფიოდ განვასხვავოთ სტატიკური და გენერირებული PHP-ის გამოყენებითგვერდები. - დამუშავებული (დაკავშირებული) ფაილის ზომა გავლენას ახდენს სიჩქარეზე
დაახლოებით 0,001 წამი იხარჯება ყოველ 2 კბაიტზე. ეს ფაქტი გვაიძულებს მინიმუმამდე დავიყვანოთ სკრიპტის კოდი პროდუქციის სერვერზე გადაცემისას. - ეცადეთ, მუდმივად არ გამოიყენოთ request_one ან include_one
ეს ფუნქციები უნდა იქნას გამოყენებული, როდესაც შესაძლებელია ფაილის ხელახლა წაკითხვა სხვა შემთხვევებში, მიზანშეწონილია გამოიყენოთ მოთხოვნა და შეიცავდეს . - ალგორითმის განშტოებისას, თუ არის კონსტრუქციები, რომლებიც შეიძლება არ იყოს დამუშავებული და მათი მოცულობა არის დაახლოებით 4 KB ან მეტი, მაშინ უფრო ოპტიმალურია მათი ჩართვა ჩათვლით.
- მიზანშეწონილია გამოიყენოთ კლიენტზე გაგზავნილი მონაცემების გადამოწმება
ეს გამოწვეულია იმით, რომ კლიენტის მხრიდან მონაცემების შემოწმებისას მკვეთრად მცირდება არასწორი მონაცემებით მოთხოვნის რაოდენობა. კლიენტის მხრიდან მონაცემთა ვალიდაციის სისტემები აგებულია ძირითადად JS და ხისტი ფორმის ელემენტების გამოყენებით (აირჩიეთ). - მიზანშეწონილია შექმნათ დიდი DOM სტრუქტურები კლიენტზე მონაცემთა მასივებისთვის
ეს ძალიან ეფექტური მეთოდიოპტიმიზაცია დიდი რაოდენობით მონაცემების ჩვენებასთან მუშაობისას. მისი არსი ემყარება შემდეგს: სერვერზე მზადდება მონაცემთა მასივი და გადაეცემა კლიენტს, ხოლო DOM სტრუქტურების კონსტრუქცია მიეწოდება JS ფუნქციებს. შედეგად, დატვირთვა ნაწილობრივ გადანაწილდება სერვერიდან კლიენტზე. - აგებული სისტემები AJAX ტექნოლოგიები, მნიშვნელოვნად უფრო სწრაფად, ვიდრე სისტემები, რომლებიც არ იყენებენ ამ ტექნოლოგიას
ეს გამოწვეულია გამომავალი მოცულობების შემცირებით და კლიენტზე დატვირთვის გადანაწილებით. პრაქტიკაში, AJAX-ით სისტემების სიჩქარე 2-3-ჯერ მეტია. კომენტარი: AJAX, თავის მხრივ, ქმნის უამრავ შეზღუდვას ოპტიმიზაციის სხვა მეთოდების გამოყენებაზე, მაგალითად, ბუფერთან მუშაობაზე. - პოსტის მოთხოვნის მიღებისას ყოველთვის დააბრუნეთ რაღაც, შესაძლოა სივრცეც კი
წინააღმდეგ შემთხვევაში, კლიენტს გაეგზავნება შეცდომის გვერდი, რომელიც იწონის რამდენიმე კილობაიტს. ეს შეცდომაძალიან გავრცელებულია AJAX ტექნოლოგიის გამოყენებით სისტემებში. - ფაილიდან მონაცემების მოძიება უფრო სწრაფია, ვიდრე მონაცემთა ბაზიდან
ეს დიდწილად გამოწვეულია მონაცემთა ბაზასთან დაკავშირების ღირებულებით. ჩემდა გასაკვირად, პროგრამისტების დიდი პროცენტი მანიაკალურად ინახავს ყველა მონაცემს მონაცემთა ბაზაში, მაშინაც კი, როდესაც ფაილების გამოყენება უფრო სწრაფი და მოსახერხებელია. კომენტარი:თქვენ შეგიძლიათ შეინახოთ მონაცემები ფაილებში, რომლებიც არ არის მოძიებული, წინააღმდეგ შემთხვევაში, თქვენ უნდა გამოიყენოთ მონაცემთა ბაზა. - არ დაუკავშირდეთ მონაცემთა ბაზას, თუ საჭირო არ არის
ჩემთვის უცნობი მიზეზის გამო, ბევრი პროგრამისტი უერთდება მონაცემთა ბაზას პარამეტრების წაკითხვის ეტაპზე, თუმცა მათ შეიძლება მოგვიანებით არ გაუკეთონ მოთხოვნა მონაცემთა ბაზას. ეს ცუდი ჩვევა, რომლის ღირებულება საშუალოდ 0,002 წამია. - გამოიყენეთ მუდმივი კავშირი მონაცემთა ბაზასთან, როდესაც ერთდროულად აქტიური კლიენტების მცირე რაოდენობაა
დროის სარგებელი განპირობებულია მონაცემთა ბაზასთან დაკავშირების ხარჯების ნაკლებობით. დროის სხვაობა დაახლოებით 0,002 წამია. კომენტარი:ზე დიდი რაოდენობითმომხმარებლებისთვის არ არის მიზანშეწონილი მუდმივი კავშირების გამოყენება. მუდმივ კავშირებთან მუშაობისას უნდა არსებობდეს კავშირების შეწყვეტის მექანიზმი. - მონაცემთა ბაზის რთული მოთხოვნების გამოყენება უფრო სწრაფია, ვიდრე რამდენიმე მარტივი
დროის სხვაობა მრავალ ფაქტორზეა დამოკიდებული (მონაცემთა მოცულობა, მონაცემთა ბაზის პარამეტრები და ა.შ.) და იზომება წამის მეათასედში, ზოგჯერ მეასედშიც კი. - DBMS მხარეს გამოთვლების გამოყენება უფრო სწრაფია, ვიდრე PHP მხარეს გამოთვლები მონაცემთა ბაზაში შენახული მონაცემებისთვის.
ეს გამოწვეულია იმით, რომ PHP მხარეს ასეთი გამოთვლები მოითხოვს მონაცემთა ბაზას ორ მოთხოვნას (მონაცემების მიღება და შეცვლა). დროის სხვაობა დამოკიდებულია ბევრ ფაქტორზე (მონაცემთა მოცულობა, მონაცემთა ბაზის პარამეტრები და ა.შ.) და იზომება წამის მეათასედში და მეასედში. - თუ მონაცემთა ნიმუშის მონაცემთა ბაზიდან იშვიათად იცვლება და ბევრი მომხმარებელი წვდება ამ მონაცემებს, მაშინ აზრი აქვს ნიმუშის მონაცემების ფაილში შენახვას.
მაგალითად, შეგიძლიათ გამოიყენოთ შემდეგი მარტივი მიდგომა: ჩვენ ვიღებთ მონაცემთა ნიმუშს მონაცემთა ბაზიდან და ვინახავთ მას, როგორც სერიული მასივი ფაილში, შემდეგ ნებისმიერი მომხმარებელი იყენებს მონაცემებს ფაილიდან. პრაქტიკაში, ამ ოპტიმიზაციის მეთოდს შეუძლია უზრუნველყოს სკრიპტის შესრულების სიჩქარის მრავალჯერადი ზრდა. კომენტარი:გამოყენებისას ამ მეთოდითსაჭიროა შენახულ ფაილებში მონაცემების გენერირებისა და შეცვლის ინსტრუმენტების ჩაწერა. - ქეში მონაცემები, რომლებიც იშვიათად იცვლება memcached-ით
დროის მოგება შეიძლება საკმაოდ მნიშვნელოვანი იყოს. კომენტარი:ქეშირება ეფექტურია დინამიური მონაცემებისთვის, ეფექტი შემცირებულია და შეიძლება იყოს უარყოფითი. - ობიექტების გარეშე მუშაობა (OOP-ის გარეშე) დაახლოებით სამჯერ უფრო სწრაფია, ვიდრე ობიექტებთან მუშაობა
ასევე იხარჯება მეტი მეხსიერება. სამწუხაროდ, PHP თარჯიმანი ვერ მუშაობს OOP-თან ისე სწრაფად, როგორც ჩვეულებრივი ფუნქციებით. - რაც უფრო დიდია მასივის განზომილება, მით უფრო ნელა მუშაობენ ისინი
დროის დაკარგვა ხდება წყობილი სტრუქტურების დამუშავების გამო.
კოდის ოპტიმიზაცია
ეს რჩევები და ფაქტები იძლევა სიჩქარის უმნიშვნელო მატებას წინა ჯგუფთან შედარებით, მაგრამ ერთად აღებული ამ ტექნიკებს შეუძლიათ დროის კარგი მოგება.- echo და print საგრძნობლად უფრო სწრაფია ვიდრე printf
დროის სხვაობამ შეიძლება წამის რამდენიმე მეათასედს მიაღწიოს. ეს იმიტომ ხდება, რომ printf გამოიყენება ფორმატირებული მონაცემების გამოსატანად და თარჯიმანი ამოწმებს მთელ ხაზს ასეთი მონაცემებისთვის. printf გამოიყენება მხოლოდ იმ მონაცემების გამოსატანად, რომლებსაც ფორმატირება სჭირდება. - echo $var."text" უფრო სწრაფია ვიდრე echo "$var text"
ეს იმიტომ ხდება, რომ PHP ძრავა მეორე შემთხვევაში იძულებულია მოძებნოს ცვლადები სტრიქონის შიგნით. ამისთვის დიდი მოცულობებიმონაცემები და ძველი PHP ვერსიებიდროთა განმავლობაში განსხვავებები შესამჩნევია. - echo "a" უფრო სწრაფია ვიდრე echo "a" ცვლადების გარეშე სტრიქონებისთვის
ეს იმიტომ ხდება, რომ მეორე შემთხვევაში PHP ძრავა ცდილობს ცვლადების პოვნას. დიდი მოცულობის მონაცემებისთვის, დროში განსხვავებები საკმაოდ შესამჩნევია. - echo "a", "b" უფრო სწრაფია ვიდრე echo "a"."b"
მძიმით გამოყოფილი მონაცემების გამოტანა უფრო სწრაფია, ვიდრე წერტილით. ეს იმიტომ ხდება, რომ მეორე შემთხვევაში სიმებიანი შეერთება ხდება. დიდი მოცულობის მონაცემებისთვის, დროში განსხვავებები საკმაოდ შესამჩნევია. შენიშვნა:ეს მუშაობს მხოლოდ echo ფუნქციით, რომელსაც შეუძლია მრავალი ხაზი არგუმენტად მიიღოს. - $return="a"; $return.="b"; echo $return; უფრო სწრაფი ვიდრე ექო "ა"; ექო "ბ";
მიზეზი ის არის, რომ მონაცემთა გამომავალი მოითხოვს გარკვეულ რაოდენობას დამატებითი ოპერაციები. დიდი მოცულობის მონაცემებისთვის, დროში განსხვავებები საკმაოდ შესამჩნევია. - ob_start(); ექო "ა"; ექო "ბ"; ob_end_flush(); უფრო სწრაფად ვიდრე $return="a"; $return.="b"; echo $return;
ეს იმიტომ ხდება, რომ ყველა სამუშაო კეთდება ცვლადებზე წვდომის გარეშე. დიდი მოცულობის მონაცემებისთვის, დროში განსხვავებები საკმაოდ შესამჩნევია. კომენტარი:ეს ტექნიკა არაეფექტურია, თუ თქვენ მუშაობთ AJAX-თან, რადგან ამ შემთხვევაში სასურველია მონაცემთა ერთი სტრიქონის სახით დაბრუნება. - გამოიყენეთ "პროფესიონალური ჩანართი" ან?> a b
სტატიკური მონაცემები (გარეთ პროგრამის კოდი) მუშავდება უფრო სწრაფად, ვიდრე გამომავალი PHP მონაცემები. ამ ტექნიკას პროფესიონალურ ჩასმას უწოდებენ. დიდი მოცულობის მონაცემებისთვის, დროში განსხვავებები საკმაოდ შესამჩნევია. - readfile უფრო სწრაფია ვიდრე file_get_contents, file_get_contents უფრო სწრაფია ვიდრე საჭიროა და მოთხოვნა უფრო სწრაფია ვიდრე მოიცავს ერთი ფაილიდან სტატიკური შინაარსის გამოსატანად
დროის კითხვით ცარიელი ფაილირყევები 0.001-დან readfile-მდე 0.002-მდე ჩათვლით. - მოთხოვნა უფრო სწრაფია, ვიდრე მოიცავს ინტერპრეტირებული ფაილებისთვის
კომენტარი:ალგორითმის განშტოებისას, როდესაც შესაძლებელია არ გამოიყენოთ ინტერპრეტირებული ფაილი, უნდა გამოიყენოთ ჩათვლით, რადგან მოთხოვნა ყოველთვის შეიცავს ფაილს. - თუ (...) (...) სხვა შემთხვევაში, თუ (...) () უფრო სწრაფია ვიდრე გადართვა
დრო დამოკიდებულია ფილიალების რაოდენობაზე. - თუ (...) (...) სხვა შემთხვევაში, თუ (...) () უფრო სწრაფია, ვიდრე თუ (...) (...); თუ (...) ();
დრო დამოკიდებულია ფილიალების რაოდენობასა და პირობებზე. თქვენ უნდა გამოიყენოთ სხვა, თუ ეს შესაძლებელია, რადგან ეს არის ყველაზე სწრაფი "პირობითი" კონსტრუქცია. - if (...) (...) else if (...) () კონსტრუქციის ყველაზე გავრცელებული პირობები უნდა განთავსდეს ფილიალის დასაწყისში.
თარჯიმანი ასკანირებს კონსტრუქციას ზემოდან ქვემოდან, სანამ არ აღმოაჩენს დაკმაყოფილებულ მდგომარეობას. თუ თარჯიმანი აღმოაჩენს, რომ პირობა დაკმაყოფილებულია, მაშინ ის არ უყურებს დანარჩენ კონსტრუქციას. - < x; ++$i) {...} быстрее, чем for($i = 0; $i < sizeOf($array); ++$i) {...}
ეს იმიტომ ხდება, რომ მეორე შემთხვევაში ზომაOf ოპერაცია შესრულდება ყოველი გამეორებისას. შესრულების დროის სხვაობა დამოკიდებულია მასივის ელემენტების რაოდენობაზე. - x = sizeOf($მასივი); for($i = 0; $i< x; ++$i) {...} быстрее, чем foreach($arr as $value) {...} для не ассоциативных массивов
დროის სხვაობა მნიშვნელოვანია და იზრდება მასივის მატებასთან ერთად. - preg_ ჩანაცვლება უფრო სწრაფიავიდრე ereg_replace, str_replace უფრო სწრაფია ვიდრე preg_replace, მაგრამ strtr უფრო სწრაფია ვიდრე str_replace
დროის სხვაობა დამოკიდებულია მონაცემთა რაოდენობაზე და შეიძლება მიაღწიოს წამის რამდენიმე მეათასედს. - სიმებიანი ფუნქციები უფრო სწრაფია, ვიდრე რეგულარული გამონათქვამები
ეს წესი წინა წესის შედეგია. - წაშალეთ მასივის ცვლადები, რომლებიც აღარ არის საჭირო მეხსიერების გასათავისუფლებლად.
- მოერიდეთ შეცდომის ჩახშობის გამოყენებას @
შეცდომის ჩახშობა აწარმოებს უამრავ ძალიან ნელ ოპერაციებს და ვინაიდან განმეორებითი ცდის სიჩქარე შეიძლება იყოს ძალიან მაღალი, სიჩქარის დაკარგვა შეიძლება იყოს მნიშვნელოვანი. - if (isset($str(5))) (...) უფრო სწრაფია ვიდრე if (strlen($str)>4)(...)
ეს იმიტომ ხდება, რომ strlen გამოიყენება string ფუნქციის ნაცვლად სტანდარტული ოპერაციაისეტის ჩეკები. - 0.5 უფრო სწრაფია ვიდრე 1/2
მიზეზი ისაა, რომ მეორე შემთხვევაში გაყოფის ოპერაცია ტარდება. - ფუნქციიდან ცვლადის მნიშვნელობის დაბრუნებისას დაბრუნება უფრო სწრაფია ვიდრე გლობალური
ეს იმიტომ ხდება, რომ მეორე შემთხვევაში იქმნება გლობალური ცვლადი. - $row["id"] უფრო სწრაფია ვიდრე $row
პირველი ვარიანტი 7-ჯერ უფრო სწრაფია. - $_SERVER['REQUEST_TIME'] უფრო სწრაფია ვიდრე დრო() სკრიპტის გაშვების დასადგენად
- if ($var===null) (...) უფრო სწრაფია ვიდრე თუ (is_null($var)) (...)
მიზეზი არის ის, რომ პირველ შემთხვევაში არ არის ფუნქციის გამოყენება. - ++i უფრო სწრაფია ვიდრე მე++, --მე უფრო სწრაფი ვარვიდრე მე--
ეს გამოწვეულია PHP ბირთვის მახასიათებლებით. დროის სხვაობა 0.000001-ზე ნაკლებია, მაგრამ თუ ამ პროცედურებს ათასობითჯერ გაიმეორებთ, მაშინ უფრო ახლოს დააკვირდით ამ ოპტიმიზაციას. - ინიციალიზებული ცვლადის i=0 ზრდა; ++ი; უფრო სწრაფად ვიდრე არაინიციალიზებული ++i
დროის სხვაობა არის დაახლოებით 0.000001 წამი, მაგრამ შესაძლო განმეორების სიხშირის გამო, ეს ფაქტი უნდა გახსოვდეთ. - პენსიაზე გასული ცვლადების გამოყენება უფრო სწრაფია, ვიდრე ახლის გამოცხადება
ან ნება მომეცით სხვაგვარად განვმარტო: ნუ შექმნით არასაჭირო ცვლადებს. - ლოკალურ ცვლადებთან მუშაობა დაახლოებით 2-ჯერ უფრო სწრაფია, ვიდრე გლობალურთან
მართალია დროის სხვაობა 0.000001 წამზე ნაკლებია, მაგრამ იმის გამო მაღალი სიხშირეგანმეორებით, თქვენ უნდა შეეცადოთ იმუშაოთ ადგილობრივ ცვლადებთან. - პირდაპირ ცვლადზე წვდომა უფრო სწრაფია, ვიდრე ფუნქციის გამოძახება, რომლის ფარგლებშიც ეს ცვლადი რამდენჯერმე არის განსაზღვრული
ფუნქციის გამოძახებას დაახლოებით სამჯერ მეტი დრო სჭირდება, ვიდრე ცვლადის გამოძახებას.
უსარგებლო ოპტიმიზაცია
პრაქტიკაში ოპტიმიზაციის რამდენიმე მეთოდს დიდი გავლენა არ აქვს სკრიპტის შესრულების სიჩქარეზე (დროის მომატება 0,000001 წამზე ნაკლებია). ამის მიუხედავად, ასეთი ოპტიმიზაცია ხშირად კამათის საგანია. მე მოვიყვანე ეს "უსარგებლო" ფაქტები, რათა მომავალში ყურადღება არ მიაქციოთ. განსაკუთრებული ყურადღებაკოდის დაწერისას.- ექო უფრო სწრაფია ვიდრე ბეჭდვა
- include ("აბსოლუტური გზა") უფრო სწრაფია ვიდრე მოიცავს ("შეფარდებითი გზა")
- sizeOf უფრო სწრაფია ვიდრე რაოდენობა
- foreach ($arr როგორც $key => $value) (...) უფრო სწრაფია ვიდრე გადატვირთვა ($arr); while (list($key, $value) = თითოეული ($arr)) (...) ასოციაციური მასივებისთვის
- კომენტირებული კოდი უფრო სწრაფია ვიდრე კომენტირებული კოდი, რადგან ის ტოვებს დამატებითი დროფაილის წასაკითხად
ძალიან სულელურია კომენტარების მოცულობის შემცირება ოპტიმიზაციისთვის, თქვენ უბრალოდ უნდა განახორციელოთ მინიმიზაცია სამუშაო ("საბრძოლო") სკრიპტებში. - ცვლადები ერთად მოკლე სახელებიუფრო სწრაფი ვიდრე გრძელი სახელების მქონე ცვლადები
ეს გამოწვეულია დამუშავებული კოდის რაოდენობის შემცირებით. წინა პუნქტის მსგავსად, თქვენ უბრალოდ უნდა განახორციელოთ მინიმიზაცია სამუშაო ("საბრძოლო") სკრიპტებში. - ჩანართების გამოყენებით კოდის მარკირება უფრო სწრაფია, ვიდრე სივრცეების გამოყენება
წინა პუნქტის მსგავსი.
მასალები ნაწილობრივ იქნა გამოყენებული ამ სტატიის დასაწერად.
ასე რომ, დავიწყოთ. პირველ რიგში, მოდით გადავწყვიტოთ ზუსტად რა უნდა გავაკეთოთ. როდესაც თქვენ დააწკაპუნეთ ბმულზე, ჩვენ გვჭირდება დაწკაპუნების რაოდენობის დათვლა სპეციალური სკრიპტიდათვალეთ დაწკაპუნება და შემდეგ მიაწოდეთ ვიზიტორს მისთვის საინტერესო ინფორმაცია (გადამისამართება საჭირო ფაილი). პრინციპში, თანმიმდევრობა (ინფორმაციის დაწკაპუნებით და ჩვენებით) შეიძლება შეიცვალოს, მაგრამ გაითვალისწინეთ, რომ თუ მრიცხველი გამოიყენება ფაილის ჩამოტვირთვის დასათვლელად, მაშინ იმისათვის, რომ სკრიპტი შესრულდეს ფაილის ჩამოტვირთვის შემდეგ, თქვენ უნდა დაწეროთ სპეციალური ფაილის ჩამოტვირთვის სკრიპტი. რატომ გჭირდება არასაჭირო პრობლემები? მოქმედების იგივე პრინციპი გავრცელდება ვიზიტების დახლზე. ამ შემთხვევაში, გვერდის დატვირთვის დასაჩქარებლად, შეგიძლიათ გააკეთოთ გადამისამართების გარეშე და უბრალოდ ჩადეთ მრიცხველის კოდი ჩატვირთვის გვერდზე.
როგორც ჩანს, ჩვენ გავარკვიეთ, არა? კარგი, ახლა დავიწყოთ მარტივი კოდის დაშლა ყველა ჩვენი იდეის განსახორციელებლად. მაგალითის სიმარტივისთვის და ასევე იმისთვის, რომ სკრიპტმა ნებისმიერ ჰოსტინგზე იმუშაოს, ჩვენ ვინახავთ მონაცემებს ფაილში.
$f =fopen(" stat.dat","a+"); flock($f,LOCK_EX); $count =fread($f,100); @$count++; ftruncate ($f ,0); fwrite($f,$count); flush($f); flock($f,LOCK_UN); fclose($f); |
დიახ, სწორად წაიკითხეთ, ეს არის მთელი სცენარი. ახლა მოდით გავარკვიოთ რა და როგორ მუშაობს.
კოდის პირველი ხაზი არის $f =fopen(" stat.dat","a+"); ჩვენ ვხსნით ფაილს stat.datწაკითხვისა და ჩაწერისთვის მას ვუკავშირებთ ფაილის ცვლადს $f. სწორედ ეს ფაილი შეინახავს მონაცემებს მრიცხველის მდგომარეობის შესახებ. სათანადო მუშაობისთვის, გირჩევთ, დააყენოთ წვდომის უფლებები ამ ფაილზე 777-ზე ან მსგავსზე სრული წაკითხვისა და ჩაწერის წვდომით.
შემდეგი ხაზი არის flock($f,LOCK_EX); ძალიან მნიშვნელოვანია სცენარის მუშაობისთვის. რას აკეთებს იგი? ის ბლოკავს ფაილზე წვდომას სხვა სკრიპტებისთვის ან მისი ასლებისთვის, სანამ ეს სკრიპტი მუშაობს (ან სანამ არ წაიშლება). რატომ არის ეს ასე მნიშვნელოვანი? მოდით წარმოვიდგინოთ სიტუაცია: იმ მომენტში, როდესაც user1 დააწკაპუნებს ბმულზე, რომელიც იწყებს დაწკაპუნების დათვლის სკრიპტს, user2 დააწკაპუნებს იმავე ბმულზე, ამუშავებს იმავე სკრიპტის ასლს. როგორც ქვემოთ ნახავთ, იმის მიხედვით, თუ რომელ ეტაპზეა შესრულების სკრიპტი, რომელიც გაშვებულია user1-ის მიერ, user2-ის მიერ გაშვებული სკრიპტი და მუშაობს მისი ასლის პარალელურად, შეუძლია უბრალოდ გადააყენოს მრიცხველი ნულამდე. თითქმის ყველა ახალბედა PHP პროგრამისტი უშვებს ამ შეცდომას მსგავსი მრიცხველების შექმნისას. ახლა, ვფიქრობ, გასაგებია, რატომ უნდა დავბლოკოთ ფაილზე წვდომა - in user2-ის მიერ გაშვებული სკრიპტი დაელოდება სანამ user1-ის მიერ გაშვებული სკრიპტი დასრულდება (ნუ შეგეშინდებათ, რომ ეს შეანელებს გვერდის ჩატვირთვას - ყველაზე ნელი სერვერებიც კი ასრულებენ ამ სკრიპტს წამის მეასედში).
კოდის მე-3 სტრიქონით $count =fread($f ,100); ყველაფერი ნათელია. ჩვენ ვკითხულობთ მრიცხველს $count ცვლადში.
ახლა ჩვენ უბრალოდ უნდა ჩავწეროთ განახლებული მონაცემები ფაილში.
ამისათვის ჯერ უნდა გაასუფთავოთ ფაილი ftruncate($f ,0); სწორედ აქ შეიძლება წარმოიშვას ის სახიფათო სიტუაცია მრიცხველის გადატვირთვით, რომელზეც მე ვისაუბრე. თუმცა, ჩვენ ვიყენებთ ფაილების ჩაკეტვას, ასე რომ არაფრის შეშინება არ არის.
დაწერეთ განახლებული მონაცემები მრიცხველის მნიშვნელობის შესახებ fwrite($f ,$count );
უსაფრთხოების მიზნით, ჩვენ ძალით ვასუფთავებთ I/O ბუფერს ამ ფაილის flush($f );
ამოიღეთ საკეტი ფაილის ფლოკიდან ($f ,LOCK_UN); სინამდვილეში, თქვენ არ გჭირდებათ მისი ამოღება - ის ავტომატურად წაიშლება ფაილის დახურვის შემდეგ.
თუმცა მაგალითის სისრულისთვის მაინც დავწერე. ფაილის დახურვა fclose($f );");
ასევე არ არის აუცილებელი ფუნქცია, რადგან სკრიპტის მიერ გახსნილი ყველა ფაილი, მისი დასრულების შემდეგ, ავტომატურად იხურება. მაგრამ კიდევ ერთხელ, მაგალითის სისრულისთვის... =) გარდა ამისა, თუ სკრიპტი აქ არ მთავრდება და აღარ დაგჭირდებათ ფაილთან მუშაობა, რეკომენდებულია ფაილის დაუყოვნებლივ დახურვა.
| $f =fopen(" stat.dat","a+"); flock($f,LOCK_EX); აბა, სულ ესაა. როგორც ხედავთ, ეს საერთოდ არ არის რთული. ახლა ვიზიტების რაოდენობის დასათვლელად, უბრალოდ ჩასვით ეს კოდი გვერდზე. და თუ გსურთ დათვალოთ ფაილის ჩამოტვირთვების რაოდენობა, ჩადეთ ეს კოდი ცალკე PHP ფაილში, შეცვალეთ ბმული ფაილის სახელიდან ამ სკრიპტის ბმულით და ბოლოს დაამატეთ გადამისამართება ფაილზე ჩამოსატვირთად. სცენარის. ეს საუკეთესოდ კეთდება PHP-ში: Header(" flock($f,LOCK_UN); fclose($f); ადგილმდებარეობა:/download_dir/file_to_download.rar |
ოჰ დიახ.
რატომ cURL?
სინამდვილეში, ვებ გვერდის შინაარსის ნიმუშის რამდენიმე ალტერნატიული გზა არსებობს. ხშირ შემთხვევაში, ძირითადად სიზარმაცის გამო, cURL-ის ნაცვლად ვიყენებდი მარტივ PHP ფუნქციებს:
$content = file_get_contents ("http://www.nettuts.com"); // ან $lines = ფაილი ("http://www.nettuts.com"); // ან readfile ("http://www.nettuts.com");
თუმცა, ამ ფუნქციებს პრაქტიკულად არ აქვთ მოქნილობა და შეიცავს უამრავ ხარვეზს შეცდომების დამუშავების თვალსაზრისით და ა.შ. გარდა ამისა, არის გარკვეული ამოცანები, რომლებსაც უბრალოდ ვერ შეასრულებთ ამ სტანდარტული ფუნქციებით: ქუქიების ურთიერთქმედება, ავთენტიფიკაცია, ფორმის წარდგენა, ფაილის ატვირთვა და ა.შ.
cURL არის ძლიერი ბიბლიოთეკა, რომელიც მხარს უჭერს მრავალ განსხვავებულ პროტოკოლს, ვარიანტს და უზრუნველყოფს დეტალურ ინფორმაციას URL მოთხოვნების შესახებ.
ძირითადი სტრუქტურა
- ინიციალიზაცია
- პარამეტრების მინიჭება
- შესრულება და შედეგის მიღება
- მეხსიერების გათავისუფლება
// 1. ინიციალიზაცია $ch = curl_init(); // 2. მიუთითეთ პარამეტრები, მათ შორის url curl_setopt ($ch, CURLOPT_URL, "http://www.nettuts.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_HEADER, 0); // 3. მიიღეთ HTML შედეგი $output = curl_exec($ch); // 4. დახურეთ კავშირი curl_close($ch);
ნაბიჯი #2 (ანუ curl_setopt()-ის გამოძახება) ამ სტატიაში ბევრად უფრო იქნება განხილული, ვიდრე ყველა სხვა ნაბიჯი, რადგან ამ ეტაპზე ხდება ყველა ყველაზე საინტერესო და სასარგებლო რამ, რაც უნდა იცოდეთ. cURL-ში არის უამრავი სხვადასხვა ვარიანტი, რომელიც უნდა იყოს მითითებული, რათა შესაძლებელი იყოს URL-ის მოთხოვნის კონფიგურაცია ყველაზე ფრთხილად. ჩვენ არ განვიხილავთ მთელ ჩამონათვალს, მაგრამ ყურადღებას გავამახვილებთ მხოლოდ იმაზე, რაც მე მიმაჩნია საჭიროდ და სასარგებლოდ ამ გაკვეთილისთვის. თუ ეს თემა გაინტერესებთ, შეგიძლიათ თავად შეისწავლოთ ყველაფერი.
შეცდომის შემოწმება
გარდა ამისა, თქვენ ასევე შეგიძლიათ გამოიყენოთ პირობითი განცხადებები, რათა შეამოწმოთ თუ არა ოპერაცია წარმატებით დასრულდა:
// ... $გამომავალი = curl_exec($ch); if ($output === FALSE) (echo "cURL შეცდომა: " . curl_error($ch); ) // ...
აქვე გთხოვთ, გაითვალისწინოთ ძალიან მნიშვნელოვანი პუნქტი: შედარებისთვის უნდა გამოვიყენოთ „=== false“, ნაცვლად „== false“. მათთვის, ვინც არ იცის, ეს დაგვეხმარება განვასხვავოთ ცარიელი შედეგი და ლოგიკური მნიშვნელობა false, რაც მიუთითებს შეცდომაზე.
ინფორმაციის მიღება
კიდევ ერთი დამატებითი ნაბიჯი არის cURL მოთხოვნის შესახებ მონაცემების მიღება მისი შესრულების შემდეგ.
// ... curl_exec($ch); $info = curl_getinfo ($ch); ექო "აიღო". $info["total_time"] . "წამები url-ისთვის". $info["url"]; //...
დაბრუნებული მასივი შეიცავს შემდეგ ინფორმაციას:
- "url"
- "content_type"
- "http_code"
- "header_size"
- "მოთხოვნის_ ზომა"
- "ფაილის დრო"
- „ssl_verify_result“
- „გადამისამართების_ რაოდენობა“
- „სულ_დრო“
- „namelookup_time“
- „connect_time“
- „წინასწარ გადაცემის_დრო“
- "size_upload"
- "ზომა_ჩამოტვირთვა"
- "speed_download"
- "speed_upload"
- „ჩამოტვირთვა_კონტენტის_სიგრძე“
- "ატვირთვის_შინაარსის_სიგრძე"
- „დაწყების გადაცემის დრო“
- „გადამისამართების_დრო“
გადამისამართების აღმოჩენა ბრაუზერის მიხედვით
ამ პირველ მაგალითში ჩვენ დავწერთ კოდს, რომელსაც შეუძლია URL-ის გადამისამართების აღმოჩენა ბრაუზერის სხვადასხვა პარამეტრებზე დაყრდნობით. მაგალითად, ზოგიერთი ვებსაიტი გადამისამართებს მობილური ტელეფონის ან სხვა მოწყობილობის ბრაუზერებს.
ჩვენ ვაპირებთ გამოვიყენოთ CURLOPT_HTTPHEADER ვარიანტი ჩვენი გამავალი HTTP სათაურების განსასაზღვრად, მომხმარებლის ბრაუზერის სახელისა და ხელმისაწვდომი ენების ჩათვლით. საბოლოოდ ჩვენ შევძლებთ განვსაზღვროთ რომელი საიტები გვიგზავნიან სხვადასხვა URL-ებზე.
// შეამოწმეთ URL $urls = array("http://www.cnn.com", "http://www.mozilla.com", "http://www.facebook.com"); // ბრაუზერების ტესტირება $browsers = array("სტანდარტული" => მასივი ("user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5 .6 (.NET CLR 3.5.30729)", "language" => "en-us,en;q=0.5"), "iphone" => მასივი ("user_agent" => "Mozilla/5.0 (iPhone; U ; CPU, როგორიცაა Mac OS X; ს.გ. => "Mozilla/4.0 (თავსებადი; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)", "language" => "fr,fr-FR;q=0.5")); foreach ($urls როგორც $url) ( echo "URL: $url\n"; foreach ($browsers როგორც $test_name => $browser) ($ch = curl_init(); // მიუთითეთ url curl_setopt($ch, CURLOPT_URL , $url // მიუთითეთ სათაურები ბრაუზერისთვის curl_setopt($ch, CURLOPT_HTTPHEADER, array("User-Agent: ($browser["user_agent"]), "Accept-Language: ($browser["language"]; )" )); // ჩვენ არ გვჭირდება გვერდის შინაარსი curl_setopt($ch, CURLOPT_NOBODY, 1); // ჩვენ უნდა მივიღოთ HTTP სათაურები curl_setopt($ch, CURLOPT_HEADER, 1); // შედეგების დაბრუნება curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1 $output = curl_exec($ch) იყო თუ არა HTTP გადამისამართება ("!Location: (.*)!"; , $matches) (echo "$test_name: გადამისამართდება $matches\n";) else (echo "$test_name: no redirection\n"; ) ) echo "\n\n";
პირველ რიგში, ჩვენ ვაზუსტებთ იმ საიტების URL-ების ჩამონათვალს, რომლებსაც შევამოწმებთ. უფრო ზუსტად, ჩვენ გვჭირდება ამ საიტების მისამართები. შემდეგ ჩვენ უნდა განვსაზღვროთ ბრაუზერის პარამეტრები თითოეული ამ URL-ის შესამოწმებლად. ამის შემდეგ ჩვენ გამოვიყენებთ მარყუჟს, რომელშიც გავივლით ყველა მიღებულ შედეგს.
ხრიკი, რომელსაც ამ მაგალითში ვიყენებთ cURL პარამეტრების დასაყენებლად, საშუალებას მოგვცემს მივიღოთ არა გვერდის შინაარსი, არამედ მხოლოდ HTTP სათაურები (შენახული $output-ში). შემდეგი, მარტივი რეგექსის გამოყენებით, შეგვიძლია განვსაზღვროთ, იყო თუ არა სტრიქონი „Location:“ მიღებულ სათაურებში.
ამ კოდის გაშვებისას, თქვენ უნდა მიიღოთ მსგავსი რამ:
POST მოთხოვნის შექმნა კონკრეტულ URL-ზე
GET მოთხოვნის ფორმირებისას, გადაცემული მონაცემები შეიძლება გადაეცეს URL-ს „კითხვის სტრიქონის“ მეშვეობით. მაგალითად, როდესაც თქვენ აკეთებთ Google ძიებას, საძიებო სიტყვა მოთავსებულია ახალი URL-ის მისამართების ზოლში:
Http://www.google.com/search?q=ruseller
თქვენ არ გჭირდებათ cURL-ის გამოყენება ამ მოთხოვნის სიმულაციისთვის. თუ სიზარმაცე მთლიანად დაგძლევს, შედეგის მისაღებად გამოიყენეთ ფუნქცია “file_get_contents()”.
მაგრამ საქმე ის არის, რომ ზოგიერთი HTML ფორმა აგზავნის POST მოთხოვნებს. ამ ფორმების მონაცემები ტრანსპორტირდება HTTP მოთხოვნის ორგანოში და არა როგორც წინა შემთხვევაში. მაგალითად, თუ თქვენ შეავსეთ ფორმა ფორუმზე და დააწკაპუნეთ ძებნის ღილაკზე, მაშინ, სავარაუდოდ, POST მოთხოვნა გაკეთდება:
Http://codeigniter.com/forums/do_search/
ჩვენ შეგვიძლია დავწეროთ PHP სკრიპტი, რომელსაც შეუძლია ამ ტიპის URL მოთხოვნის სიმულაცია. ჯერ შევქმნათ მარტივი ფაილი POST მონაცემების მისაღებად და საჩვენებლად. მოდით ვუწოდოთ მას post_output.php:
Print_r ($_POST);
შემდეგ ჩვენ ვქმნით PHP სკრიპტს cURL მოთხოვნის გასაკეთებლად:
$url = "http://localhost/post_output.php"; $post_data = მასივი ("foo" => "ზოლი", "query" => "Nettuts", "action" => "გაგზავნა"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // მიუთითეთ, რომ გვაქვს POST მოთხოვნა curl_setopt($ch, CURLOPT_POST, 1); // ცვლადების დამატება curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close ($ch); ექო $გამომავალი;
ამ სკრიპტის გაშვებისას თქვენ უნდა მიიღოთ ასეთი შედეგი:

ამრიგად, POST მოთხოვნა გაიგზავნა post_output.php სკრიპტზე, რომელიც თავის მხრივ გამოსცემს სუპერგლობალურ $_POST მასივს, რომლის შიგთავსი მივიღეთ cURL-ის გამოყენებით.
ფაილის ატვირთვა
პირველი, მოდით შევქმნათ ფაილი მისი გენერირების მიზნით და გავაგზავნოთ upload_output.php ფაილში:
Print_r ($_FILES);
და აქ არის სკრიპტის კოდი, რომელიც ასრულებს ზემოთ მოცემულ ფუნქციებს:
$url = "http://localhost/upload_output.php"; $post_data = მასივი ("foo" => "ზოლი", // ფაილი ასატვირთად "ატვირთვა" => "@C:/wamp/www/test.zip"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close ($ch); ექო $გამომავალი;
როდესაც გსურთ ფაილის ატვირთვა, საკმარისია გადასცეთ ის, როგორც ჩვეულებრივი პოსტის ცვლადი, რომელსაც წინ უძღვის @ სიმბოლო. დაწერილი სკრიპტის გაშვებისას მიიღებთ შემდეგ შედეგს:

მრავალი cURL
cURL-ის ერთ-ერთი ყველაზე ძლიერი მხარე არის cURL-ის "მრავალჯერადი" დამმუშავებლის შექმნის შესაძლებლობა. ეს საშუალებას გაძლევთ გახსნათ კავშირი მრავალ URL-თან ერთდროულად და ასინქრონულად.
cURL მოთხოვნის კლასიკურ ვერსიაში სკრიპტის შესრულება შეჩერებულია და ის ელოდება მოთხოვნის URL ოპერაციის დასრულებას, რის შემდეგაც სკრიპტის გაგრძელება შეიძლება. თუ თქვენ აპირებთ ინტერაქციას URL-ების მთელ ჯგუფთან, ეს გამოიწვევს დროის საკმაოდ მნიშვნელოვან ინვესტიციას, რადგან კლასიკურ ვერსიაში შეგიძლიათ ერთდროულად იმუშაოთ მხოლოდ ერთი URL-ით. თუმცა, ჩვენ შეგვიძლია გამოვასწოროთ ეს სიტუაცია სპეციალური დამმუშავებლების გამოყენებით.
მოდით გადავხედოთ php.net-დან აღებული კოდის მაგალითს:
// რამდენიმე cURL რესურსის შექმნა $ch1 = curl_init(); $ch2 = curl_init(); // მიუთითეთ URL და სხვა პარამეტრები curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/"); curl_setopt($ch1, CURLOPT_HEADER, 0); curl_setopt ($ch2, CURLOPT_URL, "http://www.php.net/"); curl_setopt($ch2, CURLOPT_HEADER, 0); //მრავალჯერადი cURL დამმუშავებლის შექმნა $mh = curl_multi_init(); //დაამატე რამდენიმე დამმუშავებელი curl_multi_add_handle($mh,$ch1); curl_multi_add_handle($mh,$ch2); $active = null; //შეასრულეთ გაკეთება ($mrc = curl_multi_exec($mh, $active); ) ხოლო ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active && $mrc == CURLM_OK) ( if (curl_multi_select($mh) != -1) (do ($mrc = curl_multi_exec($mh, $active); ) ხოლო ($mrc == CURLM_CALL_MULTI_PERFORM ) ) //curl_multi_remove_handle-ის დახურვა ($mh, $ch1); curl_multi_remove_handle($mh, $ch2); curl_multi_close ($mh);
იდეა არის ის, რომ შეგიძლიათ გამოიყენოთ მრავალი cURL დამმუშავებელი. მარტივი მარყუჟის გამოყენებით, შეგიძლიათ თვალყური ადევნოთ, რომელი მოთხოვნები ჯერ არ დასრულებულა.
ამ მაგალითში ორი ძირითადი მარყუჟია. პირველი do-while ციკლი მოუწოდებს curl_multi_exec(). ეს ფუნქცია არ არის დაბლოკილი. ის მუშაობს რაც შეიძლება სწრაფად და აბრუნებს მოთხოვნის სტატუსს. სანამ დაბრუნებული მნიშვნელობა არის მუდმივი „CURLM_CALL_MULTI_PERFORM“, ეს ნიშნავს, რომ სამუშაო ჯერ არ დასრულებულა (მაგალითად, http სათაურები ამჟამად იგზავნება URL-ზე); ამიტომ ჩვენ ვაგრძელებთ ამ დაბრუნების მნიშვნელობის შემოწმებას, სანამ არ მივიღებთ განსხვავებულ შედეგს.
შემდეგ ციკლში ჩვენ ვამოწმებთ მდგომარეობას, ხოლო ცვლადი $active = "true". ეს არის curl_multi_exec() ფუნქციის მეორე პარამეტრი. ამ ცვლადის მნიშვნელობა იქნება "true", სანამ ნებისმიერი არსებული ცვლილება აქტიურია. შემდეგ ჩვენ მოვუწოდებთ curl_multi_select() ფუნქციას. მისი შესრულება "დაბლოკილია", სანამ არის მინიმუმ ერთი აქტიური კავშირი, სანამ პასუხი არ მიიღება. როდესაც ეს მოხდება, ჩვენ ვუბრუნდებით მთავარ ციკლს, რათა გავაგრძელოთ მოთხოვნების შესრულება.
ახლა მოდით გამოვიყენოთ ეს ცოდნა მაგალითზე, რომელიც ნამდვილად გამოადგება ხალხის დიდ რაოდენობას.
ბმულების შემოწმება WordPress-ში
წარმოიდგინეთ ბლოგი დიდი რაოდენობით პოსტებითა და შეტყობინებებით, რომელთაგან თითოეული შეიცავს ბმულებს გარე ინტერნეტ რესურსებზე. ამ ბმულებიდან ზოგიერთი შეიძლება უკვე მკვდარი იყოს სხვადასხვა მიზეზის გამო. გვერდი შესაძლოა წაშლილია ან საიტი საერთოდ არ მუშაობს.
ჩვენ ვაპირებთ შევქმნათ სკრიპტი, რომელიც გააანალიზებს ყველა ბმულს და იპოვის არაჩამტვირთველ ვებსაიტებს და 404 გვერდებს, შემდეგ კი მოგვაწვდის დეტალურ ანგარიშს.
დაუყოვნებლივ გეტყვით, რომ ეს არ არის WordPress-ისთვის მოდულის შექმნის მაგალითი. ეს არის აბსოლუტურად კარგი საცდელი ადგილი ჩვენი ტესტებისთვის.
საბოლოოდ დავიწყოთ. ჯერ უნდა მოვიტანოთ ყველა ბმული მონაცემთა ბაზიდან:
// კონფიგურაცია $db_host = "localhost"; $db_user = "root"; $db_pass = ""; $db_name = "wordpress"; $excluded_domains = მასივი ("localhost", "www.mydomain.com"); $max_connections = 10; // ცვლადების ინიციალიზაცია $url_list = array(); $working_urls = მასივი(); $dead_urls = მასივი(); $not_found_urls = მასივი(); $active = null; // დაუკავშირდით MySQL-ს, თუ (!mysql_connect($db_host, $db_user, $db_pass)) ( die("დაკავშირება ვერ მოხერხდა: " . mysql_error()); ) if (!mysql_select_db($db_name)) ( die("შეუძლია არ აირჩიეთ db: " . mysql_error()); ) // აირჩიეთ ყველა გამოქვეყნებული პოსტი ბმულებით $q = "SELECT post_content FROM wp_posts WHERE post_content LIKE "%href=%" AND post_status = "publish" AND post_type = "post "" ; $r = mysql_query($q) ან die(mysql_error()); while ($d = mysql_fetch_assoc($r)) (// ბმულების მიღება რეგულარული გამონათქვამების გამოყენებით if (preg_match_all("!href=\"(.*?)\"!", $d["post_content"], $ შეესაბამება) ) ( foreach ($ შეესაბამება $url-ს) ( $tmp = parse_url($url); if (in_array($tmp["host"], $excluded_domains)) ( გაგრძელება; ) $url_list = $url; ) ) ) / / ამოიღეთ დუბლიკატები $url_list = array_values(array_unique($url_list)); if (!$url_list) ( die ("URL არ არის შესამოწმებელი"); )
ჯერ ვაგენერირებთ კონფიგურაციის მონაცემებს მონაცემთა ბაზასთან ურთიერთობისთვის, შემდეგ ვწერთ იმ დომენების სიას, რომლებიც არ მიიღებენ მონაწილეობას შემოწმებაში ($excluded_domains). ჩვენ ასევე განვსაზღვრავთ რიცხვს, რომელიც ახასიათებს მაქსიმალური ერთდროული კავშირების რაოდენობას, რომლებსაც გამოვიყენებთ ჩვენს სკრიპტში ($max_connections). შემდეგ ვუერთდებით მონაცემთა ბაზას, ვირჩევთ პოსტებს, რომლებიც შეიცავს ბმულებს და ვაგროვებთ მათ მასივში ($url_list).
შემდეგი კოდი ცოტა რთულია, ასე რომ გაიარეთ თავიდან ბოლომდე:
// 1. მრავალჯერადი დამმუშავებელი $mh = curl_multi_init(); // 2. დაამატეთ URL-ების ნაკრები ($i = 0; $i< $max_connections; $i++) { add_url_to_multi_handle($mh, $url_list); } // 3. инициализация выполнения do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 4. основной цикл while ($active && $mrc == CURLM_OK) { // 5. если всё прошло успешно if (curl_multi_select($mh) != -1) { // 6. делаем дело do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 7. если есть инфа? if ($mhinfo = curl_multi_info_read($mh)) { // это значит, что запрос завершился // 8. извлекаем инфу $chinfo = curl_getinfo($mhinfo["handle"]); // 9. мёртвая ссылка? if (!$chinfo["http_code"]) { $dead_urls = $chinfo["url"]; // 10. 404? } else if ($chinfo["http_code"] == 404) { $not_found_urls = $chinfo["url"]; // 11. рабочая } else { $working_urls = $chinfo["url"]; } // 12. чистим за собой curl_multi_remove_handle($mh, $mhinfo["handle"]); // в случае зацикливания, закомментируйте данный вызов curl_close($mhinfo["handle"]); // 13. добавляем новый url и продолжаем работу if (add_url_to_multi_handle($mh, $url_list)) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } } } // 14. завершение curl_multi_close($mh); echo "==Dead URLs==\n"; echo implode("\n",$dead_urls) . "\n\n"; echo "==404 URLs==\n"; echo implode("\n",$not_found_urls) . "\n\n"; echo "==Working URLs==\n"; echo implode("\n",$working_urls); function add_url_to_multi_handle($mh, $url_list) { static $index = 0; // если у нас есть ещё url, которые нужно достать if ($url_list[$index]) { // новый curl обработчик $ch = curl_init(); // указываем url curl_setopt($ch, CURLOPT_URL, $url_list[$index]); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_NOBODY, 1); curl_multi_add_handle($mh, $ch); // переходим на следующий url $index++; return true; } else { // добавление новых URL завершено return false; } }
აქ შევეცდები დეტალურად აგიხსნათ ყველაფერი. სიაში ნომრები შეესაბამება კომენტარში მოცემულ ნომრებს.
- 1. მრავალჯერადი დამმუშავებლის შექმნა;
- 2. add_url_to_multi_handle() ფუნქციას ცოტა მოგვიანებით დავწერთ. ყოველ ჯერზე დარეკვისას დაიწყება ახალი url-ის დამუშავება. თავდაპირველად ვამატებთ 10 ($max_connections) URL-ს;
- 3. დასაწყებად უნდა გავუშვათ curl_multi_exec() ფუნქცია. სანამ ის დააბრუნებს CURLM_CALL_MULTI_PERFORM-ს, ჩვენ ჯერ კიდევ გვაქვს გასაკეთებელი. ეს ძირითადად კავშირების შესაქმნელად გვჭირდება;
- 4. შემდეგ მოდის მთავარი ციკლი, რომელიც იმუშავებს მანამ, სანამ გვექნება მინიმუმ ერთი აქტიური კავშირი;
- 5. curl_multi_select() ჩერდება URL ძიების დასრულებას;
- 6. კიდევ ერთხელ, ჩვენ უნდა ვაიძულებთ cURL-ს გარკვეული სამუშაოს შესრულებას, კერძოდ, დაბრუნების პასუხის მონაცემების მოძიებას;
- 7. ინფორმაცია აქ გადამოწმებულია. მოთხოვნის შესრულების შედეგად მასივი დაბრუნდება;
- 8. დაბრუნებული მასივი შეიცავს cURL დამმუშავებელს. ჩვენ მას გამოვიყენებთ ცალკე cURL მოთხოვნის შესახებ ინფორმაციის შესარჩევად;
- 9. თუ ბმული მკვდარი იყო, ან სკრიპტის დრო ამოიწურა, მაშინ არ უნდა ვეძებოთ რაიმე http კოდი;
- 10. თუ ლინკმა დაგვიბრუნა 404 გვერდი, მაშინ http კოდი შეიცავს 404 მნიშვნელობას;
- 11. წინააღმდეგ შემთხვევაში, ჩვენ წინ გვაქვს სამუშაო ბმული. (შეგიძლიათ დაამატოთ დამატებითი შემოწმებები შეცდომის კოდისთვის 500 და ა.შ.);
- 12. შემდეგ ჩვენ ვხსნით cURL დამმუშავებელს, რადგან ის აღარ გვჭირდება;
- 13. ახლა შეგვიძლია დავამატოთ კიდევ ერთი url და გავუშვათ ყველაფერი, რაზეც ადრე ვისაუბრეთ;
- 14. ამ ეტაპზე სკრიპტი ასრულებს თავის სამუშაოს. ჩვენ შეგვიძლია წავშალოთ ყველაფერი, რაც არ გვჭირდება და შევქმნათ ანგარიში;
- 15. ბოლოს დავწერთ ფუნქციას, რომელიც დაამატებს url-ს დამმუშავებელს. სტატიკური ცვლადი $index გაიზრდება ყოველ ჯერზე ამ ფუნქციის გამოძახებისას.
მე გამოვიყენე ეს სკრიპტი ჩემს ბლოგზე (ზოგიერთი გატეხილი ლინკით, რომლებიც განზრახ დავამატე მის შესამოწმებლად) და მივიღე შემდეგი შედეგი:

ჩემს შემთხვევაში, სკრიპტს 2 წამზე ცოტა ნაკლები დასჭირდა 40 URL-ის გადასინჯვას. შესრულების ზრდა მნიშვნელოვანია კიდევ უფრო მეტ URL-თან მუშაობისას. თუ ერთდროულად გახსნით ათ კავშირს, სკრიპტს შეუძლია ათჯერ უფრო სწრაფად შეასრულოს.
რამდენიმე სიტყვა სხვა სასარგებლო cURL ვარიანტების შესახებ
HTTP ავთენტიფიკაცია
თუ URL-ს აქვს HTTP ავთენტიფიკაცია, მაშინ მარტივად შეგიძლიათ გამოიყენოთ შემდეგი სკრიპტი:
$url = "http://www.somesite.com/members/"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // მიუთითეთ მომხმარებლის სახელი და პაროლი curl_setopt($ch, CURLOPT_USERPWD, "myusername:mypassword"); // თუ გადამისამართება დასაშვებია curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // შემდეგ შეინახეთ ჩვენი მონაცემები cURL curl_setopt ($ch, CURLOPT_UNRESTRICTED_AUTH, 1); $output = curl_exec($ch); curl_close ($ch);
FTP ატვირთვა
PHP-ს ასევე აქვს ბიბლიოთეკა FTP-თან მუშაობისთვის, მაგრამ არაფერი გიშლით ხელს აქ cURL ინსტრუმენტების გამოყენებაში:
// გახსენით ფაილი $file = fopen("/path/to/file", "r"); // url უნდა შეიცავდეს შემდეგ შინაარსს $url = "ftp://username: [ელფოსტა დაცულია]:21/გზა/ახალი/ფაილი"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_UPLOAD, 1); curl_setopt($ch, CURLOPT_INFILE, $fp curl_setopt($ch, CURLOPT_INFILESIZE, ფაილის ზომა("/path/to/file") curl_close($ch);
პროქსის გამოყენება
თქვენ შეგიძლიათ შეასრულოთ თქვენი URL მოთხოვნა პროქსის მეშვეობით:
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://www.example.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // მიუთითეთ მისამართი curl_setopt($ch, CURLOPT_PROXY, "11.11.11.11:8080"); // თუ გჭირდებათ მომხმარებლის სახელი და პაროლი curl_setopt($ch, CURLOPT_PROXYUSERPWD,"user:pass"); $output = curl_exec($ch); curl_close ($ch);
გამოძახების ფუნქციები
ასევე შესაძლებელია მიუთითოთ ფუნქცია, რომელიც ამოქმედდება cURL მოთხოვნის დასრულებამდეც კი. მაგალითად, სანამ საპასუხო კონტენტი იტვირთება, შეგიძლიათ დაიწყოთ მონაცემების გამოყენება სრულად ჩატვირთვის მოლოდინის გარეშე.
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://net.tutsplus.com"); curl_setopt($ch, CURLOPT_WRITEFUNCTION,"პროგრესი_ფუნქცია"); curl_exec ($ch); curl_close ($ch); ფუნქცია progress_function($ch,$str) (echo $str; return strlen($str); )
მსგავსმა ფუნქციამ უნდა დააბრუნოს სტრიქონის სიგრძე, რაც სავალდებულოა.
დასკვნა
დღეს ჩვენ ვისწავლეთ, თუ როგორ შეგიძლიათ გამოიყენოთ cURL ბიბლიოთეკა თქვენი ეგოისტური მიზნებისთვის. იმედი მაქვს მოგეწონათ ეს სტატია.
გმადლობთ! სასიამოვნო დღეს გისურვებთ!
გაუშვით გადმოწერილი ფაილი ორმაგი დაწკაპუნებით (თქვენ უნდა გქონდეთ ვირტუალური მანქანა).
3. ანონიმურობა SQL ინექციისთვის საიტის შემოწმებისას
Tor და Privoxy-ის დაყენება Kali Linux-ში
[განყოფილება დამუშავების პროცესშია]
Windows-ზე Tor-ისა და Privoxy-ის დაყენება
[განყოფილება დამუშავების პროცესშია]
პროქსის პარამეტრები jSQL Injection-ში
[განყოფილება დამუშავების პროცესშია]
4. საიტის შემოწმება SQL ინექციისთვის jSQL Injection-ით
პროგრამასთან მუშაობა ძალიან მარტივია. უბრალოდ შეიყვანეთ ვებსაიტის მისამართი და დააჭირეთ ENTER.
შემდეგი სკრინშოტი აჩვენებს, რომ საიტი დაუცველია SQL-ის სამი ტიპის ერთდროულად (მათ შესახებ ინფორმაცია მითითებულია ქვედა მარჯვენა კუთხეში). ინექციების სახელებზე დაწკაპუნებით, შეგიძლიათ შეცვალოთ გამოყენებული მეთოდი:

ასევე, ჩვენთან უკვე ნაჩვენებია არსებული მონაცემთა ბაზები.
თქვენ შეგიძლიათ ნახოთ თითოეული ცხრილის შინაარსი:

როგორც წესი, ყველაზე საინტერესო ცხრილების შესახებ არის ადმინისტრატორის რწმუნებათა სიგელები.
თუ გაგიმართლათ და იპოვნეთ ადმინისტრატორის მონაცემები, მაშინ ძალიან ადრეა გახარება. თქვენ კვლავ უნდა იპოვოთ ადმინისტრატორის პანელი, სადაც უნდა შეიყვანოთ ეს მონაცემები.
5. მოძებნეთ ადმინისტრაციული პანელები jSQL ინექციით
ამისათვის გადადით შემდეგ ჩანართზე. აქ ჩვენ მივესალმებით შესაძლო მისამართების სიას. თქვენ შეგიძლიათ აირჩიოთ ერთი ან მეტი გვერდი შესამოწმებლად:

მოხერხებულობა მდგომარეობს იმაში, რომ თქვენ არ გჭირდებათ სხვა პროგრამების გამოყენება.
სამწუხაროდ, არც თუ ისე ბევრი უყურადღებო პროგრამისტია, რომლებიც პაროლებს ინახავენ წმინდა ტექსტში. ხშირად პაროლის ხაზში ჩვენ ვხედავთ რაღაცას
8743b52063cd84097a65d1633f5c74f5
ეს არის ჰაში. მისი გაშიფვრა შეგიძლიათ უხეში ძალის გამოყენებით. და... jSQL Injection-ს აქვს ჩაშენებული უხეში ფორსერი.
6. უხეში ძალის ჰეშები jSQL ინექციის გამოყენებით
უდავო მოხერხებულობა ის არის, რომ თქვენ არ გჭირდებათ სხვა პროგრამების ძებნა. არსებობს მრავალი ყველაზე პოპულარული ჰეშის მხარდაჭერა.
ეს არ არის საუკეთესო ვარიანტი. იმისათვის, რომ გახდეთ გურუ ჰეშების გაშიფვრაში, რეკომენდებულია წიგნი "" რუსულ ენაზე.
მაგრამ, რა თქმა უნდა, როდესაც ხელთ არ არის სხვა პროგრამა ან დრო არ არის შესწავლისთვის, jSQL Injection ჩაშენებული უხეში ძალის ფუნქციით ძალიან გამოდგება.

არის პარამეტრები: შეგიძლიათ დააყენოთ რომელი სიმბოლოები შედის პაროლში, პაროლის სიგრძის დიაპაზონი.
7. ფაილის ოპერაციები SQL ინექციების გამოვლენის შემდეგ
მონაცემთა ბაზებთან ოპერაციების გარდა - მათი წაკითხვა და შეცვლა, თუ SQL ინექციები აღმოჩენილია, შეიძლება შესრულდეს შემდეგი ფაილური ოპერაციები:
- სერვერზე ფაილების კითხვა
- სერვერზე ახალი ფაილების ატვირთვა
- ჭურვების სერვერზე ატვირთვა
და ეს ყველაფერი დანერგილია jSQL Injection-ში!
არსებობს შეზღუდვები - SQL სერვერს უნდა ჰქონდეს ფაილის პრივილეგიები. ჭკვიანი სისტემის ადმინისტრატორებს ისინი გამორთული აქვთ და ვერ შეძლებენ ფაილურ სისტემაზე წვდომას.
ფაილის პრივილეგიების არსებობა საკმაოდ მარტივი შესამოწმებელია. გადადით ერთ-ერთ ჩანართზე (ფაილების კითხვა, ჭურვის შექმნა, ახალი ფაილის ატვირთვა) და შეეცადეთ შეასრულოთ ერთ-ერთი მითითებული ოპერაცია.
კიდევ ერთი ძალიან მნიშვნელოვანი შენიშვნა - ჩვენ უნდა ვიცოდეთ ფაილის ზუსტი აბსოლუტური გზა, რომლითაც ვიმუშავებთ - წინააღმდეგ შემთხვევაში არაფერი გამოვა.
შეხედეთ შემდეგ ეკრანის სურათს:
 ფაილზე მუშაობის ნებისმიერ მცდელობაზე, ჩვენ ვიღებთ შემდეგ პასუხს: არ არის FILE პრივილეგია(ფაილის პრივილეგიები არ არის). და აქ არაფერი შეიძლება გაკეთდეს.
ფაილზე მუშაობის ნებისმიერ მცდელობაზე, ჩვენ ვიღებთ შემდეგ პასუხს: არ არის FILE პრივილეგია(ფაილის პრივილეგიები არ არის). და აქ არაფერი შეიძლება გაკეთდეს.
თუ ამის ნაცვლად გაქვთ სხვა შეცდომა:
[directory_name]-ში ჩაწერის პრობლემა
ეს ნიშნავს, რომ თქვენ არასწორად მიუთითეთ აბსოლუტური გზა, სადაც გსურთ ფაილის ჩაწერა.
იმისათვის, რომ გამოიცნოთ აბსოლუტური გზა, თქვენ უნდა იცოდეთ მინიმუმ ოპერაციული სისტემა, რომელზეც მუშაობს სერვერი. ამისათვის გადადით ქსელის ჩანართზე.
ასეთი ჩანაწერი (ხაზი Win64) გვაძლევს საფუძველს ვივარაუდოთ, რომ საქმე გვაქვს Windows OS-თან:
Keep-Alive: timeout=5, max=99 სერვერი: Apache/2.4.17 (Win64) PHP/7.0.0RC6 კავშირი: Keep-Alive მეთოდი: HTTP/1.1 200 OK Content-Length: 353 თარიღი: პარასკევი, 115 დეკ. 11:48:31 GMT X-Powered-By: PHP/7.0.0RC6 Content-Type: text/html; charset=UTF-8
აქ გვაქვს რამდენიმე Unix (*BSD, Linux):
გადაცემის დაშიფვრა: დაქუცმაცებული თარიღი: პარასკევი, 11 დეკ. 2015 11:57:02 GMT მეთოდი: HTTP/1.1 200 OK Keep-Alive: timeout=3, max=100 კავშირი: keep-alive Content-Type: text/html X- უზრუნველყოფილია: PHP/5.3.29 სერვერი: Apache/2.2.31 (Unix)
და აქ გვაქვს CentOS:
მეთოდი: HTTP/1.1 200 OK იწურება: ხუთ, 19 ნოემბერი 1981 08:52:00 GMT Set-cookie: PHPSESSID=9p60gtunrv7g41iurr814h9rd0; path=/ კავშირი: keep-alive X-Cache-Lookup: MISS t1.hoster.ru:6666 სერვერი: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.4.37 X-Cache: MISS-დან t1.hoster.ru Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 პრაგმა: ქეშის გარეშე თარიღი: პარასკე, 11 დეკემბერი 2015 12:08:54 GMT გადაცემის კოდირება: დაქუცმაცებული კონტენტი-ტიპი: ტექსტი/html; charset=WINDOWS-1251
Windows-ზე, საიტებისთვის ტიპიური საქაღალდეა C:\Server\data\htdocs\. მაგრამ, სინამდვილეში, თუ ვინმეს "უფიქრია" სერვერის გაკეთება Windows-ზე, მაშინ, დიდი ალბათობით, ამ ადამიანს არაფერი სმენია პრივილეგიების შესახებ. ამიტომ, თქვენ უნდა დაიწყოთ ცდა პირდაპირ C:/Windows/ დირექტორიადან:
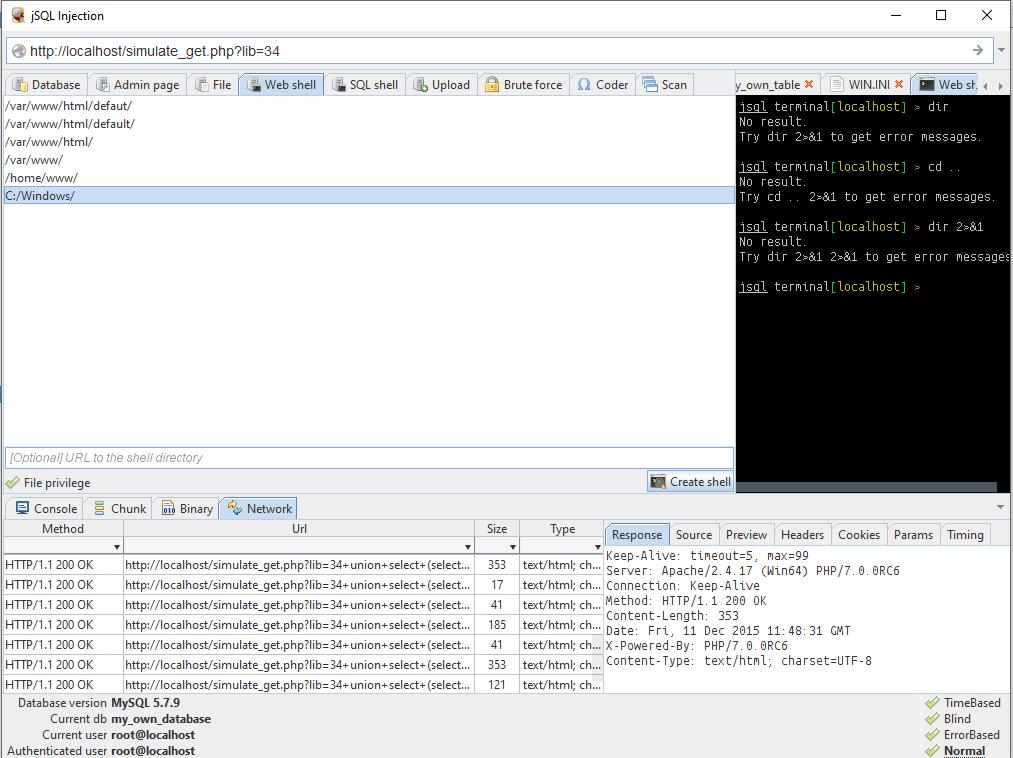
როგორც ხედავთ, პირველად ყველაფერი კარგად იყო.
მაგრამ თავად jSQL Injection ჭურვები ჩემს გონებაში ეჭვებს იწვევს. თუ თქვენ გაქვთ ფაილის პრივილეგიები, მაშინ მარტივად შეგიძლიათ ატვირთოთ რაიმე ვებ ინტერფეისით.
8. საიტების მთლიანი შემოწმება SQL ინექციებისთვის
და ეს ფუნქციაც კი ხელმისაწვდომია jSQL Injection-ში. ყველაფერი ძალიან მარტივია - ჩამოტვირთეთ საიტების სია (შეიძლება იმპორტირებული იყოს ფაილიდან), შეარჩიეთ ის, რისი შემოწმებაც გსურთ და დააჭირეთ შესაბამის ღილაკს ოპერაციის დასაწყებად.

დასკვნა jSQL ინექციიდან
jSQL Injection არის კარგი, ძლიერი ინსტრუმენტი ვებსაიტებზე ნაპოვნი SQL ინექციების მოსაძიებლად და შემდეგ გამოსაყენებლად. მისი უდავო უპირატესობები: გამოყენების სიმარტივე, ჩაშენებული დაკავშირებული ფუნქციები. jSQL Injection შეიძლება იყოს დამწყებთათვის საუკეთესო მეგობარი ვებსაიტების ანალიზისას.
ნაკლოვანებებს შორის აღვნიშნავდი მონაცემთა ბაზების რედაქტირების შეუძლებლობას (ყოველ შემთხვევაში მე ვერ ვიპოვე ეს ფუნქცია). როგორც ყველა GUI ინსტრუმენტს, ამ პროგრამის ერთ-ერთი მინუსი შეიძლება მივაწეროთ სკრიპტებში გამოყენების უუნარობას. მიუხედავად ამისა, ამ პროგრამაში ასევე შესაძლებელია გარკვეული ავტომატიზაცია - საიტის მასიური შემოწმების ჩაშენებული ფუნქციის წყალობით.
jSQL Injection პროგრამა ბევრად უფრო მოსახერხებელია გამოსაყენებლად, ვიდრე sqlmap. მაგრამ sqlmap მხარს უჭერს SQL ინექციების უფრო მეტ ტიპს, აქვს ფაილების ბუხართან მუშაობის ვარიანტები და სხვა ფუნქციები.
დედააზრი: jSQL Injection არის დამწყები ჰაკერების საუკეთესო მეგობარი.
ამ პროგრამის დახმარება Kali Linux ენციკლოპედიაში შეგიძლიათ იხილოთ ამ გვერდზე: http://kali.tools/?p=706