გამოიყენეთ Intel® არქიტექტურის ტექნიკის შესაძლებლობები NFV-ში მაღალი შესრულების მისაღწევად. Intel AVX2-ის გამოყენება ვექტორული დამუშავებისთვის
იმსახურებს თუ არა ჰასველის არქიტექტურას ეწოდოს ახალი და გადაკეთებული?
ხუთ წელზე მეტი ხნის განმავლობაში, Intel მიჰყვება ტიკ-ტაკის სტრატეგიას, ცვლის კონკრეტული არქიტექტურის უფრო დახვეწილ ტექნოლოგიურ ნორმებზე გადასვლას ახალი არქიტექტურის გამოშვებით.
შედეგად, ყოველწლიურად ვიღებთ ან ახალ არქიტექტურას ან ახალ ტექნიკურ პროცესზე გადასვლას. "ასე" დაიგეგმა 2013 წელს, ანუ ახალი არქიტექტურის - ჰასველის გამოშვება. ახალი არქიტექტურის მქონე პროცესორები იწარმოება იგივე პროცესის ტექნოლოგიის გამოყენებით, როგორც წინა თაობის Ivy Bridge: 22 ნმ, Tri-gate. ტექნიკური პროცესი არ შეცვლილა, მაგრამ გაიზარდა ტრანზისტორების რაოდენობა, რაც იმას ნიშნავს, რომ გაიზარდა ახალი პროცესორის ბროლის საბოლოო ფართობიც - და ამის შემდეგ, ენერგიის მოხმარება.
ტრადიციების დაცვით, Intel-მა წარმოადგინა მხოლოდ პროდუქტიული და ძვირადღირებული პროცესორები ძირითადი ხაზები i5 და i7. ანონსი ორბირთვიანი პროცესორებიუმცროსი ხაზები, როგორც ყოველთვის, დაგვიანებულია. აღსანიშნავია, რომ ახალი პროცესორების ფასები იგივე დონეზე დარჩა აივის ხიდი.
მოდით შევადაროთ ოთხბირთვიანი პროცესორების სხვადასხვა თაობის ზონები:
როგორც ხედავთ, ოთხბირთვიან ჰასველს აქვს მხოლოდ 177 მმ² ფართობი, ხოლო ჩრდილოეთ ხიდი, ოპერატიული მეხსიერების კონტროლერი და გრაფიკული ბირთვი მასშია ინტეგრირებული. ამრიგად, ტრანზისტორების რაოდენობა გაიზარდა 200 მილიონით, ხოლო ფართობი გაიზარდა 17 მმ²-ით. თუ ჰესველს შევადარებთ 32 ნმ ქვიშის ხიდს, მაშინ ტრანზისტორების რაოდენობა გაიზარდა 440 მილიონით (38%), ხოლო 22 ნმ პროცესის ტექნოლოგიაზე გადასვლის გამო ფართობი შემცირდა 39 მმ²-ით (18%). სითბოს გაფრქვევა თითქმის იგივე დონეზე რჩებოდა მთელი ამ წლების განმავლობაში (95 W SB-სთვის და 84 W Haswell-ისთვის) და ფართობი შემცირდა.
ამ ყველაფერმა გამოიწვია ის, რომ მეტი სითბო უნდა მოიხსნას კრისტალის ყოველი კვადრატული მილიმეტრიდან. თუ ადრე 216 მმ²-დან საჭირო იყო 95 ვტ, ანუ 0,44 ვტ/მმ² აღება, ახლა 177 მმ² ფართობიდან აუცილებელია 84 ვტ - 0,47 ვტ/მმ², რაც 6,8%-ით მეტია, ვიდრე ადრე. . თუ ეს ტენდენცია გაგრძელდება, მალე უბრალოდ ფიზიკურად რთული იქნება სითბოს ამოღება ასეთი პატარა ადგილებიდან.
წმინდა თეორიულად შეგვიძლია ვივარაუდოთ, რომ თუ ბროდველში, რომელიც წარმოიქმნება 14 ნმ პროცესის ტექნოლოგიის გამოყენებით, ტრანზისტორების რაოდენობა გაიზრდება 21%-ით, როგორც 32-დან 22 ნმ-მდე გადასვლისას და ფართობი შემცირდება 26-ით. % (იმავე რაოდენობით, როგორც 32-დან 22 ნმ-მდე გადაადგილებისას), ვიღებთ 1,9 მილიარდ ტრანზისტორს 131 მმ² ფართობზე. თუ სითბოს გაფრქვევაც იკლებს 19%-ით, მაშინ მივიღებთ 68 ვტ, ანუ 0,52 ვტ/მმ².
ეს თეორიული გამოთვლებიპრაქტიკაში სხვაგვარად იქნება - ტექნოლოგიური პროცესის 32-დან 22 ნმ-ზე გადასვლა ასევე აღინიშნა 3D ტრანზისტორების შემოღებით, რამაც შეამცირა გაჟონვის დენები და მათთან ერთად სითბოს წარმოქმნა. თუმცა, მსგავსი არაფერი მსმენია 22 ნმ-დან 14 ნმ-ზე გადასვლის შესახებ, ასე რომ, პრაქტიკაში სითბოს გაფრქვევის მნიშვნელობები, სავარაუდოდ, კიდევ უფრო უარესი იქნება და 0,52 ვტ/მმ²-ის იმედი არ უნდა გქონდეთ. თუმცა, მაშინაც კი, თუ სითბოს გაფრქვევის დონე არის 0,52 ვტ/მმ², ადგილობრივი გადახურების პრობლემა და სითბოს მოცილების სირთულე. პატარა კრისტალიკიდევ უფრო გაუარესდება.
სხვათა შორის, სწორედ სითბოს გაფრქვევასთან დაკავშირებული სირთულეები სითბოს გაფრქვევის დონით 0,52 ვტ/მმ² შეიძლება ეფუძნებოდეს Intel-ის სურვილს გადაერთოს BGA-ზე ან მცდელობა გააუქმოს სოკეტი. თუ პროცესორი დამაგრებულია დედაპლატზე, მაშინ სითბო პირდაპირ გადაეცემა ჩიპიდან გამათბობელში შუალედური საფარის გარეშე. ეს კიდევ უფრო აქტუალური ჩანს საფარის ქვეშ შედუღების თერმული პასტით ჩანაცვლების ფონზე თანამედროვე პროცესორები. ჩვენ კვლავ შეგვიძლია ველოდოთ "შიშველი" პროცესორების გამოჩენას ღია კრისტალებით Athlon XP-ის მაგალითზე, ანუ საფარის გარეშე, როგორც შუალედური რგოლი გამათბობელში.
ეს უკვე დიდი ხანია კეთდება ვიდეო ბარათებზე და ბროლის დაჭყლეტის საშიშროებას ირგვლივ რკინის ჩარჩო არბილებს, რის გამოც ვიდეო ბარათებს არ აქვთ ასეთი ” მიმდინარე პრობლემები", როგორც თერმული პასტა პროცესორის საფარის ქვეშ. თუმცა, ოვერკლიკინგი კიდევ უფრო გართულდება და სათანადო გაგრილება"თხელი" პროცესორები თითქმის მეცნიერებაა. და ეს ყველაფერი ძალიან მალე გველოდება, თუ, რა თქმა უნდა, სასწაული არ მოხდება...
ოღონდ, მოდი დედამიწაზე ჩამოვიდეთ და დავუბრუნდეთ საუბარს ჰესველზე. როგორც ვიცით, ჰესველმა მიიღო მთელი რიგი „გაუმჯობესებები/ცვლილებები“ სენდი ბრიჯთან მიმართებაში (და, შესაბამისად, აივი ხიდი, რომელიც, ზოგადად, იყო SB-ის გადატანა უფრო დახვეწილ ტექნიკურ პროცესზე):
- ჩაშენებული ძაბვის რეგულატორი;
- ენერგიის დაზოგვის ახალი რეჟიმები;
- ბუფერების და რიგების მოცულობის გაზრდა;
- ქეშის ტევადობის გაზრდა;
- გაშვების პორტების რაოდენობის გაზრდა;
- ინტეგრირებულ გრაფიკულ ბირთვში ახალი ბლოკების, ფუნქციების, API-ების დამატება;
- გრაფიკულ ბირთვში მილსადენების რაოდენობის გაზრდა.
ამრიგად, ახალი პლატფორმის მიმოხილვა შეიძლება დაიყოს სამ ნაწილად: პროცესორი, ინტეგრირებული გრაფიკული ამაჩქარებელი, ჩიპსეტი.
პროცესორის ნაწილი
პროცესორში ცვლილებები მოიცავს ახალი ინსტრუქციების დამატებას და ენერგიის დაზოგვის ახალ რეჟიმებს, ძაბვის რეგულატორის ჩართვას, ასევე თავად პროცესორის ბირთვის ცვლილებებს.
ინსტრუქციის ნაკრები
ჰასველის არქიტექტურა წარმოგიდგენთ ახალ ინსტრუქციებს. ისინი შეიძლება დაიყოს ორ დიდ ჯგუფად: ვექტორული მუშაობის გაზრდისკენ მიმართული და სერვერის სეგმენტისკენ მიმართული. პირველში შედის AVX და FMA3, მეორე - ვირტუალიზაცია და ტრანზაქციის მეხსიერება.
გაფართოებული ვექტორული გაფართოებები 2 (AVX2)
AVX კომპლექტი გაფართოვდა AVX 2.0 ვერსიამდე. AVX2 ნაკრები გთავაზობთ:
- 256-ბიტიანი მთელი ვექტორების მხარდაჭერა (ადრე მხოლოდ 128-ბიტიანი იყო);
- შეგროვების ინსტრუქციების მხარდაჭერა, რომელიც აშორებს მეხსიერებაში მომიჯნავე მონაცემთა მდებარეობის მოთხოვნას; მონაცემები ახლა "შეგროვებულია". სხვადასხვა მისამართებიმეხსიერება - საინტერესო იქნება, თუ როგორ მოქმედებს ეს შესრულებაზე;
- ბიტებზე მანიპულირების/ოპერაციების ინსტრუქციების დამატება.
საერთოდ, ახალი ნაკრებიუფრო მეტია ორიენტირებული მთელი რიცხვების არითმეტიკაზე და AVX 2.0-ის მთავარი სარგებელი მხოლოდ მთელი რიცხვის ოპერაციებში იქნება ხილული.
შერწყმული გამრავლება-დამატება (FMA3)
FMA არის კომბინირებული გამრავლება-დამატების ოპერაცია, რომელშიც ორი რიცხვი მრავლდება და ემატება აკუმულატორს. ამ ტიპისოპერაციები საკმაოდ გავრცელებულია და საშუალებას გაძლევთ უფრო ეფექტურად განახორციელოთ ვექტორებისა და მატრიცების გამრავლება. ამ გაფართოების მხარდაჭერამ მნიშვნელოვნად უნდა გააუმჯობესოს შესრულება ვექტორული ოპერაციები. FMA3 უკვე მხარდაჭერილია AMD პროცესორებში Piledriver ბირთვით, ხოლო FMA4 უკვე მხარდაჭერილია ბულდოზერში.
FMA არის გამრავლებისა და შეკრების მოქმედების კომბინაცია: a=b×c+d.
რაც შეეხება FMA3-ს, ეს არის სამოპერანდიანი ინსტრუქციები, ანუ შედეგი იწერება ინსტრუქციაში მონაწილე სამი ოპერანდიდან ერთ-ერთზე. შედეგად, ვიღებთ ოპერაციას, როგორიცაა a=b×c+a, a=a×b+c, a=b×a+c.
FMA4 არის ოთხოპერანდიანი ინსტრუქციები, რომლის შედეგი იწერება მეოთხე ოპერანდზე. ინსტრუქცია იღებს ფორმას: a=b×c+d.
FMA3-ზე საუბრისას: ეს ინოვაცია გაზრდის პროდუქტიულობას 30%-ზე მეტით, თუ კოდი მორგებულია FMA3-ზე. აღსანიშნავია, რომ როდესაც ჰესველი ჯერ კიდევ შორს იყო ჰორიზონტზე, Intel გეგმავდა FMA4-ის დანერგვას და არა FMA3-ს, მაგრამ მოგვიანებით შეცვალა გადაწყვეტილება FMA3-ის სასარგებლოდ. სავარაუდოდ, სწორედ ამის გამო გამოვიდა Bulldozer FMA4-ის მხარდაჭერით: ამბობენ, რომ დრო არ ჰქონდათ მისი ინტელში გადაქცევა (მაგრამ Piledriver გამოვიდა FMA3-ით). უფრო მეტიც, თავდაპირველად Bulldozer 2007 წელს დაიგეგმა FMA3-ით, მაგრამ მას შემდეგ რაც Intel-მა გამოაცხადა FMA4-ის დანერგვის გეგმები 2008 წელს, AMD-მა შეცვალა გადაწყვეტილება და გამოუშვა Bulldozer FMA4-ით. და შემდეგ Intel-მა შეცვალა FMA4 FMA3-ზე თავის გეგმებში, რადგან FMA4-დან მოგება FMA3-თან შედარებით მცირეა და მნიშვნელოვანი ელექტრული ლოგიკური სქემების გართულებაა, რაც ასევე ზრდის ტრანზისტორის ბიუჯეტს.
AVX2-დან და FMA3-დან მიღებული მოგება გამოჩნდება მას შემდეგ, რაც პროგრამული უზრუნველყოფა ადაპტირდება ამ ინსტრუქციების კომპლექტებთან, ასე რომ თქვენ არ უნდა ველოდოთ შესრულების რაიმე გაუმჯობესებას "აქ და ახლა". და რადგან პროგრამული უზრუნველყოფის მწარმოებლები საკმაოდ ინერტული არიან, „დამატებით“ შესრულებას მოუწევს ლოდინი.
ტრანზაქციის მეხსიერება
მიკროპროცესორების ევოლუციამ გამოიწვია ძაფების რაოდენობის ზრდა - თანამედროვე დესკტოპის პროცესორს აქვს რვა ან მეტი მათგანი. ძაფების დიდი რაოდენობა ქმნის მზარდ სირთულეებს მრავალნაკადიანი მეხსიერების წვდომის განხორციელებისას. საჭიროა ცვლადების შესაბამისობის კონტროლი RAM-ში: საჭიროა დაბლოკოს მონაცემები დროულად ჩაწერისთვის ზოგიერთი ძაფისთვის და დაუშვას მონაცემების წაკითხვა ან შეცვლა სხვა ძაფებისთვის. ეს რთული ამოცანაა და ტრანზაქციული მეხსიერება შეიქმნა იმისთვის, რომ მონაცემთა განახლება შეინარჩუნოს მრავალ ხრახნიან პროგრამებში. მაგრამ დღემდე, ის დანერგილი იყო პროგრამულ უზრუნველყოფაში, რამაც შეამცირა პროდუქტიულობა.
ჰასველს აქვს ახალი ტრანზაქციების სინქრონიზაციის გაფართოებები (TSX) - ტრანზაქციების მეხსიერება, რომელიც შექმნილია მრავალძალიანი პროგრამების ეფექტურად დანერგვისა და მათი საიმედოობის გაზრდისთვის. ეს გაფართოებასაშუალებას გაძლევთ დანერგოთ ტრანზაქციული მეხსიერება "ტექნიკაში", რითაც გაზრდით მთლიან შესრულებას.
რა არის ტრანზაქციის მეხსიერება? ეს არის მეხსიერება, რომელსაც აქვს პარალელური პროცესების მართვის მექანიზმი, რათა უზრუნველყოს წვდომა გაზიარებულ მონაცემებზე. TSX გაფართოება შედგება ორი კომპონენტისგან: Hardware Lock Elision (HLE) და შეზღუდული ტრანზაქციის მეხსიერება (RTM).
RTM კომპონენტი არის ინსტრუქციების ნაკრები, რომელიც პროგრამისტს შეუძლია გამოიყენოს ტრანზაქციის დასაწყებად, დასასრულებლად და შეწყვეტისთვის. HLE კომპონენტი შემოაქვს პრეფიქსებს, რომლებიც იგნორირებულია პროცესორების მიერ TSX მხარდაჭერის გარეშე. პრეფიქსები უზრუნველყოფს ცვლადის ჩაკეტვას, რაც საშუალებას აძლევს სხვა პროცესებს გამოიყენონ (წაიკითხონ) ჩაკეტილი ცვლადები და შეასრულონ მათი კოდი, სანამ არ მოხდება ჩაკეტილი მონაცემების ჩაწერის კონფლიქტი.
ამ დროისთვის, ამ გაფართოების გამოყენებით აპლიკაციები უკვე გამოჩნდა.
ვირტუალიზაცია
ვირტუალიზაციის მნიშვნელობა მუდმივად იზრდება: სულ უფრო და უფრო ბევრია ვირტუალური სერვერებიმდებარეობს ერთ ფიზიკურზე და ღრუბლოვანი სერვისები სულ უფრო ფართოვდება. ამიტომ ვირტუალიზაციის ტექნოლოგიებისა და ვირტუალიზებული გარემოს სიჩქარის გაზრდა სერვერის სეგმენტში ძალიან გადაუდებელი ამოცანაა. Haswell შეიცავს რამდენიმე გაუმჯობესებას, რომლებიც მიზნად ისახავს ვირტუალური გარემოს მუშაობის გაზრდას. ჩამოვთვალოთ ისინი:
- გაუმჯობესებები სტუმრის სისტემებიდან მასპინძელ სისტემაზე გადასვლის დროის შესამცირებლად;
- დაამატა წვდომის ბიტები გაფართოებული გვერდის ცხრილზე (EPT);
- TLB წვდომის დრო შემცირდა;
- ახალი ინსტრუქციები ჰიპერვიზორის გამოძახებისთვის vmexit ბრძანების შესრულების გარეშე;
შედეგად, ვირტუალიზებულ გარემოს შორის გადასვლის დრო შემცირდა 500-ზე ნაკლებ პროცესორის ციკლამდე. ამან უნდა გამოიწვიოს ვირტუალიზაციასთან დაკავშირებული მთლიანი შესრულების ზედნადების შემცირება. და ახალი Xeon E3-12xx-v3, სავარაუდოდ, უფრო სწრაფი იქნება ამ კლასში, ვიდრე Xeon E3-12xx-v2.
ჩამონტაჟებული ძაბვის რეგულატორი
ჰასველში ძაბვის რეგულატორი დედაპლატიდან გადავიდა პროცესორის საფარის ქვეშ. ადრე (Sandy Bridge) პროცესორს სჭირდებოდა სხვადასხვა ძაბვის მიწოდება გრაფიკული ბირთვისთვის, სისტემის აგენტისთვის, პროცესორის ბირთვებისთვის და ა. ჩაშენებული ძაბვის რეგულატორისკენ. ძაბვის რეგულატორი შედგება 20 უჯრედისაგან, თითოეული უჯრედი ქმნის 16 ფაზას ჯამური დენით 25 ა. ჯამში ვიღებთ 320 ფაზას, რაც საგრძნობლად მეტია თუნდაც ყველაზე დახვეწილ დედაპლატებზე. ეს მიდგომა საშუალებას იძლევა არა მხოლოდ გამარტივდეს დედაპლატების განლაგება (და შესაბამისად შეამციროს მათი ღირებულება), არამედ უფრო ზუსტად დაარეგულიროს ძაბვები პროცესორის შიგნით, რაც, თავის მხრივ, იწვევს ენერგიის დიდ დაზოგვას.
ეს არის ერთ-ერთი მთავარი მიზეზი, რის გამოც ჰასველი ფიზიკურად არ არის თავსებადი ძველ LGA1155 სოკეტთან. დიახ, ჩვენ შეგვიძლია ვისაუბროთ Intel-ის სურვილზე, გამოიმუშაოს ფული ყოველწლიურად ახალი პლატფორმის (ახალი ჩიპსეტის) და ყოველ ორ წელიწადში ახალი სოკეტის გამოშვებით, მაგრამ ამ შემთხვევაშისოკეტის შეცვლის ობიექტური მიზეზებია: ფიზიკური/ელექტრული შეუთავსებლობა.
თუმცა ყველაფერს თავისი ფასი აქვს. ძაბვის რეგულატორი არის სითბოს კიდევ ერთი შესამჩნევი წყარო ახალ პროცესორში. და იმის გათვალისწინებით, რომ Haswell იწარმოება იმავე პროცესის ტექნოლოგიის გამოყენებით, როგორც მისი წინამორბედი Ivy Bridge, ჩვენ უნდა ველოდოთ, რომ პროცესორი უფრო ცხელი იქნება.

ზოგადად, ეს გაუმჯობესება უფრო მომგებიანი იქნება მობილური სეგმენტში: ძაბვის უფრო სწრაფი და ზუსტი ცვლილებები შეამცირებს ენერგიის მოხმარებას, ასევე უფრო ეფექტურად აკონტროლებს პროცესორის ბირთვების სიხშირეს. და, როგორც ჩანს, ეს არ არის ცარიელი მარკეტინგული განცხადება, რადგან Intel აპირებს გამოაცხადოს მობილური პროცესორები ულტრა დაბალი ენერგიის მოხმარებით.
ენერგიის დაზოგვის ახალი რეჟიმები
ჰასველს აქვს ახალი S0ix ძილის მდგომარეობები, რომლებიც მსგავსია S3/S4 მდგომარეობების, მაგრამ პროცესორის გადასვლის ბევრად უფრო სწრაფი დროით. სამუშაო მდგომარეობა. ასევე დაემატა ახალი C7 უმოქმედო მდგომარეობა.
C7 რეჟიმს თან ახლავს პროცესორის ძირითადი ნაწილის გამორთვა, ხოლო ეკრანზე გამოსახულება აქტიური რჩება.
პროცესორების მინიმალური უმოქმედობის სიხშირეა 800 MHz, რამაც ასევე უნდა შეამციროს ენერგიის მოხმარება.
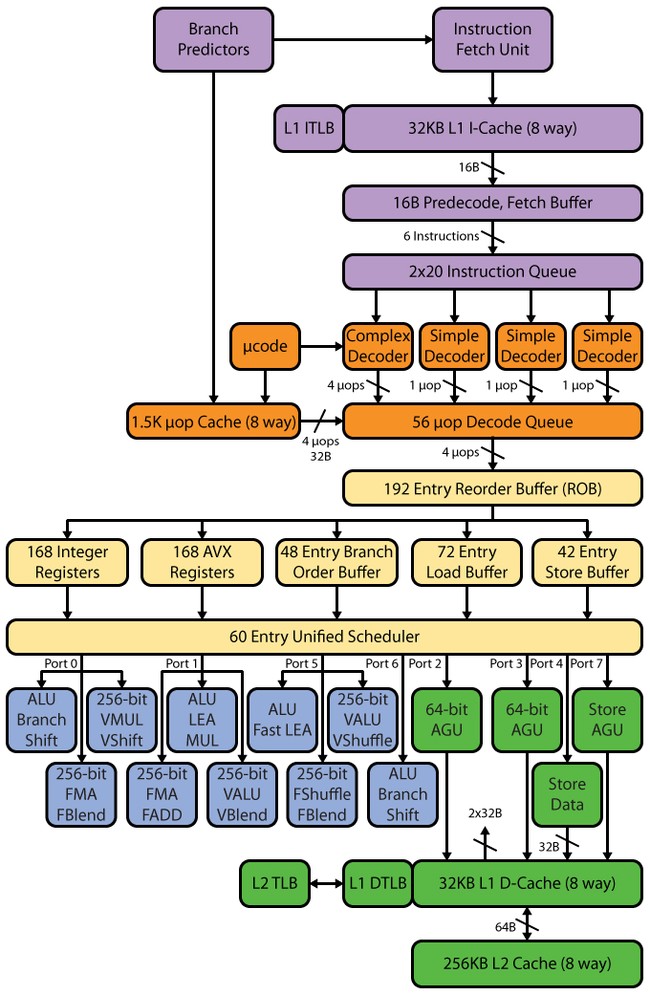
პროცესორის არქიტექტურა

წინა ბოლო


ჰასველის მილსადენს, ისევე როგორც SB-ში, აქვს 14–19 საფეხური: 14 საფეხური μop ქეშის დარტყმისთვის, 19 გამოტოვებისთვის. μop ქეშის ზომა არ შეცვლილა SB-თან შედარებით - 1536 μop. uop ქეშის ორგანიზაცია იგივე დარჩა, რაც SB-ში - რვა ხაზის 32 კომპლექტი, თითოეულში ექვსი uops. თუმცა, აღსრულების მოწყობილობების რაოდენობის გაზრდის გამო, ისევე როგორც შემდგომი ბუფერები uop ქეშის შემდეგ, შეიძლება ველოდოთ uop ქეშის ზრდას - 1776 uops-მდე (რატომ განვიხილავთ ზუსტად ამ მოცულობას ქვემოთ).
დეკოდერი
დეკოდერი, შეიძლება ითქვას, არ შეცვლილა - ის რჩება ოთხმხრივი, ისევე როგორც SB. იგი შედგება ოთხი პარალელური არხისგან: ერთი რთული მთარგმნელი (კომპლექსური დეკოდერი) და სამი მარტივი (მარტივი დეკოდერი). კომპლექსურ თარჯიმანს შეუძლია დაამუშავოს/გაშიფროს რთული ინსტრუქციები, რომლებიც წარმოქმნიან ერთზე მეტ uop-ს. დანარჩენი სამი არხი გაშიფვრავს მარტივ ინსტრუქციებს. სხვათა შორის, მაკროოპერაციების შერწყმის არსებობის გამო, შესრულებისა და გადმოტვირთვის ინსტრუქციებით ჩატვირთვა წარმოქმნის, მაგალითად, ერთ uop-ს და მისი დეკოდირება შესაძლებელია "მარტივი" დეკოდერის არხებში. SSE ინსტრუქციები ასევე წარმოქმნის ერთ uop-ს, ასე რომ მათი გაშიფვრა შესაძლებელია სამი მარტივი არხიდან ნებისმიერში. 256-ბიტიანი AVX-ის, FMA3-ის გაჩენის გათვალისწინებით, ისევე როგორც ტრიგერების პორტებისა და ფუნქციური მოწყობილობების გაზრდილი რაოდენობის გათვალისწინებით, დეკოდერის ეს სიჩქარე შეიძლება უბრალოდ არ იყოს საკმარისი - და ის შეიძლება გახდეს ბოსტნეული. ნაწილობრივ, ეს შეფერხება "გაფართოებულია" L0m uop ქეშით, მაგრამ მაინც, პროცესორის არსებობით 8 გაშვების პორტით, Intel-მა უნდა იფიქროს დეკოდერის გაფართოებაზე - კერძოდ, არ დააზარალებს რთული არხების რაოდენობის გაზრდას.
განრიგი, გადაკვეთის ბუფერი, შესრულების ერთეულები


დეკოდერის შემდეგ მოდის გაშიფრული ინსტრუქციების რიგი და აქ ჩვენ ვხედავთ პირველ ცვლილებას. SB-ს ჰქონდა ორი რიგი 28 ჩანაწერისგან - თითო რიგში თითო ვირტუალურ Hyper-Threading (HT) ძაფზე. ჰასველში ორი რიგები გაერთიანდა ერთ საერთო ორი HT ძაფისთვის 56 ჩანაწერით, ანუ რიგის მოცულობა არ შეცვლილა, მაგრამ შეიცვალა კონცეფცია. ახლა 56 ჩანაწერის მთელი მოცულობა ხელმისაწვდომია ერთ ძაფზე მეორის არარსებობის შემთხვევაში - შესაბამისად, ჩვენ შეგვიძლია ველოდოთ ზრდას როგორც დაბალი ხრახნიანი აპლიკაციების, ასევე მრავალძაფის აპლიკაციებში (ეს განპირობებულია იმით, რომ ორ ძაფს შეუძლია გამოიყენოს ერთი რიგი უფრო ეფექტურად).
შეიცვალა გადაკვეთის ბუფერიც - ის გაიზარდა 168-დან 192-მდე. ამან უნდა გააუმჯობესოს HT-ის ეფექტურობა უფრო მეტადერთმანეთისგან "დამოუკიდებელი" მოპების არსებობა. გაშიფრული micro-op რიგი გაიზარდა 54-დან 60-მდე. ასევე გაიზარდა ფიზიკური რეგისტრის ფაილები, რომლებიც გამოჩნდა SB-ში - 160-დან 168-მდე რეგისტრით მთელი რიცხვი ოპერანდებისთვის და 144-დან 168-მდე მცურავი პუნქტიანი ოპერანდებისთვის, რომლებსაც დადებითი უნდა ჰქონდეთ. ეფექტი ვექტორული გამოთვლების შესრულებაზე.
მოდით შევაჯამოთ ყველა მონაცემი ბუფერებში და რიგებში ცვლილებების შესახებ ერთ ცხრილში.
პრინციპში, ჰესველში პარამეტრების ცვლილებები საკმაოდ მოსალოდნელია, Intel-ის პროცესორის არქიტექტურის განვითარების ზოგადი ლოგიკის გათვალისწინებით. იმავე ლოგიკით შეგვიძლია ვივარაუდოთ, რომ Core-ის მომდევნო თაობაში ბუფერების და რიგების ზომები გაიზრდება არაუმეტეს 14%-ით, ანუ გადაკვეთის ბუფერის ზომა იქნება დაახლოებით 218. მაგრამ ეს არის წმინდა თეორიული. ვარაუდები.
დეკოდირებული ოპერაციების რიგის შემდეგ არის ტრიგერის პორტები და მათზე მიმაგრებული ფუნქციური მოწყობილობები. ამ ეტაპზე უფრო დეტალურად ვისაუბრებთ.
როგორც ვიცით, Sandy Bridge-ს ჰქონდა ექვსი გაშვების პორტი, რომელიც მემკვიდრეობით მიიღო ნეჰალემისგან, რომელიც თავის მხრივ კონროსგან მიიღო. ანუ 2006 წლიდან, როდესაც Intel-მა Pentium 4-ისთვის ხელმისაწვდომ ოთხს კიდევ ორი პორტი დაუმატა, გაშვების პორტების რაოდენობა არ შეცვლილა - დაემატა მხოლოდ ახალი ფუნქციონალური მოწყობილობები. თუმცა, აღსანიშნავია, რომ P4-ს ჰქონდა ერთგვარი ორიგინალური NetBurst არქიტექტურა, რომელშიც მის ორ პორტს შეეძლო ორი ოპერაციის შესრულება ერთი საათის ციკლში (თუმცა არა ყველა ოპერაციით). მაგრამ ყველაზე სწორი იქნებოდა გაშვების პორტების რაოდენობის ევოლუციის თვალყურის დევნება არა P4-ის, არამედ PIII-ის მაგალითის გამოყენებით, რადგან P4-ს აქვს გრძელი მილსადენი და პორტების გაშვება „ორმაგი“ შესრულებით და კვალი ქეში. და მისი მთელი არქიტექტურა შესამჩნევად განსხვავდება ზოგადად მიღებული არქიტექტურისგან. და Pentium III ძალიან ახლოს არის ფუნქციური დიაგრამაგაუშვით პორტები Conroe-ში და ასევე აქვს მოკლე კონტეინერი. ასე რომ, ზოგადად, შეგვიძლია ვთქვათ, რომ კონრო არის PIII-ის პირდაპირი მემკვიდრე. ამის საფუძველზე შეიძლება ითქვას, რომ 2006 წელს მხოლოდ ერთი გაშვების პორტი დაემატა PIII-სთან შედარებით, რომელსაც ჰქონდა ხუთი გაშვების პორტი.
ამრიგად, გაშვების პორტების რაოდენობა საკმაოდ ნელა იზრდება და თუ ახალი დაემატება, მაშინ თითო-თითო. ჰესველმა ერთდროულად დაამატა ორი, სულ რვა პორტი - სულ ცოტა მეტი, და ჩვენ მივალთ Itanium-ში. შესაბამისად ჰესველი აჩვენებს თეორიულ შესრულებას 8 UOP/ციკლის შესრულების გზაზე, საიდანაც 4 UOP იხარჯება არითმეტიკულ ოპერაციებზე, ხოლო დანარჩენი 4 მეხსიერების ოპერაციებზე. შეგახსენებთ, რომ Conroe/Nehalem/SB-ს ჰქონდა 6 uops/ციკლი: 3 uops არითმეტიკული ოპერაციებისთვის და 3 uops მეხსიერების ოპერაციებისთვის. ამ გაუმჯობესებამ უნდა გაზარდოს IPC ქულა და, შესაბამისად, მართლაც არის ძალიან სერიოზული ცვლილებები ჰასველის არქიტექტურაში, რაც სრულად ამართლებს მის ადგილს, როგორც „ასე“ ინტელის განვითარების გეგმაში.
FU ცვლილებები ჰასველში

გაიზარდა აქტუატორების რაოდენობაც. ახალმა მეექვსე (მეშვიდე) პორტმა დაამატა ორი დამატებითი აქტივატორი - მთელი რიცხვის არითმეტიკული და ცვლის მოწყობილობა და განშტოების პროგნოზირების მოწყობილობა. მეშვიდე (მერვე) პორტი პასუხისმგებელია მისამართის გადმოტვირთვაზე.
ამრიგად, ჩვენ ვიღებთ ოთხი მთელი არითმეტიკული აღსრულების ერთეულს, მაშინ როდესაც Sandy Bridge მოგვაწოდა მხოლოდ სამი. აქედან გამომდინარე, შეიძლება ველოდოთ მთელი რიცხვების არითმეტიკის სიჩქარის ზრდას. გარდა ამისა, თეორიულად, ეს საშუალებას მოგვცემს ერთდროულად შევასრულოთ როგორც მცურავი წერტილის, ასევე მთელი რიცხვების გამოთვლები, რაც, თავის მხრივ, გაზრდის NT-ის ეფექტურობას. SB-ში, მცურავი წერტილის გამოთვლები განხორციელდა იმავე პორტებზე, სადაც გამოყენებული იყო მთელი რიცხვითი ფუნქციის მოწყობილობები, ასე რომ, ფაქტობრივად, მოხდა დაბლოკვა, ანუ თქვენ არ შეგეძლოთ "ჰეტეროგენული" დატვირთვა. ისიც უნდა აღინიშნოს, რომ დასძინა დამატებითი მოწყობილობაჰასველში გადასვლა შესაძლებელს გახდის არითმეტიკული გამოთვლების დროს გადასვლის პროგნოზირებას „დაბლოკვის“ გარეშე - ადრე, მთელი რიცხვის გამოთვლების დროს, იბლოკებოდა ერთადერთი ფილიალის პროგნოზირება, ანუ შესაძლებელი იყო არითმეტიკული შესრულების ერთეულის ან პროგნოზირების ფუნქციონირება. 0 და 1 პორტებმა ასევე განიცადეს ცვლილებები - ისინი ახლა მხარს უჭერენ FMA3-ს. მეშვიდე (მერვე) ინტელის პორტიდაინერგა ეფექტურობის გაზრდისა და „ბლოკირების“ მოხსნის მიზნით - როდესაც მეორე და მესამე პორტები მუშაობს დატვირთვაზე, მეშვიდე (მერვე) პორტი შეიძლება ჩაერთოს გადმოტვირთვაში, რაც აქამდე უბრალოდ შეუძლებელი იყო. ეს გამოსავალი აუცილებელია AVX/FMA3 კოდის შესრულების მაღალი სიჩქარის უზრუნველსაყოფად.
ზოგადად, ასეთმა ფართო აღმასრულებელმა გზამ შეიძლება გამოიწვიოს HT-ის ცვლილება - გახადოს იგი ოთხძაფიანი. Intel Xeon Phi კოპროცესორებში, შესრულების გაცილებით ვიწრო ბილიკით, HT არის ოთხძაფიანი და, როგორც კვლევებმა და ტესტებმა აჩვენა, კოპროცესორი საკმაოდ კარგად მასშტაბებს. ანუ, შესრულების ვიწრო გზაც კი, პრინციპში, საშუალებას გაძლევთ ეფექტურად იმუშაოთ ოთხი ძაფით. და რვა გაშვების პორტის მქონე გზას შეუძლია საკმაოდ ეფექტურად გაატაროს ოთხი ძაფი, და მეტიც, ოთხი ძაფის არსებობას შეუძლია უკეთ ჩატვირთოს რვა გაშვების პორტი. მართალია, მეტი ეფექტურობისთვის საჭირო იქნება ბუფერების გაზრდა (პირველ რიგში, ხელახალი დალაგების ბუფერი) "დამოუკიდებელი" მონაცემების უფრო დიდი ალბათობისთვის.
ჰასველმა ასევე გააორმაგა L1-L2 გამტარუნარიანობა, ამავე დროს შეინარჩუნა შეყოვნების იგივე მნიშვნელობები. ეს ზომა უბრალოდ აუცილებელი იყო, რადგან 32-ბიტიანი ჩაწერა და 16-ბაიტი კითხვა უბრალოდ არ იქნებოდა საკმარისი რვა გაშვების პორტის არსებობის გათვალისწინებით, ასევე 256-ბიტიანი AVX და FMA3.
| ქვიშის ხიდი | ჰესველი | |
| L1i | 32k, 8 გზა | 32k, 8 გზა |
| L1d | 32k, 8 გზა | 32k, 8 გზა |
| შეყოვნება | 4 ზომა | 4 ზომა |
| Გადმოწერის სიჩქარე | 32 ბაიტი/საათი | 64 ბაიტი/საათი |
| ჩაწერის სიჩქარე | 16 ბაიტი/ციკლი | 32 ბაიტი/საათი |
| L2 | 256 ათასი, 8 გზა | 256 ათასი, 8 გზა |
| შეყოვნება | 11 ზომა | 11 ზომა |
| გამტარუნარიანობა L2-სა და L1-ს შორის | 32 ბაიტი/საათი | 64 ბაიტი/საათი |
| L1i TLB | 4k: 128, 4 გზა 2M/4M: 8/ძაფი | 4k: 128, 4 გზა 2M/4M: 8/ძაფი |
| L1d TLB | 4k: 128, 4 გზა 2M/4M: 7/ძაფი 1G: 4, 4 გზა | 4k: 128, 4 გზა 2M/4M: 7/ძაფი 1G: 4, 4 გზა |
| L2 TLB | 4k: 512, 4 გზა | 4k+2M გაზიარებული: 1024, 8-გზის |
TLB L2 გაიზარდა 1024 ჩანაწერამდე და გამოჩნდა ორი მეგაბაიტიანი გვერდების მხარდაჭერა. TLB L2-ის ზრდამ ასევე გამოიწვია ასოციაციურობის ზრდა ოთხიდან რვამდე.
რაც შეეხება მესამე დონის ქეშს, მასთან სიტუაცია ორაზროვანია: ახალ პროცესორში წვდომის შეყოვნება უნდა გაიზარდოს სინქრონიზაციის დანაკარგების გამო, რადგან ახლა L3 ქეში მუშაობს საკუთარი სიხშირით და არა პროცესორის ბირთვების სიხშირით. როგორც ადრე იყო. მიუხედავად იმისა, რომ წვდომა მაინც შესრულებულია 32 ბაიტით საათის ციკლზე. მეორეს მხრივ, Intel საუბრობს სისტემის აგენტის ცვლილებებზე და Load Balancer ბლოკის გაუმჯობესებაზე, რომელსაც ახლა შეუძლია დამუშავდეს მრავალი L3 ქეშის მოთხოვნა პარალელურად და დაყოს ისინი მონაცემებად და არამონაცემებად. ამან უნდა გაზარდოს L3 ქეშის გამტარუნარიანობა (ზოგიერთი ტესტი ამას ადასტურებს, L3 ქეშის გამტარუნარიანობა ოდნავ აღემატება IB-ს).
ჰასველში L3 ქეშის მუშაობის პრინციპი გარკვეულწილად ჰგავს ნეჰალემს. ნეჰალემში L3 ქეში მდებარეობდა Uncore-ში და ჰქონდა თავისი ფიქსირებული სიხშირე, ხოლო SB-ში L3 ქეში მიბმული იყო პროცესორის ბირთვებზე - მისი სიხშირე გახდა პროცესორის ბირთვების სიხშირის ტოლი. ამის გამო წარმოიშვა პრობლემები - მაგალითად, როდესაც პროცესორის ბირთვები მუშაობდნენ შემცირებულ სიხშირეებზე, როდესაც დატვირთვა არ იყო (და შპს "დაეძინა"), ხოლო GPU-ს სჭირდებოდა მაღალი LLC PS. ანუ, ეს გამოსავალი ზღუდავდა GPU-ს მუშაობას და ასევე მოითხოვდა პროცესორის ბირთვების გამოყვანას უმოქმედო მდგომარეობიდან მხოლოდ შპს-ს გასაღვიძებლად. ახალ პროცესორში, ენერგიის მოხმარების მდგომარეობის გასაუმჯობესებლად და GPU-ს ეფექტურობის გაზრდის ზემოთ აღწერილ სიტუაციებში, L3 ქეში მუშაობს საკუთარი სიხშირით. მობილური და არა დესკტოპის გადაწყვეტილებები ყველაზე მეტად უნდა ისარგებლოს ამ გადაწყვეტილებებით.
აღსანიშნავია, რომ ქეშის ზომას აქვს გარკვეული დამოკიდებულება. მესამე დონის ქეში არის ორი მეგაბაიტი თითო ბირთვზე, მეორე დონის ქეში არის 256 KB, რაც რვაჯერ ნაკლებია L3 მოცულობაზე თითო ბირთვზე. პირველი დონის ქეშის მოცულობა, თავის მხრივ, რვაჯერ ნაკლებია ვიდრე L2 და არის 32 კბ. Uop ქეში მშვენივრად ჯდება ამ დამოკიდებულებაში: მისი მოცულობა 1536 uop 7-9-ჯერ ნაკლებია ვიდრე L1 (ამის ზუსტად დადგენა შეუძლებელია, რადგან uop-ის ბიტის ზომა უცნობია და Intel ნაკლებად სავარაუდოა, რომ გააფართოვოს ამ თემაზე. ). თავის მხრივ, გადაკვეთის ბუფერი 168 uops არის ზუსტად რვაჯერ ნაკლები ქეში uops 1536 uops-ში, თუმცა, ბუფერებისა და რიგების ფართოდ გაზრდილიდან გამომდინარე, მოსალოდნელია uop ქეშის ზრდა 14%-ით, ანუ 1776 წლამდე. ამრიგად, ბუფერების და ქეშების მოცულობა პროპორციულია ზომით. ეს, ალბათ, კიდევ ერთი მიზეზია, რის გამოც Intel არ ზრდის L1/L2 ქეშებს, რადგან თვლის, რომ ასეთი პროპორციები მოცულობებში ყველაზე ეფექტურია მუშაობის გაზრდის თვალსაზრისით თითო ფართობის გაზრდის თვალსაზრისით. აღსანიშნავია, რომ პროცესორებს, რომლებსაც აქვთ ჩაშენებული ზედა დონის გრაფიკული ბირთვი, აქვთ შუალედური სწრაფი მეხსიერება ფართო წვდომის ავტობუსით, რომელიც ინახავს ყველა მოთხოვნას RAM-ზე - როგორც პროცესორს, ასევე ვიდეო ამაჩქარებელს. ამ მეხსიერების მოცულობა 128 მბ. პროცესორის ბირთვებისთვის, თუ ამ მეხსიერებას L4 ქეშად მივიჩნევთ, მოცულობა უნდა ყოფილიყო 64 მეგაბაიტი, ხოლო გრაფიკული ბირთვის დამატებით, 128 მბ-ის გამოყენება საკმაოდ ლოგიკური ჩანს.
რაც შეეხება მეხსიერების კონტროლერს, მას არ მიუღია არც არხების რაოდენობის მატება და არც ოპერატიული მეხსიერების მოქმედების სიხშირის გაზრდა, ანუ ისევ იგივე მეხსიერების კონტროლერია ორარხიანი წვდომით 1600 MHz სიხშირით. ეს გადაწყვეტილება საკმაოდ უცნაურად გამოიყურება, რადგან SB-დან IB-ზე გადასვლამ გაზარდა ICP-ის ოპერაციული სიხშირე 1333 MHz-დან 1600 MHz-მდე, თუმცა ეს იყო მხოლოდ არქიტექტურის გადასვლა ახალ ტექნიკურ პროცესზე. ახლა ჩვენ გვაქვს ახალი არქიტექტურა, ხოლო მეხსიერების მუშაობის სიხშირე რჩება იგივე დონე.
ეს კიდევ უფრო უცნაურად გამოიყურება, თუ გავიხსენებთ გრაფიკული ბირთვის გაუმჯობესებებს - ბოლოს და ბოლოს, გვახსოვს, რომ დაბალი დონის HD2500 ვიდეო ბარათიც კი IB-ში სრულად იყენებდა 25 გბ/წმ სიჩქარეს. ახლა გაიზარდა როგორც CPU-ს, ასევე გრაფიკის შესრულება, ხოლო მეხსიერების გამტარუნარიანობა იგივე დონეზე დარჩა. უფრო ფართო მასშტაბით, კონკურენტი მუდმივად ზრდის მეხსიერების გამტარუნარიანობას თავის APU-ებში და ის უფრო მაღალია ვიდრე Intel-ის. ლოგიკური იქნებოდა ჰასველის მეხსიერების მხარდაჭერა 1866 MHz ან 2133 MHz სიხშირით, რაც გაზრდის გამტარუნარიანობას შესაბამისად 30 და 34 გბ/წმ-მდე.
შედეგად, ეს Intel გადაწყვეტაარ არის საკმაოდ ნათელი. პირველ რიგში, კონკურენტმა შემოიღო მხარდაჭერა უფრო სწრაფი მეხსიერების გარეშე განსაკუთრებული პრობლემები. მეორეც, 1866 MHz სიხშირეზე მომუშავე მეხსიერების მოდულების ღირებულება არ არის ბევრად მაღალი 1600 MHz მოდულებთან შედარებით და გარდა ამისა, არავინ არ არის ვალდებული იყიდოს 1866 MHz მეხსიერება - არჩევანი მომხმარებლის გადასაწყვეტი იქნება. მესამე, არ შეიძლება იყოს პრობლემები არა მხოლოდ 1866 MHz-ის, არამედ 2133 MHz-ის მხარდაჭერასთან დაკავშირებით: Haswell-ის გამოცხადების შემდეგ, დაწესდა მსოფლიო რეკორდები RAM-ის გადატვირთვის შესახებ, ანუ IKP შეძლებდა უფრო სწრაფ მეხსიერების მართვას გარეშე. ნებისმიერი პრობლემა. მეოთხე, Xeon E5-2500 V2 (Ivy Bridge-EP) სერვერის ხაზი აცხადებს მხარდაჭერას 1866 MHz-ზე, მაგრამ Intel ჩვეულებრივ შემოაქვს უფრო სწრაფი მეხსიერების სტანდარტების მხარდაჭერას ამ ბაზარზე ბევრად უფრო გვიან, ვიდრე დესკტოპის გადაწყვეტილებები.
პრინციპში, შეიძლება ვივარაუდოთ, რომ კონკურენციის არარსებობის შემთხვევაში, ინტელს არ სჭირდება კუნთების "ასე" გაძლიერება და უპირატესობის გაზრდა, მაგრამ ეს ვარაუდი აბსოლუტურად არასწორია, რადგან ზრდა გამტარუნარიანობამეხსიერება ზოგადად ზრდის ინტეგრირებული გრაფიკული ბირთვის მუშაობას და თითქმის არ ზრდის პროცესორის მუშაობას. ამავდროულად, Intel კვლავ ჩამორჩება AMD-ს გრაფიკულ შესრულებაში და ბოლო წლებითავად Intel უფრო და უფრო მეტ ყურადღებას აქცევს გრაფიკას და მისი გაუმჯობესების მაჩვენებელი გაცილებით მაღალია, ვიდრე პროცესორის ბირთვისთვის. გარდა ამისა, თუ დავეყრდნობით წინა თაობის HD4000 ინტეგრირებული გრაფიკული ბირთვის ტესტირების შედეგებს, რომელმაც აჩვენა, რომ მეხსიერების გამტარუნარიანობის ზრდა იწვევს გრაფიკის შესრულების 30%-მდე ზრდას და ასევე იმის გათვალისწინებით, რომ ახალი გრაფიკული ბირთვი HD4600 შესამჩნევად უფრო სწრაფია ვიდრე HD4000, შემდეგ კი გრაფიკული ბირთვის მუშაობის დამოკიდებულება PSP-ისგან კიდევ უფრო აშკარა ხდება. ახალი გრაფიკული ბირთვი კიდევ უფრო შეზღუდული იქნება მეხსიერების "ვიწრო" გამტარუნარიანობით. ყველა ფაქტის შეჯამებით, Intel-ის გადაწყვეტილება სრულიად გაუგებარია: თავად კომპანიამ "დაახრჩო" მისი გრაფიკა, მაგრამ გამტარუნარიანობის ზრდამ შეიძლება გააუმჯობესოს მისი შესრულება.
ქეშების არქიტექტურას რომ დავუბრუნდეთ, მოდით, უბრალოდ გადავაგდოთ აზრი სიცარიელეში: ვინაიდან დამატებულია შუალედური ქეში (მოპ ქეში), მაშინ რატომ არ უნდა დაამატოთ მონაცემთა შუალედური ქეში დაახლოებით 4-8 კბ ზომისა და უფრო დაბალი წვდომით. შეყოვნება L1d ქეშსა და აღმასრულებელ მოწყობილობებს შორის, მაგალითად P4-დან (რადგან uop ქეშის კონცეფცია აღებულია Netburst-დან)? შეგახსენებთ, რომ P4-ში ამ შუალედურ მონაცემთა ქეშს ჰქონდა წვდომის დრო ორი საათის ციკლით, ერთი P4 საათის ციკლი უდრის დაახლოებით 0,75 საათის ციკლს. ჩვეულებრივი პროცესორი, ანუ წვდომის დრო იყო დაახლოებით საათნახევარი ციკლი. თუმცა, იქნებ ისევ ვნახოთ მსგავსი რამ - ინტელს უყვარს დავიწყებული ძველი ნივთების გახსენება.
როგორც ხედავთ, Intel-მა არქიტექტურული ცვლილებების უმეტესი ნაწილი მიმართა AVX/FMA3 კოდის მუშაობის გაზრდისკენ: ეს მოიცავდა ქეშის გამტარუნარიანობის გაზრდას, პორტების რაოდენობის ზრდას და ატვირთვის/ჩატვირთვის სიჩქარის ზრდას შესრულების გზა. შედეგად, ძირითადი შესრულების მომატება უნდა მოდიოდეს AVX/FMA3-ის გამოყენებით დაწერილი პროგრამული უზრუნველყოფიდან. პრინციპში, ტესტის შედეგებით თუ ვიმსჯელებთ, როგორც ჩანს, ასეა. მშრალი შესრულება იმავე სიხშირით "ძველ" აპლიკაციებში მიიღო დაახლოებით 10% ზრდა წინა ბირთვთან შედარებით, ხოლო ახალი ინსტრუქციების ნაკრების გამოყენებით დაწერილი აპლიკაციები აჩვენებენ 30% -ზე მეტ ზრდას. ასე რომ, ჰასველის არქიტექტურის სარგებელი გამოვლინდება, როდესაც აპლიკაციები ოპტიმიზებულია ახალი ინსტრუქციების ნაკრებისთვის. სწორედ მაშინ გახდება აშკარა ჰასველის უპირატესობა SB-ზე.
ინოვაციების მნიშვნელოვანი ნაწილიდან მთავარი სარგებელი იქნება მობილური მოწყობილობები. მათ დაეხმარებიან და ახალი მიდგომა L3 ქეში, ჩაშენებული ძაბვის რეგულატორი, ძილის ახალი რეჟიმები და პროცესორის ბირთვების დაბალი მინიმალური ოპერაციული სიხშირე.
დასკვნა (პროცესორის ნაწილი)
რას შეიძლება ელოდოთ ჰესველისგან?
გაშვების პორტების რაოდენობის გაზრდის გამო, ჩვენ შეგვიძლია ველოდოთ IPC-ის ზრდას, ამიტომ ახალი Haswell არქიტექტურას ექნება მცირე უპირატესობა Sandy Bridge-ზე იმავე სიხშირით ახლაც, თუნდაც არაოპტიმიზებული პროგრამული უზრუნველყოფის პირობებში. AVX2/FMA3 ინსტრუქციები მომავლის საფუძველია და ეს მომავალი დამოკიდებულია პროგრამული უზრუნველყოფის შემქმნელებზე: რაც უფრო სწრაფად ადაპტირებენ თავიანთ აპლიკაციებს, მით უფრო სწრაფად საბოლოო მომხმარებელიმიიღებს შესრულების გაძლიერებას. თუმცა, არ უნდა ელოდოთ ზრდას ყველაფერში და ყველგან: SIMD ინსტრუქციები ძირითადად გამოიყენება მულტიმედიურ მონაცემებთან მუშაობისას და სამეცნიერო გამოთვლებში, ამიტომ ამ ამოცანებში მოსალოდნელია შესრულების ზრდა. ენერგოეფექტურობის გაზრდის მთავარი სარგებელი იქნება მობილურ სისტემებში, სადაც ეს საკითხი მართლაც მნიშვნელოვანია. ამრიგად, ორი ძირითადი სფერო, რომლებშიც Intel Haswell-ის ახალი არქიტექტურა მნიშვნელოვნად სარგებლობს, არის გაზრდილი SIMD შესრულება და გაზრდილი ენერგოეფექტურობა.
რაც შეეხება ახალი Haswell პროცესორების გამოყენებას, ღირს მათი გამოყენების რამდენიმე განსხვავებული ვარიანტის შესწავლა: დესკტოპ კომპიუტერებში, სერვერებში, მობილურ გადაწყვეტილებებში, მოთამაშეებისთვის, ოვერკლოკერებისთვის.
სამუშაო მაგიდა
ენერგიის მოხმარება არ არის მთავარი ასპექტი დესკტოპის პროცესორისთვის, ასე რომ, ევროპაშიც კი, თავისი ძვირადღირებული ელექტროენერგიით, ნაკლებად სავარაუდოა, რომ ვინმე გადავიდეს Haswell-ზე. წინა თაობებიმხოლოდ ამის გამო. უფრო მეტიც, ჰასველის TDP უფრო მაღალია, ვიდრე IB-ის, ასე რომ დაზოგვა მოხდება მხოლოდ იმ შემთხვევაში, თუ მინიმალური დატვირთვები. როდესაც კითხვა ასე დაისმება, ეჭვი არ ეპარება - არ ღირს.
შესრულების თვალსაზრისით, გადასვლა ასევე არ ჰგავს ასეთ მომგებიან გარიგებას: პროცესორის ამოცანების მაქსიმალური სიჩქარის ზრდა ახლა იქნება არაუმეტეს 10%. Sandy Bridge-დან ან Ivy Bridge-დან Haswell-ზე გადასვლა გამართლებული იქნება მხოლოდ იმ შემთხვევაში, თუ თქვენ გეგმავთ FMA3 და AVX2 კომპეტენტური მხარდაჭერით აპლიკაციების გამოყენებას: FMA3 მხარდაჭერამ შეიძლება გაზარდოს ზოგიერთ აპლიკაციაში 30%-დან 70%-მდე. ვირტუალიზაციასთან და ტრანზაქციული მეხსიერების დანერგვასთან დაკავშირებული გაუმჯობესებები ნაკლებად საინტერესოა და გამოიყენება დესკტოპისთვის.
სერვერები და სამუშაო სადგურები
იმის გათვალისწინებით, რომ სერვერები მუშაობენ მუდმივად 24 საათის განმავლობაში და აქვთ საკმაოდ მაღალი მუდმივი დატვირთვა პროცესორზე, Haswell ნაკლებად სავარაუდოა, რომ უკეთესი იყოს ვიდრე IB სუფთა ენერგიის მოხმარების თვალსაზრისით, თუმცა შეიძლება უზრუნველყოს გარკვეული მოგება თითო ვატზე მუშაობის თვალსაზრისით. AVX2/FMA3 მხარდაჭერა ნაკლებად სავარაუდოა, რომ გამოდგება სერვერებზე, მაგრამ სამუშაო სადგურებში, რომლებიც ჩართულნი არიან სამეცნიერო გამოთვლებში, ეს მხარდაჭერა იქნება ძალიან, ძალიან სასარგებლო - მაგრამ მხოლოდ იმ შემთხვევაში, თუ ახალი ინსტრუქციები მხარდაჭერილია გამოყენებულ პროგრამულ უზრუნველყოფაში. ტრანზაქციული მეხსიერება საკმაოდ სასარგებლო რამ არის, მაგრამ ასევე არა ყოველთვის: მას შეუძლია გაზარდოს მრავალძალიან პროგრამებში და პროგრამებში, რომლებიც მუშაობენ მონაცემთა ბაზებთან, მაგრამ მისი ეფექტური გამოყენებაასევე აუცილებელია პროგრამული უზრუნველყოფის ოპტიმიზაცია.
მაგრამ ვირტუალიზაციასთან დაკავშირებული ყველა გაუმჯობესება, სავარაუდოდ, კარგ ეფექტს მოახდენს, რადგან ვირტუალური გარემო ახლა ძალიან აქტიურად გამოიყენება და ფიზიკურ სერვერების უმეტესობას აქვს რამდენიმე ვირტუალური. უფრო მეტიც, ვირტუალიზაციის გავრცელება აიხსნება არა მხოლოდ ხარჯების შესამჩნევი შემცირებით ვირტუალური გარემოშესრულების თვალსაზრისით, მაგრამ ასევე ეკონომიკური ეფექტურობა: ბევრი ვირტუალური სერვერის შემცველობა ერთ ფიზიკურზე უფრო იაფია და იძლევა რესურსების, მათ შორის, პროცესორის რესურსების უფრო ეფექტური გამოყენების საშუალებას.
ასე რომ, ჰასველის გამოჩენა დადებითად უნდა მივესალმოთ სერვერების ბაზარზე. Xeon E3-1200v1-ზე და Xeon E3-1200v2-ზე დაფუძნებული სერვერების შეცვლის შემდეგ სერვერებზე Xeon E3-1200v3 (Haswell), თქვენ დაუყოვნებლივ მიიღებთ ეფექტურობის ზრდას, ხოლო AVX2/FMA3 და ოპერაციული მეხსიერებისთვის პროგრამული უზრუნველყოფის ოპტიმიზაციის შემდეგ, შესრულება გაიზრდება. კიდევ უფრო მეტი.
მობილური გადაწყვეტილებები
მობილურ სეგმენტში Haswell-ის დანერგვის მთავარი სარგებელი, რა თქმა უნდა, მდგომარეობს ენერგიის გაუმჯობესებული მოხმარების სფეროში. თუ ვიმსჯელებთ Intel-ის პრეზენტაციებით, ისევე როგორც ტესტის შედეგებით, რომლებიც უკვე ჩნდება ინტერნეტში, ეფექტი ნამდვილად არის და შესამჩნევი.
სუფთა შესრულების თვალსაზრისით, აივი ბრიჯიდან ჰასველზე გადასვლა არც ისე გონივრული საქმეა: წმინდა მოგება უნდა იყოს შედარებით მცირე, ხოლო გაუმჯობესება ინდივიდუალური კომპონენტები(იგივე ვირტუალიზაცია ან მულტიმედიური ინსტრუქციები) ნაკლებად სავარაუდოა, რომ მობილური სისტემის მომხმარებელს ბევრი რამ მისცეს, რადგან ისინი იშვიათად ქმნიან გარემოს ან რთულ სამეცნიერო გამოთვლებს ლეპტოპებსა და ტაბლეტებზე.
ზოგადად, პროცესორის მუშაობის თვალსაზრისით, ბევრს არ უნდა ელოდოთ, მაგრამ მობილური სისტემები, რა თქმა უნდა, მოითხოვენ გრაფიკული ბირთვის მუშაობის გაზრდას. ამიტომ, თუ ენერგიის მოხმარების საკითხები თქვენთვის კრიტიკულად მნიშვნელოვანი არ არის, მაშინ სერიოზულად არ უნდა განიხილოთ განახლება Sandy Bridge-დან ან Ivy Bridge-დან - უმჯობესია გააგრძელოთ არსებული სისტემების მუშაობა, სანამ ისინი მთლიანად მოძველდება. თუ ხშირად მუშაობთ ბატარეებზე, მაშინ ჰასველს შეუძლია უზრუნველყოს ბატარეის მუშაობის მნიშვნელოვანი ზრდა.
გეიმერები
რუსეთში გეიმერებს შორის ენერგიის მოხმარების საკითხი, როგორც წესი, არ არის პრობლემა - და რატომ უნდა იყოს ეს, როდესაც სათამაშო ვიდეო ბარათები მოიხმარენ 200 ვატს ან მეტს? გეიმერებს ასევე არ სჭირდებათ ვირტუალიზაცია და ტრანზაქციის მეხსიერება. ფაქტი არ არის, რომ AVX2/FMA3 მოთხოვნადი იქნება კონკრეტულად თამაშებზე, თუმცა ისინი შეიძლება გამოადგეს ფიზიკურ გამოთვლებს. რჩება პროცესორის სუფთა შესრულება და აქ განსხვავება იგივე Ivy Bridge-თან მცირეა. შედეგად, ამ კატეგორიის მომხმარებლებისთვის პირდაპირი გადასვლა SB-დან ან IB-დან Haswell-ზე ასევე არ ჩანს შესაბამისი. მაგრამ აზრი აქვს გადავიდეთ ახალ პროცესორებზე ნეჰალემიდან და ლინიფილდიდან და მით უმეტეს კონროდან.
ოვერკლოკერები
ოვერკლოკერებისთვის ახალი პროცესორი (მაგრამ, რა თქმა უნდა, მხოლოდ მისი „განბლოკილი“ K-ვერსია) შეიძლება იყოს საინტერესო, მით უმეტეს, თუ შესაძლებელია მისი „სკალპირება“, ანუ ლითონის საფარის მოხსნა და ბროლის პირდაპირ გაგრილება. თუ ეს არ გაკეთებულა, მაშინ გადატვირთვის შედეგები კიდევ უფრო მოკრძალებულად გამოიყურება, ვიდრე აივი ბრიჯის შედეგები. გარდა ამისა, ინტეგრირებული ძაბვის რეგულატორი შეიძლება იყოს შემზღუდველი ფაქტორი. წაიკითხეთ მეტი ამის შესახებ
ყოველი ახალი თაობის ინტელის პროცესორები ყველაფერს აერთიანებს მეტი ტექნოლოგიადა ფუნქციები. ზოგიერთი მათგანი კარგად არის ცნობილი (ვინ, მაგალითად, არ იცის ჰიპერთრედინგის შესახებ?), ხოლო არასპეციალისტთა უმეტესობამ არც კი იცის სხვების არსებობის შესახებ. მოდით გავხსნათ ცნობილი ცოდნის ბაზა Intel Automated Relational Knowledge Base (ARK) პროდუქტებისთვის და შევარჩიოთ იქ პროცესორი. ჩვენ დავინახავთ მახასიათებლებისა და ტექნოლოგიების დიდ ჩამონათვალს - რა იმალება მათი იდუმალი მარკეტინგული სახელების მიღმა? გეპატიჟებით, ჩაუღრმავდეთ საკითხს, შემობრუნებით Განსაკუთრებული ყურადღებანაკლებად ცნობილ ტექნოლოგიებზე - იქ, რა თქმა უნდა, ბევრი საინტერესო რამ იქნება.
Intel მოთხოვნაზე დაფუძნებული გადართვა
Intel-ის გაძლიერებულ SpeedStep ტექნოლოგიასთან ერთად, Intel მოთხოვნაზე დაფუძნებული გადართვის ტექნოლოგია პასუხისმგებელია პროცესორის მუშაობის უზრუნველსაყოფად ოპტიმალური სიხშირედა მიიღო ადეკვატური ენერგიის წყარო: არც მეტი და არც ნაკლები, ვიდრე საჭიროა. ეს ამცირებს ენერგიის მოხმარებას და სითბოს გაფრქვევას, რაც მნიშვნელოვანია არა მხოლოდ პორტატული მოწყობილობებისთვის, არამედ სერვერებისთვისაც – სწორედ აქ გამოიყენება მოთხოვნაზე დაფუძნებული გადართვა.
Intel სწრაფი მეხსიერების წვდომა
მეხსიერების კონტროლერის ფუნქცია RAM-ის მუშაობის ოპტიმიზაციისთვის. ეს არის ტექნოლოგიების ერთობლიობა, რომელიც საშუალებას იძლევა, ბრძანებების რიგის სიღრმისეული ანალიზის მეშვეობით, ამოიცნოთ „გადახურული“ ბრძანებები (მაგალითად, იგივე მეხსიერების გვერდიდან კითხვა) და შემდეგ გადავაწყოთ რეალური შესრულება ისე, რომ „გადახურული“ ბრძანებები იყოს. შესრულებულია ერთმანეთის მიყოლებით. გარდა ამისა, მეხსიერების ჩაწერის დაბალი პრიორიტეტის ბრძანებები დაგეგმილია იმ დროისთვის, როდესაც მოსალოდნელია წაკითხვის რიგის დაცლა, რაც მეხსიერების ჩაწერის პროცესს კიდევ უფრო ნაკლებად ზღუდავს წაკითხვის სიჩქარეს.
Intel Flex მეხსიერების წვდომა
მეხსიერების კონტროლერის კიდევ ერთი ფუნქცია, რომელიც გამოჩნდა ჯერ კიდევ იმ დღეებში, როდესაც ის ცალკე ჩიპი იყო, ჯერ კიდევ 2004 წელს. უზრუნველყოფს სინქრონულ რეჟიმში მუშაობის შესაძლებლობას ორი მეხსიერების მოდულით ერთდროულად და განსხვავებით მარტივი ორმაგი არხის რეჟიმი, რომელიც ადრე არსებობდა, მეხსიერების მოდულები შეიძლება იყოს სხვადასხვა ზომის. ამ გზით მიღწეული იქნა მოქნილობა კომპიუტერის მეხსიერებით აღჭურვისას, რაც აისახება სახელწოდებაში.
Intel Instruction Replay
ძალიან ღრმა ტექნოლოგია, რომელიც პირველად გამოჩნდა Intel Itanium პროცესორებში. პროცესორის მილსადენების ექსპლუატაციის დროს შეიძლება მოხდეს სიტუაცია, როდესაც ინსტრუქციები უკვე შესრულებულია, მაგრამ საჭირო მონაცემები ჯერ არ არის ხელმისაწვდომი. შემდეგ საჭიროა ინსტრუქციის „გამეორება“: ამოღებული კონვეიერიდან და გაშვება მის დასაწყისში. რაც ხდება ზუსტად. IRT-ის კიდევ ერთი მნიშვნელოვანი ფუნქციაა კორექტირება შემთხვევითი შეცდომებიპროცესორის მილსადენებზე. წაიკითხეთ მეტი ამ ძალიან საინტერესო მახასიათებლის შესახებ.
Intel My WiFi ტექნოლოგია
ვირტუალიზაციის ტექნოლოგია, რომელიც საშუალებას გაძლევთ დაამატოთ ვირტუალური WiFiადაპტერი არსებულ ფიზიკურთან; ამრიგად, თქვენი ულტრაბუქი ან ლეპტოპი შეიძლება გახდეს სრულფასოვანი წვდომის წერტილი ან გამეორება. ჩემი WiFi პროგრამული უზრუნველყოფის კომპონენტები მოყვება Intel PROSet Wireless Software-ის დრაივერის 13.2 და შემდეგ ვერსიას; უნდა გვახსოვდეს, რომ მხოლოდ ზოგიერთი ტექნოლოგია თავსებადია WiFi ადაპტერები. ინსტალაციის ინსტრუქციები, ისევე როგორც პროგრამული უზრუნველყოფისა და აპარატურის თავსებადობის სია, შეგიძლიათ იხილოთ Intel-ის ვებსაიტზე.
Intel Smart Idle ტექნოლოგია
ენერგიის დაზოგვის კიდევ ერთი ტექნოლოგია. საშუალებას გაძლევთ გამორთოთ ამჟამად გამოუყენებელი პროცესორის ბლოკები ან შეამციროთ მათი სიხშირე. შეუცვლელი რამ სმარტფონის CPU-სთვის, რომელიც სწორედ იქ გამოჩნდა - Intel Atom პროცესორებში.
Intel სტაბილური გამოსახულების პლატფორმა
ტერმინი, რომელიც ეხება ბიზნეს პროცესებს და არა ტექნოლოგიას. ინტელის პროგრამა SIPP უზრუნველყოფს პროგრამული უზრუნველყოფის სტაბილურობას იმის უზრუნველსაყოფად, რომ ძირითადი პლატფორმის კომპონენტები და დრაივერები უცვლელი რჩება მინიმუმ 15 თვის განმავლობაში. ამრიგად, კორპორატიული კლიენტებიაქვს შესაძლებლობა გამოიყენოს იგივე განლაგებული სისტემის სურათები ამ პერიოდში.
Intel QuickAssist
ტექნიკის მიერ განხორციელებული ფუნქციების ნაკრები, რომელიც მოითხოვს დიდი რაოდენობით გამოთვლას, მაგალითად, დაშიფვრას, შეკუმშვას, ნიმუშის ამოცნობას. QuickAssist-ის მიზანია დეველოპერებისთვის საქმეები გაუადვილოს მათ ფუნქციური სამშენებლო ბლოკების მიწოდებით და მათი აპლიკაციების დაჩქარებით. მეორეს მხრივ, ტექნოლოგია საშუალებას გაძლევთ მიანდოთ "მძიმე" ამოცანები არა ყველაზე მძლავრ პროცესორებს, რაც განსაკუთრებით ღირებულია ჩაშენებულ სისტემებში, რომლებიც მკაცრად შეზღუდულია როგორც შესრულებაში, ასევე ენერგიის მოხმარებაში.
Intel სწრაფი რეზიუმე
Intel Viiv პლატფორმაზე დაფუძნებული კომპიუტერებისთვის შემუშავებული ტექნოლოგია, რომელიც საშუალებას აძლევს მათ ჩართონ და გამორთონ თითქმის მყისიერად, ტელევიზორის მიმღებების ან DVD ფლეერების მსგავსად; ამავდროულად, "გამორთული" მდგომარეობაში, კომპიუტერს შეუძლია განაგრძოს გარკვეული ამოცანების შესრულება, რომლებიც არ საჭიროებს მომხმარებლის ჩარევას. და მიუხედავად იმისა, რომ პლატფორმა თავისთავად შეუფერხებლად გადავიდა სხვა ფორმებში მასთან ერთად განვითარებულ მოვლენებთან ერთად, ხაზი კვლავ იმყოფება ARK-ში, რადგან ეს არც ისე დიდი ხნის წინ იყო.
Intel უსაფრთხო გასაღები
ზოგადი სახელი 32- და 64-ბიტიანი RDRAND ინსტრუქციებისთვის, რომლებიც იყენებენ ციფრული შემთხვევითი რიცხვების გენერატორის (DRNG) აპარატურულ განხორციელებას. ინსტრუქცია გამოიყენება კრიპტოგრაფიული მიზნებისთვის ლამაზი და მაღალი ხარისხის შემთხვევითი გასაღებების შესაქმნელად.
Intel TSX-NI
ტექნოლოგია რთული სახელწოდებით Intel Transactional Synchronization Extensions - New Instructions გულისხმობს პროცესორის ქეშის სისტემის დამატებას, რომელიც ოპტიმიზებს მრავალნაკადიანი აპლიკაციების შესრულების გარემოს, მაგრამ, რა თქმა უნდა, მხოლოდ იმ შემთხვევაში, თუ ეს აპლიკაციები იყენებენ TSX-NI პროგრამირების ინტერფეისებს. მომხმარებლის მხრიდან, ეს ტექნოლოგია პირდაპირ არ ჩანს, მაგრამ ყველას შეუძლია წაიკითხოს მისი აღწერა ხელმისაწვდომ ენაზე სტეპან კოლცოვის ბლოგზე.
დასასრულს, კიდევ ერთხელ შეგახსენებთ, რომ Intel ARK არსებობს არა მხოლოდ როგორც ვებგვერდი, არამედ როგორც ოფლაინ აპლიკაცია iOS-ისა და Android-ისთვის. დარჩით თემაში!
ჩვენ ვთარგმნით... თარგმნა ჩინური (გამარტივებული) ჩინური (ტრადიციული) ინგლისური ფრანგული გერმანული იტალიური იტალიური პორტუგალიური რუსული ესპანური თურქული
სამწუხაროდ, ჩვენ არ შეგვიძლია ამ ინფორმაციის თარგმნა ახლა - გთხოვთ, სცადოთ მოგვიანებით.
შესავალი
კომუნიკაციისა და მონაცემთა გადაცემისთვის შექმნილი პროგრამული უზრუნველყოფა საჭიროებს ძალიან მაღალ შესრულებას გადაცემისას უზარმაზარი თანხამცირე მონაცემთა პაკეტები. ვირტუალიზაციის აპლიკაციის განვითარების ერთ-ერთი მახასიათებელი ქსელის ფუნქციები(NFV) არის ის, რომ აუცილებელია ვირტუალიზაციის გამოყენება მაქსიმალურად, მაგრამ ამავე დროს საჭირო შემთხვევებიაპლიკაციების ოპტიმიზაცია გამოყენებული ტექნიკისთვის.
ამ სტატიაში მე გამოვყოფ Intel® პროცესორების სამ მახასიათებელს, რომლებიც სასარგებლოა NFV აპლიკაციების მუშაობის ოპტიმიზაციისთვის: ქეშის გამოყოფის ტექნოლოგიები (CAT), Intel® Advanced Vector Extensions 2 (Intel® AVX2) ვექტორული დამუშავებისთვის და Intel®. ტრანზაქციის სინქრონიზაციის გაფართოებები (Intel® TSX).
პრიორიტეტული ინვერსიის პრობლემის გადაჭრა CAT-ის გამოყენებით
როდესაც დაბალი პრიორიტეტის ფუნქცია იპარავს რესურსებს მაღალი პრიორიტეტული ფუნქციიდან, ჩვენ ამას ვუწოდებთ "პრიორიტეტის ინვერსიას".
Ყველა არა ვირტუალური ფუნქციებითანაბრად მნიშვნელოვანი. მაგალითად, მარშრუტიზაციის ფუნქცია მნიშვნელოვანია დამუშავების დროისა და შესრულებისთვის, ხოლო მედიის კოდირების ფუნქცია არც ისე მნიშვნელოვანია. ამ მახასიათებელს შეიძლება მიეცეს საშუალება პერიოდულად ჩამოაგდოს პაკეტები მომხმარებლის გამოცდილებაზე გავლენის გარეშე, რადგან მაინც ვერავინ შეამჩნევს ვიდეოს კადრების სიხშირის შემცირებას 20-დან 19 კადრამდე წამში.
ნაგულისხმევად, ქეში შექმნილია ისე, რომ ყველაზე აქტიური მომხმარებელი იღებს მის დიდ ნაწილს. მაგრამ ყველაზე აქტიური მომხმარებელი ყოველთვის არ არის ყველაზე მნიშვნელოვანი აპლიკაცია. სინამდვილეში, ხშირად საპირისპიროა. მაღალი პრიორიტეტული აპლიკაციები ოპტიმიზებულია, მათი მონაცემთა მოცულობა შემცირებულია უმცირეს შესაძლო კომპლექტამდე. დაბალი პრიორიტეტის აპლიკაციებს არ აქვთ დიდი ძალისხმევა მათ ოპტიმიზაციისთვის, ამიტომ ისინი მოიხმარენ მეტი მეხსიერება. ზოგიერთი ფუნქცია მოიხმარს დიდ მეხსიერებას. მაგალითად, პაკეტის ნახვის ფუნქცია სტატისტიკური ანალიზიაქვს დაბალი პრიორიტეტი, მაგრამ მოიხმარს დიდ მეხსიერებას და ძლიერ იყენებს ქეშს.
დეველოპერები ხშირად თვლიან, რომ თუ ისინი განათავსებენ ერთ მაღალ პრიორიტეტულ აპლიკაციას კონკრეტულ ბირთვში, მაშინ აპლიკაცია იქ უსაფრთხო იქნება და არ იმოქმედებს დაბალი პრიორიტეტის აპლიკაციებით. სამწუხაროდ, ეს ასე არ არის. თითოეულ ბირთვს აქვს საკუთარი 1 დონის ქეში (L1, ყველაზე სწრაფი, მაგრამ ყველაზე პატარა ქეში) და 2 დონის ქეში (L2, ოდნავ დიდი, მაგრამ ნელი). არსებობს ცალკეული L1 ქეში ზონები მონაცემებისთვის (L1D) და პროგრამის კოდისთვის (L1I, "I" ნიშნავს ინსტრუქციებს). მესამე დონის ქეში (ყველაზე ნელი) საერთოა ყველა პროცესორის ბირთვისთვის. Intel® პროცესორების არქიტექტურებზე ბროდველის ოჯახამდე და მათ შორის, L3 ქეში სრულად მოიცავს, რაც იმას ნიშნავს, რომ შეიცავს ყველაფერს, რაც შეიცავს L1 და L2 ქეშებში. ინკლუზიური ქეშის მუშაობის წესიდან გამომდინარე, თუ რამე წაიშლება მესამე დონის ქეშიდან, ის ასევე წაიშლება შესაბამისი პირველი და მეორე დონის ქეშიდან. ეს ნიშნავს, რომ დაბალი პრიორიტეტის აპლიკაციას, რომელსაც სივრცე სჭირდება L3 ქეშში, შეუძლია შეცვალოს მონაცემები მაღალი პრიორიტეტის აპლიკაციის L1 და L2 ქეშიდან, მაშინაც კი, თუ ის მუშაობს სხვა ბირთვზე.
წარსულში არსებობდა მიდგომა ამ პრობლემის გადასაჭრელად, სახელწოდებით „დათბობა“. როდესაც L3 ქეშზე წვდომა კონკურენციას უწევს, "გამარჯვებული" არის აპლიკაცია, რომელიც ყველაზე ხშირად წვდება მეხსიერებას. აქედან გამომდინარე, გამოსავალი არის მაღალი პრიორიტეტული ფუნქციის მუდმივად წვდომა ქეშზე, მაშინაც კი, როდესაც უმოქმედოა. ეს არ არის ძალიან ელეგანტური გადაწყვეტა, მაგრამ ხშირად საკმაოდ მისაღები იყო და ბოლო დრომდე ალტერნატივა არ არსებობდა. მაგრამ ახლა არის ალტერნატივა: Intel® Xeon® E5 v3 პროცესორების ოჯახმა შემოგვთავაზა ქეშის გამოყოფის ტექნოლოგია (CAT), რომელიც გაძლევთ შესაძლებლობას გამოყოთ ქეში აპლიკაციებისა და სერვისების კლასების საფუძველზე.
პრიორიტეტული ინვერსიის გავლენა
პრიორიტეტული ინვერსიის გავლენის დემონსტრირებისთვის, მე დავწერე მარტივი მიკროსკამი, რომელიც პერიოდულად აწარმოებს დაკავშირებული სიის გადაკვეთას მაღალი პრიორიტეტის ძაფზე, ხოლო დაბალი პრიორიტეტის თემა მუდმივად აწარმოებს მეხსიერების ასლის ფუნქციას. ეს ძაფები ენიჭება ერთი და იმავე პროცესორის სხვადასხვა ბირთვს. ეს სიმულაციას ახდენს ყველაზე უარესი სცენარირესურსებზე წვდომის წინააღმდეგობა: ასლის ოპერაცია მოითხოვს დიდ მეხსიერებას, ამიტომ, სავარაუდოდ, შეაფერხებს სიაში წვდომის უფრო მნიშვნელოვან თემას.
აქ არის კოდი C-ში.
// შექმენით N ზომის მიბმული სია ფსევდო შემთხვევითი ნიმუშით void init_pool(list_item *head, int N, int A, int B) ( int C = B; list_item *current = head; for (int i = 0; i< N - 1; i++) { current->tick = 0; C = (A*C + B) % N; მიმდინარე->შემდეგი = (სიის_პუნქტი*)&(ხელმძღვანელი[C]); მიმდინარე = მიმდინარე->შემდეგი; ) ) // შეეხეთ პირველ N ელემენტს დაკავშირებულ სიაში void warmup_list(list_item* მიმდინარე, int N) ( bool write = (N > POOL_SIZE_L2_LINES) ? true: false; for(int i = 0; i< N - 1; i++) { current = current->შემდეგი; თუ (ჩაწერე) მიმდინარე->მონიშვნა ++; ) ) ბათილი ზომა(სიის_პუნქტი* თავი, int N) ( ხელმოუწერელი __გრძელი i1, i2, საშუალო = 0; for (int j = 0; j< 50; j++) { list_item* current = head; #if WARMUP_ON while(in_copy) warmup_list(head, N); #else while(in_copy) spin_sleep(1); #endif i1 = __rdtsc(); for(int i = 0; i < N; i++) { current->tick++; მიმდინარე = მიმდინარე->შემდეგი; ) i2 = __rdtsc(); საშუალო += (i2-i1)/50; in_copy = true; ) შედეგები=საშ./ნ)
იგი შეიცავს სამ ფუნქციას.
- init_pool() ფუნქცია ახდენს გაერთიანებული სიის ინიციალიზებას დიდ გამოყოფილ თავისუფალ მეხსიერების არეალში მარტივი ფსევდო შემთხვევითი რიცხვების გენერატორის გამოყენებით. ეს ხელს უშლის სიის ელემენტების ერთმანეთთან ახლოს დგომას მეხსიერებაში, რაც შექმნის სივრცულ ადგილს, რაც გავლენას მოახდენს ჩვენს გაზომვებზე, რადგან ზოგიერთი ელემენტი ავტომატურად იქნება წინასწარ ამოღებული. სიის თითოეული ელემენტი არის ზუსტად ერთი ქეში ხაზი.
- warmup() ფუნქცია განუწყვეტლივ იმეორებს აგებულ სიას. არის სპეციფიკური მონაცემები, რომლებზეც საჭიროა წვდომა, რომლებიც უნდა იყოს ქეშში, ამიტომ ეს ფუნქცია ხელს უშლის სხვა ძაფებს შედგენილი სიის გამოდევნას L3 ქეშიდან.
- ზომა() ფუნქცია ზომავს სიის ერთი ელემენტის გავლას, შემდეგ ან იძინებს 1 მილიწამის განმავლობაში ან იძახებს warmup() ფუნქციას იმისდა მიხედვით, თუ რომელ ტესტს ვასრულებთ. ზომა() ფუნქცია აფასებს შედეგებს.
მიკრო ტესტის შედეგები Intel პროცესორი® Core™ i7 მე-5 თაობა ნაჩვენებია ქვემოთ მოცემულ გრაფიკზე, სადაც x-ღერძი არის ქეშის ხაზების მთლიანი რაოდენობა დაკავშირებულ სიაში, ხოლო y-ღერძი არის CPU ციკლების საშუალო რაოდენობა ბმულების სიაში წვდომაზე. როგორც დაკავშირებული სიის ზომა იზრდება, ის გადადის პირველი დონის მონაცემთა ქეშიდან მეორე და შემდეგ მესამე დონის ქეშში, შემდეგ კი მთავარ მეხსიერებაში.
ძირითადი მაჩვენებელი არის წითელ-ყავისფერი ხაზი, ის შეესაბამება პროგრამას მეხსიერებაში ასლის ძაფის გარეშე, ანუ კამათის გარეშე. ლურჯი ხაზი გვიჩვენებს პრიორიტეტის ინვერსიის შედეგებს: მეხსიერების ასლის ფუნქციის გამო სიაში წვდომას მნიშვნელოვნად მეტი დრო სჭირდება. გავლენა განსაკუთრებით დიდია, თუ სია ჯდება მაღალსიჩქარიან L1 ან L2 ქეშში. თუ სია იმდენად დიდია, რომ არ ჯდება მესამე დონის ქეშში, გავლენა უმნიშვნელოა.
მწვანე ხაზი აჩვენებს გახურების ეფექტს მეხსიერების ასლის ფუნქციის გაშვებისას: წვდომის დრო მკვეთრად მცირდება და უახლოვდება საბაზისო მნიშვნელობას.
თუ ჩვენ გავააქტიურებთ CAT-ს და გამოვყოფთ L3 ქეშის ნაწილებს თითოეულ ბირთვს ექსკლუზიური გამოყენებისთვის, შედეგები ძალიან ახლოს იქნება საწყისთან (ძალიან ახლოს არის დიაგრამაზე დასანახად), რაც ჩვენი მიზანია.
ჩართვაᲙᲐᲢᲐ
უპირველეს ყოვლისა, დარწმუნდით, რომ პლატფორმა მხარს უჭერს CAT-ს. შეგიძლიათ გამოიყენოთ CPUID ინსტრუქცია მისამართის ფურცლის 7-ის შემოწმებით, დამატებული ქვეფოთოლი 0, რათა მიუთითოთ CAT-ის ხელმისაწვდომობა.
თუ CAT ჩართულია და მხარდაჭერილია, არსებობს MSR რეგისტრები, რომლებიც შეიძლება დაპროგრამდეს L3 ქეშის სხვადასხვა ნაწილის სხვადასხვა ბირთვზე გამოყოფისთვის.
პროცესორის თითოეულ სოკეტს აქვს MSR რეგისტრები IA32_L3_MASKn (მაგალითად, 0xc90, 0xc91, 0xc92, 0xc93). ეს რეგისტრები ინახავს ბიტ ნიღაბს, რომელიც მიუთითებს, თუ რამდენი L3 ქეში უნდა გამოიყოს თითოეული კლასის სერვისისთვის (COS). 0xc90 ინახავს ქეშის განაწილებას COS0-სთვის, 0xc91 COS1-ისთვის და ა.შ.
მაგალითად, ეს დიაგრამა გვიჩვენებს რამდენიმე შესაძლო ბიტის ნიღბს მომსახურების სხვადასხვა კლასისთვის, რათა აჩვენოს, თუ როგორ შეიძლება გაიყოს ქეში: COS0 იღებს ნახევარს, COS1 იღებს მეოთხედს და COS2 და COS3 თითო მერვეს. მაგალითად, 0xc90 შეიცავს 11110000-ს, ხოლო 0xc93 შეიცავს 00000001-ს.
მონაცემთა პირდაპირი შეყვანის/გამოყვანის (DDIO) ალგორითმს აქვს საკუთარი დამალული ბიტის ნიღაბი, რომელიც საშუალებას აძლევს მონაცემთა ნაკადს მაღალსიჩქარიანი PCIe მოწყობილობებიდან, როგორიცაა ქსელის ადაპტერები, გადაიტანოს L3 ქეშის კონკრეტულ ადგილებში. არსებობს განსაზღვრული სერვისების კლასებთან კონფლიქტის პოტენციალი, ამიტომ ეს მხედველობაში უნდა იქნას მიღებული მაღალი გამტარუნარიანობის NFV აპლიკაციების შექმნისას. კონფლიქტების შესამოწმებლად გამოიყენეთ ქეში გამოტოვების გამოსავლენად. ზოგიერთ BIOS-ს აქვს პარამეტრი, რომელიც საშუალებას გაძლევთ ნახოთ და შეცვალოთ DDIO ნიღაბი.
თითოეულ ბირთვს აქვს MSR რეგისტრი IA32_PQR_ASSOC (0xc8f), რომელიც მიუთითებს სერვისის რომელი კლასი ვრცელდება ამ ბირთვზე. სერვისის ნაგულისხმევი კლასი არის 0, რაც ნიშნავს, რომ გამოიყენება MSR 0xc90 ბიტმასკი. (ნაგულისხმევად, bitmask 0xc90 დაყენებულია 1-ზე, რათა უზრუნველყოს ქეშის მაქსიმალური ხელმისაწვდომობა.)
Ყველაზე მარტივი მოდელი CAT-ის გამოყენება NFV-ში არის L3 ქეშის ნაწილების გამოყოფა სხვადასხვა ბირთვებზე იზოლირებული ბიტის ნიღბების გამოყენებით, შემდეგ კი ძაფების ან ვირტუალური მანქანების მინიჭება ბირთვებზე. თუ VM-ებს სჭირდებათ ბირთვების გაზიარება შესასრულებლად, ასევე შესაძლებელია ოპერაციული სისტემის გრაფიკის ტრივიალური შესწორება, ქეშის ნიღბის დამატება იმ ძაფებზე, რომლებზეც მუშაობენ VM-ები და დინამიურად ჩართოთ იგი დაგეგმვის ყველა ღონისძიებაზე.
არსებობს კიდევ ერთი უჩვეულო გზა CAT-ის გამოსაყენებლად მონაცემების ქეშში ჩასაკეტად. პირველი, შექმენით აქტიური ქეში ნიღაბი და შედით მეხსიერებაში არსებულ მონაცემებზე, რომ ჩატვირთოთ ისინი L3 ქეშში. შემდეგ გამორთეთ ბიტები, რომლებიც წარმოადგენს L3 ქეშის ამ ნაწილს ნებისმიერ CAT ბიტმასკში, რომელიც მომავალში იქნება გამოყენებული. მონაცემები დაიბლოკება მესამე დონის ქეშში, რადგან ახლა შეუძლებელია მისი გამოდევნა იქიდან (გარდა DDIO). NFV აპლიკაციაში, ეს მექანიზმი საშუალებას აძლევს საშუალო ზომის საძიებო ცხრილებს მარშრუტიზაციისთვის და პაკეტების ანალიზისთვის ჩაიკეტოს L3 ქეში, რათა უზრუნველყოს მუდმივი წვდომა.
Intel AVX2-ის გამოყენება ვექტორული დამუშავებისთვის
SIMD (ერთი ინსტრუქცია, ბევრი მონაცემი) ინსტრუქციები საშუალებას გაძლევთ ერთდროულად შეასრულოთ ერთი და იგივე ოპერაცია სხვადასხვა მონაცემებზე. ეს ინსტრუქციები ხშირად გამოიყენება მცურავი წერტილის გამოთვლების დასაჩქარებლად, მაგრამ ასევე ხელმისაწვდომია ინსტრუქციების მთელი, ლოგიკური და მონაცემთა ვერსიები.
თქვენს მიერ გამოყენებული პროცესორიდან გამომდინარე, თქვენთვის ხელმისაწვდომი გექნებათ SIMD ინსტრუქციების სხვადასხვა ოჯახი. ბრძანებებით დამუშავებული ვექტორის ზომა ასევე განსხვავდება:
- SSE მხარს უჭერს 128-ბიტიან ვექტორებს.
- Intel AVX2 მხარს უჭერს მთელი რიცხვის ინსტრუქციებს 256-ბიტიანი ვექტორებისთვის და ახორციელებს ინსტრუქციებს შეკრების ოპერაციებისთვის.
- AVX3 გაფართოებები მომავალ Intel® არქიტექტურებზე მხარს დაუჭერს 512-ბიტიან ვექტორებს.
ერთი 128-ბიტიანი ვექტორი შეიძლება გამოყენებულ იქნას ორი 64-ბიტიანი ცვლადი, ოთხი 32-ბიტიანი ცვლადი ან რვა 16-ბიტიანი ცვლადი (დამოკიდებულია გამოყენებული SIMD ინსტრუქციებზე). უფრო დიდი ვექტორები უფრო მეტ მონაცემთა ელემენტს დაიტევს. NFV აპლიკაციების მაღალი გამტარუნარიანობის მოთხოვნების გათვალისწინებით, თქვენ ყოველთვის უნდა გამოიყენოთ ყველაზე მეტი ძლიერი ინსტრუქციები SIMD (და მასთან დაკავშირებული აპარატურა), დღეს ეს არის Intel AVX2.
SIMD ინსტრუქციები ყველაზე ხშირად გამოიყენება მნიშვნელობების ვექტორზე იგივე ოპერაციის შესასრულებლად, როგორც ეს ნაჩვენებია სურათზე. აქ შექმნის ოპერაცია X1opY1-დან X4opY4-მდე არის ერთი ინსტრუქცია, რომელიც ერთდროულად ამუშავებს მონაცემთა ელემენტებს X1-დან X4-მდე და Y1-დან Y4-მდე. ამ მაგალითში დაჩქარება იქნება ოთხჯერ უფრო სწრაფი ვიდრე ნორმალური (სკალარული) შესრულება, რადგან ოთხი ოპერაცია ერთდროულად მუშავდება. სიჩქარე შეიძლება იყოს ისეთივე დიდი, როგორც დიდია SIMD ვექტორი. NFV აპლიკაციები ხშირად ამუშავებენ რამდენიმე პაკეტის ნაკადს იგივენაირად, ასე რომ, აქ SIMD ინსტრუქციები იძლევა საშუალებას ბუნებრივადშესრულების ოპტიმიზაცია.
მარტივი მარყუჟებისთვის, შემდგენელი ხშირად ავტომატურად ახდენს ოპერაციების ვექტორიზაციას მოცემული CPU-სთვის ხელმისაწვდომი უახლესი SIMD ინსტრუქციების გამოყენებით (თუ თქვენ იყენებთ სწორ კომპილერის დროშებს). თქვენ შეგიძლიათ თქვენი კოდის ოპტიმიზაცია, რათა გამოიყენოთ ყველაზე თანამედროვე ინსტრუქციების ნაკრები, რომელსაც მხარს უჭერს აპარატურა გაშვების დროს, ან შეგიძლიათ შეადგინოთ კოდი კონკრეტული სამიზნე არქიტექტურისთვის.
SIMD ოპერაციები ასევე მხარს უჭერს მეხსიერების დატვირთვას, კოპირება 32 ბაიტამდე (256 ბიტი) მეხსიერებიდან რეესტრში. ეს საშუალებას აძლევს მონაცემთა გადაცემას მეხსიერებასა და რეგისტრებს შორის, ქეშის გვერდის ავლით და მეხსიერების სხვადასხვა მდებარეობიდან მონაცემების შეგროვება. თქვენ ასევე შეგიძლიათ შეასრულოთ სხვადასხვა ოპერაციები ვექტორებით (მონაცემების შეცვლა ერთი რეესტრის ფარგლებში) და ვექტორების შენახვა (რეესტრიდან მეხსიერებაში 32 ბაიტამდე ჩაწერა).
Memcpy და memmov არის ძირითადი რუტინების ცნობილი მაგალითები, რომლებიც თავიდანვე განხორციელდა SIMD ინსტრუქციებით, რადგან REP MOV ინსტრუქცია ძალიან ნელი იყო. Memcpy კოდი რეგულარულად განახლდა სისტემის ბიბლიოთეკებიუახლესი SIMD ინსტრუქციების გამოსაყენებლად. CPUID მენეჯერის ცხრილი გამოიყენებოდა ინფორმაციის მისაღებად, თუ რომელი უახლესი ვერსიები იყო ხელმისაწვდომი გამოსაყენებლად. ამავდროულად, ბიბლიოთეკებში SIMD ინსტრუქციების ახალი თაობის განხორციელება, როგორც წესი, დაგვიანებულია.
მაგალითად, შემდეგი memcpy რუტინა, რომელიც იყენებს მარტივ მარყუჟს, ეფუძნება ჩაშენებულ ფუნქციებს (ბიბლიოთეკის კოდის ნაცვლად), ასე რომ შემდგენლს შეუძლია მისი ოპტიმიზაცია უახლესი ვერსია SIMD ინსტრუქციები.
Mm256_store_si256((__m256i*) (dest++), (__m256i*) (src++))
ის აწყობს შემდეგ ასამბლეის კოდს და აქვს ორჯერ მეტი შესრულება ბოლო ბიბლიოთეკებთან შედარებით.
C5 fd 6f 04 04 vmovdqa (%rsp,%rax,1),%ymm0 c5 fd 7f 84 04 00 00 vmovdqa %ymm0.0x10000(%rsp,%rax,1)
ასამბლეის კოდი inline ფუნქციიდან დააკოპირებს 32 ბაიტს (256 ბიტი) უახლესი ხელმისაწვდომი SIMD ინსტრუქციების გამოყენებით, ხოლო ბიბლიოთეკის კოდი SSE-ის გამოყენებით დააკოპირებს მხოლოდ 16 ბაიტს (128 ბიტი).
NFV აპლიკაციებს ხშირად სჭირდებათ შეგროვების ოპერაციების შესრულება მრავალი ადგილიდან მონაცემების ჩატვირთვით განსხვავებული ადგილებიარათანმიმდევრული მოგონებები. მაგალითად, ქსელურ ადაპტერს შეუძლია შემომავალი პაკეტების ქეშირება DDIO-ს გამოყენებით. NFV აპლიკაციას შეიძლება დასჭირდეს მხოლოდ ქსელის სათაურის დანიშნულების IP ნაწილზე წვდომა. შეგროვების ოპერაციით აპლიკაციას შეუძლია ერთდროულად შეაგროვოს მონაცემები 8 პაკეტისთვის.
არ არის საჭირო ინლაინ ფუნქციების ან ასამბლეის კოდის გამოყენება შეგროვების ოპერაციისთვის, რადგან შემდგენელს შეუძლია კოდის ვექტორიზაცია, როგორც ქვემოთ ნაჩვენები პროგრამისთვის, მეხსიერების ფსევდო შემთხვევითი მდებარეობების ტესტების შეჯამების საფუძველზე.
Int a; int b; ამისთვის (i = 0; i< 1024; i++) a[i] = i; for (i = 0; i < 64; i++) b[i] = (i*1051) % 1024; for (i = 0; i < 64; i++) sum += a]; // This line is vectorized using gather.
ბოლო ხაზი შედგენილია შემდეგ ასამბლეის კოდში.
C5 fe 6f 40 80 vmovdqu -0x80(%rax),%ymm0 c5 ed fe f3 vpaddd %ymm3,%ymm2,%ymm6 c5 e5 ef db vpxor %ymm3,%ymm3,%ymm3 c5 d5 76 ed %ymm5%, ymm5,%ymm5 c4 e2 55 90 3c a0 vpgatherdd %ymm5,(%rax,%ymm4,4),%ymm7
ერთი შეგროვების ოპერაცია მნიშვნელოვნად უფრო სწრაფია, ვიდრე ჩამოტვირთვების თანმიმდევრობა, მაგრამ ამას აზრი აქვს მხოლოდ იმ შემთხვევაში, თუ მონაცემები უკვე ქეშშია. წინააღმდეგ შემთხვევაში, მონაცემების მიღება მოუწევს მეხსიერებიდან, რაც მოითხოვს ასობით ან ათასობით CPU ციკლს. თუ მონაცემები ქეშშია, შესაძლებელია 10x სიჩქარის გაზრდა
(ანუ 1000%). თუ მონაცემები არ არის ქეშში, სიჩქარე მხოლოდ 5%-ია.
მსგავსი ტექნიკის გამოყენებისას მნიშვნელოვანია აპლიკაციის გაანალიზება, რათა გამოავლინოს შეფერხებები და გაიგოს, ატარებს თუ არა აპლიკაცია ძალიან დიდ დროს მონაცემთა კოპირებას ან შეგროვებას. შეგიძლიათ გამოიყენოთ.
კიდევ ერთი სასარგებლო ფუნქცია NFV-სთვის Intel AVX2-ში და სხვა SIMD ოპერაციებში არის ბიტი და ლოგიკური ოპერაციები. ისინი გამოიყენება არასტანდარტული დაშიფვრის კოდის დასაჩქარებლად, ხოლო ბიტის შემოწმება მოსახერხებელია ASN.1 დეველოპერებისთვის და ხშირად გამოიყენება ტელეკომუნიკაციებში მონაცემებისთვის. Intel AVX2 შეიძლება გამოყენებულ იქნას სიმებიანი უფრო სწრაფი შედარებისთვის, მოწინავე ალგორითმების გამოყენებით, როგორიცაა MPSSEF.
Intel AVX2 გაფართოებები კარგად მუშაობს ვირტუალურ მანქანებში. შესრულება იგივეა და არ არის მცდარი ვირტუალური აპარატის გასასვლელი.
Intel TSX-ის გამოყენება უფრო მაღალი მასშტაბურობისთვის
პარალელური პროგრამების ერთ-ერთი გამოწვევაა მონაცემთა შეჯახების თავიდან აცილება, რაც შეიძლება მოხდეს, როდესაც მრავალი ძაფი ცდილობს გამოიყენოს ერთი და იგივე მონაცემი და მინიმუმ ერთი ძაფი ცდილობს შეცვალოს მონაცემები. არაპროგნოზირებადი სიხშირის შედეგების თავიდან ასაცილებლად, გამოიყენება ჩაკეტვა: პირველი ძაფი, რომელიც იყენებს მონაცემთა ელემენტს, ბლოკავს მას სხვა ძაფებიდან სამუშაოს დასრულებამდე. მაგრამ ეს მიდგომა შეიძლება არ იყოს ეფექტური, თუ ხშირია კონკურენტული საკეტები ან თუ საკეტები აკონტროლებენ მეხსიერების უფრო დიდ არეალს, ვიდრე რეალურად საჭიროა.
Intel Transactional Synchronization Extensions (TSX) უზრუნველყოფს პროცესორის ინსტრუქციებიტექნიკის მეხსიერებაში ტრანზაქციის დროს დაბლოკვის გვერდის ავლით. ეს ხელს უწყობს უფრო მაღალი მასშტაბურობის მიღწევას. მისი მუშაობის გზა არის ის, რომ როდესაც პროგრამა შედის განყოფილებაში, რომელიც იყენებს Intel TSX-ს მეხსიერების მდებარეობების დასაცავად, მეხსიერების წვდომის ყველა მცდელობა ჩაიწერება და დაცული სესიის ბოლოს ისინი ავტომატურად ჩაიწერება ან ავტომატურად აბრუნებენ უკან. დაბრუნება შესრულებულია, თუ სხვა ძაფიდან შესრულებისას მოხდა მეხსიერების წვდომის კონფლიქტი, რამაც შეიძლება გამოიწვიოს რასის მდგომარეობა (მაგალითად, ჩაწერა იმ ადგილას, საიდანაც სხვა ტრანზაქცია კითხულობს მონაცემებს). უკან დაბრუნება ასევე შეიძლება მოხდეს, თუ მეხსიერებაზე წვდომის ჩანაწერი ძალიან დიდი გახდება Intel TSX განხორციელებისთვის, თუ არის I/O ინსტრუქცია ან სისტემური ზარი, ან თუ გამონაკლისები დაიშლება ან ვირტუალური მანქანები გამორთულია. I/O ზარები უკან იხევს, როდესაც მათი სპეკულაციური შესრულება შეუძლებელია გარე ჩარევის გამო. სისტემური ზარი არის ძალიან რთული ოპერაცია, რომელიც ცვლის რგოლებს და მეხსიერების სახელურებს და ძალიან რთულია უკან დაბრუნება.
Intel TSX-ის ჩვეულებრივი გამოყენების შემთხვევაა წვდომის კონტროლი ჰეშ მაგიდაზე. როგორც წესი, ქეში ცხრილის ჩაკეტვა გამოიყენება ქეშის ცხრილზე წვდომის გარანტირებისთვის, მაგრამ ეს ზრდის წვდომისთვის კონკურენციის ძაფების შეყოვნებას. ჩაკეტვა ხშირად ზედმეტად უხეშია: მთელი მაგიდა ჩაკეტილია, თუმცა ძალზე იშვიათია ძაფები იმავე ელემენტებზე წვდომისთვის. ბირთვების (და ძაფების) რაოდენობის მატებასთან ერთად, უხეში ჩაკეტვა აფერხებს მასშტაბურობას.
როგორც ქვემოთ მოცემულ დიაგრამაზეა ნაჩვენები, უხეში ბლოკირებამ შეიძლება გამოიწვიოს ერთი ძაფი დაელოდოს მეორე ძაფს ჰეშის ცხრილის გასათავისუფლებლად, მიუხედავად იმისა, რომ ძაფები იყენებენ სხვადასხვა ელემენტებს. Intel TSX-ის გამოყენება საშუალებას აძლევს ორივე ძაფს იმუშაოს, მათი შედეგები ჩაიწერება გარიგების დასრულების შემდეგ წარმატებით. აპარატურა აღმოაჩენს კონფლიქტებს და აჩერებს შეურაცხმყოფელ ტრანზაქციებს. Intel TSX-ის გამოყენებისას ძაფს 2 არ სჭირდება ლოდინი, ორივე ძაფები გაცილებით ადრე სრულდება. ჰეშის ცხრილებზე ჩაკეტვა გარდაიქმნება სრულყოფილად მორგებულ ჩაკეტვაში, რაც იწვევს გაუმჯობესებულ შესრულებას. Intel TSX მხარს უჭერს კონფლიქტის თვალთვალის სიზუსტეს ერთი ქეში ხაზის დონეზე (64 ბაიტი).
Intel TSX იყენებს ორ პროგრამირების ინტერფეისს ტრანზაქციების შესასრულებლად კოდის სექციების დასაზუსტებლად.
- Hardware Lock Bypass (HLE) უკუთავსებადია და მისი ადვილად გამოყენება შესაძლებელია მასშტაბურობის გასაუმჯობესებლად საკეტის ბიბლიოთეკაში მნიშვნელოვანი ცვლილებების განხორციელების გარეშე. HLE-ს ახლა აქვს პრეფიქსები დაბლოკილი ინსტრუქციებისთვის. HLE ინსტრუქციის პრეფიქსი სიგნალს აძლევს აპარატურას, რომ დააკვირდეს საკეტის მდგომარეობას მისი შეძენის გარეშე. ზემოთ მოყვანილ მაგალითში აღწერილი ნაბიჯების გადადგმა უზრუნველყოფს, რომ ჰეშის ცხრილის სხვა ჩანაწერებზე წვდომა აღარ გამოიწვევს დაბლოკვას, თუ არ იქნება კონფლიქტური ჩაწერის წვდომა ჰეშის ცხრილში შენახულ მნიშვნელობაზე. შედეგად, წვდომა პარალელიზდება, ასე რომ მასშტაბურობა გაიზრდება ოთხივე ძაფზე.
- RTM ინტერფეისი შეიცავს აშკარა ინსტრუქციებს დაწყების (XBEGIN), ჩადენის (XEND), გაუქმების (XABORT) და ტრანზაქციების მდგომარეობის (XTEST) შესამოწმებლად. ეს ინსტრუქციები ჩაკეტილ ბიბლიოთეკებს აძლევს უფრო მოქნილ გზას ჩაკეტვის გვერდის ავლით განსახორციელებლად. RTM ინტერფეისი საშუალებას აძლევს ბიბლიოთეკებს გამოიყენონ მოქნილი ალგორითმებიტრანზაქციების გაუქმება. ეს ფუნქცია შეიძლება გამოყენებულ იქნას Intel TSX-ის მუშაობის გასაუმჯობესებლად ოპტიმისტური ტრანზაქციის გადატვირთვის, ტრანზაქციის უკან დაბრუნებისა და სხვა მოწინავე ტექნიკის გამოყენებით. CPUID ინსტრუქციის გამოყენებით, ბიბლიოთეკას შეუძლია დაუბრუნდეს არა-RTM საკეტების ძველ იმპლემენტაციას, შეინარჩუნოს უკან თავსებადიმომხმარებლის დონის კოდით.
- მისაღებად დამატებითი ინფორმაციაგირჩევთ წაიკითხოთ შემდეგი სტატიები Intel Developer Zone პორტალზე HLE და RTM-ის შესახებ.
სინქრონიზაციის პრიმიტივების ოპტიმიზაციის მსგავსად HLE ან RTM-ის გამოყენებით, NFV მონაცემთა გეგმის ფუნქციებს შეუძლიათ ისარგებლონ Intel TSX-ისგან მონაცემთა თვითმფრინავის განვითარების ნაკრების (DPDK) გამოყენებისას.
Intel TSX-ის გამოყენებისას მთავარი გამოწვევა არის არა ამ გაფართოებების განხორციელება, არამედ მათი შესრულების შეფასება და განსაზღვრა. არსებობს შესრულების მრიცხველები, რომლებიც შეიძლება გამოყენებულ იქნას Linux* perf პროგრამებში და Intel TSX-ის შესრულების წარმატების გასაზომად (შესრულებული მარყუჟების რაოდენობა და შეწყვეტილი მარყუჟების რაოდენობა).
Intel TSX უნდა იქნას გამოყენებული სიფრთხილით და ყურადღებით შემოწმებული NFV აპლიკაციებში, რადგან I/O ოპერაციები Intel TSX-ის მიერ დაცულ ზონაში ყოველთვის მოიცავს უკან დაბრუნებას და ბევრი NFV ფუნქცია იყენებს უამრავ I/O ოპერაციებს. ერთდროული ჩაკეტვა თავიდან უნდა იქნას აცილებული NFV აპლიკაციებში. თუ საკეტები აუცილებელია, მაშინ დაბლოკვის შემოვლითი ალგორითმები ხელს შეუწყობს მასშტაბურობის გაუმჯობესებას.
ავტორის შესახებ
ალექსანდრე კომაროვი მუშაობს აპლიკაციების განვითარების ინჟინრად Intel Corporation-ის პროგრამული უზრუნველყოფისა და სერვისების ჯგუფში. ბოლო 10 წლის განმავლობაში, ალექსანდრეს მთავარი სამუშაო იყო კოდის ოპტიმიზაცია, რათა მიაღწიოს მაქსიმალურ შესრულებას არსებულ და მომავალზე სერვერის პლატფორმებიინტელი. ეს ნამუშევარი მოიცავს Intel-ის პროგრამული უზრუნველყოფის განვითარების ინსტრუმენტების გამოყენებას, როგორიცაა პროფილები, შემდგენელები, ბიბლიოთეკები, უახლესი ინსტრუქციების ნაკრები, ნანოარქიტექტურა და არქიტექტურული გაუმჯობესებები უახლესი x86 პროცესორებისა და ჩიპსეტებისთვის.
დამატებითი ინფორმაცია
NFV-ის შესახებ მეტი ინფორმაციისთვის იხილეთ შემდეგი ვიდეოები.
თარიღი: 2014-08-13 22:26
ჯერ კიდევ 2007 წელს AMD-მ გამოუშვა ახალი თაობის Phenom პროცესორები. ეს პროცესორები, როგორც მოგვიანებით გაირკვა, შეიცავდა შეცდომას TLB ბლოკში (თარგმნის გვერდის ბუფერი, ვირტუალური მისამართების ფიზიკურად სწრაფად გადაქცევის ბუფერი). კომპანიას სხვა გზა არ ჰქონდა, გარდა ამ პრობლემის გადასაჭრელად BIOS პაჩის სახით პატჩის საშუალებით, მაგრამ ამან შეამცირა პროცესორის მუშაობა დაახლოებით 15%-ით.
მსგავსი რამ ახლა დაემართა Intel-ს. Haswell-ის თაობის პროცესორებში კომპანიამ დანერგა TSX (Transactional Synchronization Extension) ინსტრუქციების მხარდაჭერა. ისინი შექმნილია მრავალ ხრახნიანი აპლიკაციების დასაჩქარებლად და უნდა ყოფილიყო გამოყენებული ძირითადად სერვერის სეგმენტში. იმისდა მიუხედავად, რომ Haswell CPU-ები საკმაოდ დიდი ხანია ბაზარზეა, ეს ინსტრუქციის ნაკრები თითქმის არ არის გამოყენებული. როგორც ჩანს, ეს უახლოეს მომავალში არ მოხდება.
ფაქტია, რომ Intel-მა დაუშვა "ტექსტური შეცდომა", როგორც თავად კომპანია უწოდებს, TSX ინსტრუქციებში. შეცდომა, სხვათა შორის, პროცესორის გიგანტის სპეციალისტებმა ვერ აღმოაჩინეს. ამან შეიძლება გამოიწვიოს სისტემის არასტაბილურობა. გადაწყვიტე ეს პრობლემაკომპანიას შეუძლია ამის გაკეთება მხოლოდ ერთი გზით, BIOS-ის განახლებით, რაც გამორთავს ინსტრუქციების ამ კომპლექტს.
სხვათა შორის, TSX დანერგილია არა მხოლოდ Haswell პროცესორებში, არამედ Broadwell CPU-ის პირველ მოდელებშიც, რომლებიც უნდა გამოჩნდეს Core M-ის სახელით. კომპანიის წარმომადგენელმა დაადასტურა, რომ Intel აპირებს განახორციელოს TSX ინსტრუქციების "შეცდომის გარეშე" ვერსია. მომავალ პროდუქტებში.
ტეგები: კომენტარი
წინა სიახლე
2014-08-13 22:23
Sony Xperia Z2 "გადარჩა" ექვსკვირიანი ყოფნის შემდეგ მარილიანი აუზის ფსკერზე
სმარტფონები ხშირად ხდებიან წარმოუდგენელი ისტორიების გმირები, რომლებშიც ისინი ცდილობენ ჯიბის ჯავშნის როლს, შეაჩერონ ტყვია და დაზოგონ.
2014-08-13 21:46
IPhone 6 გადავიდა ტესტირების დასკვნით ეტაპზე
საინფორმაციო სააგენტო Gforgames-ის უახლესი მონაცემებით, iPhone 6 ახალი სმარტფონის წარმოებაში მასობრივ გაშვებამდე ტესტირების საბოლოო ეტაპზე შევიდა. შეგახსენებთ, რომ iPhone 6 ჩინეთში ქარხნებში აწყობილი...
2014-08-12 16:38
რვა ბირთვიანი iRU M720G ტაბლეტი მხარს უჭერს ორ სიმ ბარათს
ტაბლეტს აქვს 2 GB ოპერატიული მეხსიერება და 16 GB ჩაშენებული ფლეშ მეხსიერება. ბორტზე ორი კამერაა: მთავარი 8 მეგაპიქსელიანი და წინა 2 მეგაპიქსელიანი. iRU M720G აღჭურვილია 3G, GPS, Wi-Fi, Bluetooth, FM რადიო მოდულებით, ასევე ორი SIM ბარათის სლოტით, რაც საშუალებას აძლევს მას შეასრულოს...
2014-08-10 18:57
LG-მ რუსეთში გამოუშვა იაფი სმარტფონი L60
დიდი პომპეზურობისა და აურზაურის გარეშე, LG Electronics-მა რუსეთში წარადგინა L სერიის III ახალი მოდელი - LG L60. ეს იაფი სმარტფონი წარმოდგენილია ფასის დიაპაზონში 4-დან 5 ათას რუბლამდე უმსხვილესი რუსულიდან...
#ქსეონისაკმაოდ ხშირად ერთპროცესორიანი სერვერის არჩევისას ან სამუშაო სადგურიჩნდება კითხვა, რომელი პროცესორი გამოვიყენოთ - სერვერი Xeon თუ ჩვეულებრივი Core ix. იმის გათვალისწინებით, რომ ეს პროცესორები აგებულია ერთსა და იმავე ბირთვებზე, არჩევანი საკმაოდ ხშირად მოდის დესკტოპის პროცესორებზე, რომლებსაც ჩვეულებრივ აქვთ დაბალი ღირებულება მსგავსი შესრულებით. რატომ უშვებს Intel Xeon E3 პროცესორებს? მოდი გავარკვიოთ.
სპეციფიკაციები
დასაწყისისთვის, ავიღოთ Xeon პროცესორის უმცროსი მოდელი ამჟამინდელი მოდელის დიაპაზონიდან - Xeon E3-1220 V3. მეტოქე იქნება ძირითადი პროცესორი i5-4440. ორივე პროცესორი დაფუძნებულია Haswell ბირთვზე, აქვს იგივე ბაზის საათის სიჩქარე და მსგავსი ფასები. ამ ორ პროცესორს შორის განსხვავებები მოცემულია ცხრილში:ინტეგრირებული გრაფიკის ხელმისაწვდომობა. ერთი შეხედვით Core i5-ს აქვს უპირატესობა, მაგრამ ყველა სერვერს დედაპლატებიაქვს ჩაშენებული ვიდეო ბარათი, რომელიც არ არის საჭირო გრაფიკული ჩიპიპროცესორში და სამუშაო სადგურები, როგორც წესი, არ იყენებენ ინტეგრირებულ გრაფიკას მათი შედარებით დაბალი შესრულების გამო.
ECC მხარდაჭერა. მაღალი სიჩქარე და დიდი რაოდენობით ოპერატიული მეხსიერება ზრდის ალბათობას პროგრამული შეცდომები. როგორც წესი, ასეთი შეცდომები უხილავია, მაგრამ ამის მიუხედავად, მათ შეუძლიათ გამოიწვიონ მონაცემების ცვლილებები ან სისტემის ავარია. თუ ასეთი შეცდომები არ არის საშიში დესკტოპის კომპიუტერებისთვის მათი იშვიათი შემთხვევის გამო, მაშინ ისინი მიუღებელია სერვერებზე, რომლებიც მუშაობენ მთელი საათის განმავლობაში რამდენიმე წლის განმავლობაში. მათ გამოსასწორებლად გამოიყენება ECC (error-correcting code) ტექნოლოგია, რომლის ეფექტურობა 99,988%-ია.
თერმული დიზაინის სიმძლავრე (TDP). არსებითად, პროცესორის ენერგიის მოხმარება მაქსიმალური დატვირთვით. ქსეონებს, როგორც წესი, აქვთ უფრო მცირე თერმული კონვერტი და ენერგიის დაზოგვის უფრო ჭკვიანი ალგორითმები, რაც საბოლოო ჯამში იწვევს ელექტროენერგიის დაბალ გადასახადს და უფრო ეფექტურ გაგრილებას.
L3 ქეში. ქეში მეხსიერება არის ერთგვარი ფენა პროცესორსა და RAM-ს შორის, რომელსაც აქვს ძალიან მაღალი სიჩქარე. რაც უფრო დიდია ქეშის ზომა, მით უფრო სწრაფად მუშაობს პროცესორი, რადგან ძალიან სწრაფი ოპერატიული მეხსიერებაც კი მნიშვნელოვნად ნელია ვიდრე ქეშ მეხსიერება. Xeon პროცესორებს, როგორც წესი, უფრო დიდი ქეში აქვთ, რაც მათ უპირატესობას ანიჭებს რესურსზე ინტენსიური აპლიკაციებისთვის.
სიხშირე / სიხშირე TurboBoost რეჟიმში. აქ ყველაფერი მარტივია - რაც უფრო მაღალია სიხშირე, მით უფრო სწრაფად მუშაობს პროცესორი, ყველა სხვა თანაბარია. საბაზისო სიხშირე, ანუ სიხშირე, რომლითაც პროცესორები მუშაობენ სრული დატვირთვით, იგივეა, მაგრამ Turbo Boost რეჟიმში, ანუ აპლიკაციებთან მუშაობისას, რომლებიც არ არის განკუთვნილი მრავალბირთვიანი პროცესორები Xeon უფრო სწრაფია.
Intel TSX-NI მხარდაჭერა. Intel ტრანზაქციის სინქრონიზაციის გაფართოებები ახალი ინსტრუქციები (Intel TSX-NI) არის დანამატი პროცესორის ქეშის სისტემაში, რომელიც ოპტიმიზირებს მრავალნაკადიანი აპლიკაციების შესრულების გარემოს, მაგრამ, რა თქმა უნდა, მხოლოდ იმ შემთხვევაში, თუ ეს აპლიკაციები იყენებენ TSX-NI პროგრამირების ინტერფეისებს. TSX-NI ინსტრუქციის ნაკრები საშუალებას გაძლევთ უფრო ეფექტურად განახორციელოთ მუშაობა Დიდი მონაცემებიდა მონაცემთა ბაზები - იმ შემთხვევებში, როდესაც რამდენიმე ძაფს აქვს წვდომა ერთსა და იმავე მონაცემებზე და წარმოიქმნება თემების დაბლოკვის სიტუაციები. მონაცემების სპეკულაციური წვდომა, რომელიც დანერგილია TSX-ში, საშუალებას გაძლევთ შექმნათ ასეთი აპლიკაციები უფრო ეფექტურად და უფრო დინამიურად გააფართოვოთ შესრულება ერთდროულად შესრულებული ძაფების რაოდენობის გაზრდისას, კონფლიქტების მოგვარებით, საერთო მონაცემებზე წვდომისას.

სანდო აღსრულების მხარდაჭერა. ინტელის ტექნოლოგია Trusted Execution აძლიერებს ბრძანებების უსაფრთხო შესრულებას Intel-ის პროცესორებისა და ჩიპსეტების ტექნიკის გაუმჯობესების გზით. ეს ტექნოლოგია ციფრულ საოფისე პლატფორმებს უზრუნველყოფს უსაფრთხოების ფუნქციებით, როგორიცაა აპლიკაციის გაზომილი გაშვება და ბრძანების უსაფრთხო შესრულება. ეს მიიღწევა ისეთი გარემოს შექმნით, სადაც აპლიკაციები მუშაობს სისტემის სხვა აპლიკაციებისგან იზოლირებულად.
სარგებლისკენ Xeon პროცესორებიძველ მოდელებს შეუძლიათ კიდევ უფრო მეტი L3 მოცულობის დამატება, 45 მბ-მდე, დიდი რაოდენობითბირთვი, 18-მდე და მეტი მხარდაჭერილი ოპერატიული მეხსიერება, 768 გბ-მდე თითო პროცესორზე. ამავე დროს, მოხმარება არ აღემატება 160 ვტ. ერთი შეხედვით, ეს ძალიან დიდი მნიშვნელობაა, თუმცა იმის გათვალისწინებით, რომ ასეთი პროცესორების შესრულება რამდენჯერმე აღემატება იგივე Xeon E3-1220 V3-ის შესრულებას 80 ვტ TDP-ით, დანაზოგი აშკარა ხდება. აქვე უნდა აღინიშნოს, რომ Core ოჯახის არც ერთი პროცესორი არ უჭერს მხარს მრავალპროცესს, ანუ შესაძლებელია ერთ კომპიუტერში არაუმეტეს ერთი პროცესორის დაყენება. უმეტესობააპლიკაციები სერვერებისა და სამუშაო სადგურებისთვის შესანიშნავად მასშტაბირდება ბირთვებში, ძაფებში და ფიზიკური პროცესორებიასე რომ, ორი პროცესორის დაყენება თითქმის ორჯერ გაზრდის შესრულებას.