Omega intitule toutes les publications des utilisateurs. Recherchez des mots à l'aide d'opérateurs supplémentaires. Qu'est-ce que la recherche avancée
Dernière fois nous l'avons regardé, mais cette fois je vais vous dire comment supprimer déchets informatiques manuellement, en utilisant Outils Windows et des programmes.
1. Tout d'abord, regardons où les déchets sont stockés dans les systèmes d'exploitation.
Sous Windows XP
Nous entrons et supprimons tout dans les dossiers : Fichiers temporaires Windows :
- C:\Documents and Settings\nom d'utilisateur\Paramètres locaux\Historique
- C:\Windows\Temp
- C:\Documents and Settings\nom d'utilisateur\Paramètres locaux\Temp
- C:\Documents and Settings\Utilisateur par défaut\Paramètres locaux\Historique
Pour Windows 7 et 8
Fichiers temporaires Windows :
- C:\Windows\Temp
- C:\Utilisateurs\Nom d'utilisateur\AppData\Local\Temp
- C:\Utilisateurs\Tous les utilisateurs\TEMP
- C:\Utilisateurs\Tous les utilisateurs\TEMP
- C:\Utilisateurs\Default\AppData\Local\Temp
Cache du navigateur
Cache d'opéra :
- C:\users\username\AppData\Local\Opera\Opera\cache\
Cache Mozilla :
- C:\Utilisateurs\nom d'utilisateur\AppData\Local\Mozilla\Firefox\Profiles\ dossier\Cache
Cache Google Chrome:
- C:\Utilisateurs\nom d'utilisateur\AppData\Local\Bromium\User Data\Default\Cache
- C:\Users\User\AppData\Local\Google\Chrome\User Data\Default\Cache
Ou entrez-le dans l'adresse chrome://version/ et voir le chemin d'accès au profil. Il y aura un dossier là-bas Cache
Fichiers Internet temporaires :
- C:\Utilisateurs\nom d'utilisateur\AppData\Local\Microsoft\Windows\Fichiers Internet temporaires\
Documents récents :
- C:\Utilisateurs\nom d'utilisateur\AppData\Roaming\Microsoft\Windows\Recent\
Certains dossiers peuvent être cachés aux regards indiscrets. Pour leur montrer, vous avez besoin.
2. Nettoyer le disque des fichiers temporaires et inutilisés à l'aide
Outil de nettoyage de disque standard
1. Allez dans « Démarrer » -> « Tous les programmes » -> « Accessoires » -> « Outils système » et exécutez le programme « Nettoyage de disque ».
2. Sélectionnez le disque à nettoyer :

Le processus d'analyse du disque va commencer...
3. Une fenêtre s'ouvrira avec des informations sur la quantité d'espace occupée par les fichiers temporaires :

Cochez les cases à côté des partitions que vous souhaitez effacer et cliquez sur OK.
4. Mais ça pas encore tout. Si vous avez installé Windows 7 non pas sur un disque vierge, mais sur un système d'exploitation précédemment installé, vous disposez probablement de dossiers gourmands en espace tels que Windows.old ou $WINDOWS.~Q.
De plus, il peut être judicieux de supprimer les points de contrôle de restauration du système (sauf le dernier). Pour effectuer cette opération, répétez les étapes 1 à 3, mais cette fois cliquez sur « Nettoyer les fichiers système » :

5. Après la procédure décrite à l'étape 2, la même fenêtre s'ouvrira, mais l'onglet « Avancé » apparaîtra en haut. Allez-y.

Sous Restauration du système et clichés instantanés, cliquez sur Nettoyer.
3. Fichiers pagefile.sys et hiberfil.sys
Les fichiers sont situés à la racine du disque système et occupent beaucoup d'espace.
1. Le fichier pagefile.sys est fichier d'échange système(mémoire virtuelle). Vous ne pouvez pas le supprimer (il n'est pas non plus recommandé de le réduire), mais vous pouvez et même devez le déplacer vers un autre disque.
Cela se fait très simplement, ouvrez « Panneau de configuration - Système et sécurité - Système », sélectionnez « Paramètres système avancés » dans la section « Performances », cliquez sur « Options », passez à l'onglet « Avancé » (ou appuyez sur win + R combinaison de touches, la commande « exécuter » s'ouvrira et tapez là SystemPropertiesAdvanced) et dans la section « Mémoire virtuelle », cliquez sur « Modifier ». Là, vous pouvez sélectionner l'emplacement du fichier d'échange et sa taille (je recommande de laisser « Taille telle que sélectionnée par le système »).
4. Suppression des programmes inutiles du disque
Un bon moyen de libérer de l'espace disque (et, en prime, d'augmenter les performances du système) consiste à supprimer les programmes que vous n'utilisez pas.

Accédez au Panneau de configuration et sélectionnez « Désinstaller les programmes ». Une liste apparaîtra dans laquelle vous pourrez sélectionner le programme que vous souhaitez supprimer et cliquer sur « Supprimer ».
5. Défragmentation
La défragmentation d'un disque dur, effectuée par un programme de défragmentation, permet d'organiser le contenu des clusters, c'est-à-dire de les déplacer sur le disque afin que les clusters avec le même fichier soient placés séquentiellement et que les clusters vides soient combinés. Cela conduit pour augmenter la vitesse accès aux fichiers, et donc à une certaine augmentation des performances de l'ordinateur, ce qui à haut niveau fragmentation le disque peut s'avérer être assez visible. Le programme de défragmentation de disque standard se trouve dans : démarrer> tous les programmes> standard> utilitaires> défragmenteur de disque
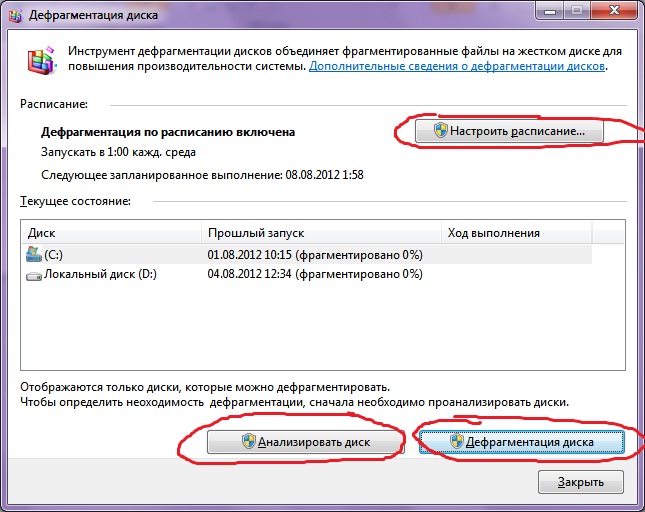
Voilà à quoi ressemble le programme. Dans lequel vous pouvez analyser disque, où le programme affichera un diagramme de fragmentation du disque et vous indiquera si vous devez ou non défragmenter. Vous pouvez également définir un calendrier de défragmentation du disque. Il s'agit d'un programme intégré à Windows ; il existe également des programmes de défragmentation de disque distincts, par exemple que vous pouvez télécharger ici :

Son interface est également assez simple.

Voici ses avantages par rapport au programme standard :

- Analyse avant défragmentation du disque Effectuez une analyse du disque avant de défragmenter. Après l'analyse, une boîte de dialogue s'affiche avec un diagramme montrant le pourcentage de fichiers et de dossiers fragmentés sur le disque et une recommandation d'action. Il est recommandé d'effectuer une analyse régulièrement et une défragmentation uniquement après les recommandations appropriées d'un programme de défragmentation de disque. Il est recommandé d'effectuer une analyse de disque au moins une fois par semaine. Si le besoin de défragmentation se produit rarement, l'intervalle d'analyse du disque peut être augmenté jusqu'à un mois.
- Analyse après ajout d'un grand nombre de fichiers Après avoir ajouté un grand nombre de fichiers ou de dossiers, les disques peuvent devenir excessivement fragmentés, c'est pourquoi dans de tels cas, il est recommandé de les analyser.
- Vérifier que vous disposez d'au moins 15 % d'espace disque libre Pour défragmenter complètement et correctement à l'aide du Défragmenteur de disque, le disque doit disposer d'au moins 15 % d'espace libre. Le Défragmenteur de disque utilise ce volume comme zone pour trier les fragments de fichiers. Si la quantité est inférieure à 15 % de l'espace libre, le Défragmenteur de disque n'effectuera qu'une défragmentation partielle. Pour libérer de l'espace disque supplémentaire, supprimez les fichiers inutiles ou déplacez-les vers un autre disque.
- Défragmentation après l'installation d'un logiciel ou l'installation de Windows Défragmentez les lecteurs après avoir installé un logiciel ou après avoir effectué une mise à jour ou une nouvelle installation de Windows. Les disques sont souvent fragmentés après l'installation d'un logiciel. L'exécution du Défragmenteur de disque peut donc contribuer à garantir des performances optimales du système de fichiers.
- Gagnez du temps sur la défragmentation du disque Vous pouvez gagner un peu de temps nécessaire à la défragmentation si vous supprimez les fichiers indésirables de votre ordinateur avant de démarrer l'opération, et excluez également les fichiers système pagefile.sys et hiberfil.sys, qui sont utilisés par le système comme fichiers tampon temporaires et sont recréés au début de chaque session Windows.
6. Supprimez les éléments inutiles du démarrage
7. Supprimez tout ce qui est inutile
Eh bien, je pense que vous savez par vous-même ce dont vous n'avez pas besoin sur votre bureau. Et vous pouvez lire comment l'utiliser. , une procédure très importante, alors ne l’oubliez pas !
Le moteur de recherche Google (www.google.com) propose de nombreuses options de recherche. Toutes ces fonctionnalités constituent un outil de recherche inestimable pour un utilisateur novice sur Internet et en même temps une arme d'invasion et de destruction encore plus puissante entre les mains de personnes mal intentionnées, notamment des pirates informatiques, mais également des criminels non informatiques et même des terroristes.
(9475 vues en 1 semaine)
Denis Barankov
denisNOSPAMixi.ru
Attention:Cet article n’est pas un guide d’action. Cet article a été écrit pour vous, administrateurs de serveurs WEB, afin que vous perdiez le faux sentiment d'être en sécurité, et que vous compreniez enfin le caractère insidieux de cette méthode d'obtention d'informations et que vous preniez la tâche de protéger votre site.
Introduction
Par exemple, j'ai trouvé 1670 pages en 0,14 seconde !
2. Entrons une autre ligne, par exemple :
inurl : "auth_user_file.txt"un peu moins, mais c'est déjà suffisant pour le téléchargement gratuit et la recherche de mots de passe (en utilisant le même John The Ripper). Ci-dessous, je donnerai un certain nombre d'autres exemples.
Vous devez donc comprendre que le moteur de recherche Google a visité la plupart des sites Internet et mis en cache les informations qu'ils contiennent. Ces informations mises en cache vous permettent d'obtenir des informations sur le site et le contenu du site sans vous connecter directement au site, uniquement en fouillant dans les informations stockées dans Google. De plus, si les informations présentes sur le site ne sont plus disponibles, alors les informations présentes dans le cache peuvent encore être conservées. Tout ce dont vous avez besoin pour cette méthode est de connaître quelques mots-clés Google. Cette technique s'appelle Google Hacking.
Les informations sur Google Hacking sont apparues pour la première fois sur la liste de diffusion Bugtruck il y a 3 ans. En 2001, ce sujet a été évoqué par un étudiant français. Voici un lien vers cette lettre http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html. Il fournit les premiers exemples de telles requêtes :
1) Index de /admin
2) Index du /mot de passe
3) Index du /mail
4) Index des / +banques +filetype:xls (pour la france...)
5) Index de / + mot de passe
6) Index de / password.txt
Ce sujet a fait sensation dans la partie anglophone d'Internet assez récemment : d'après l'article de Johnny Long, publié le 7 mai 2004. Pour une étude plus complète sur Google Hacking, je vous conseille d’aller sur le site de cet auteur http://johnny.ihackstuff.com. Dans cet article, je veux juste vous mettre au courant.
Qui peut l'utiliser :
- Les journalistes, les espions et tous ceux qui aiment mettre le nez dans les affaires des autres peuvent l'utiliser pour rechercher des preuves incriminantes.
- Les pirates informatiques recherchent des cibles appropriées pour le piratage.
Comment fonctionne Google.
Pour poursuivre la conversation, permettez-moi de vous rappeler certains mots-clés utilisés dans les requêtes Google.
Rechercher en utilisant le signe +
Google exclut des recherches les mots qu’il considère comme sans importance. Par exemple, des mots interrogatifs, des prépositions et des articles en anglais : par exemple sont, de, où. En russe, Google semble considérer tous les mots comme importants. Si un mot est exclu de la recherche, Google l'écrit. Pour que Google commence à rechercher des pages contenant ces mots, vous devez ajouter un signe + sans espace avant le mot. Par exemple:
as + de base
Recherchez à l’aide du signe –
Si Google trouve un grand nombre de pages dont il doit exclure les pages traitant d'un certain sujet, vous pouvez alors forcer Google à rechercher uniquement les pages qui ne contiennent pas certains mots. Pour ce faire, vous devez indiquer ces mots en plaçant un signe devant chacun - sans espace avant le mot. Par exemple:
pêche - vodka
Rechercher en utilisant ~
Vous souhaiterez peut-être rechercher non seulement le mot spécifié, mais également ses synonymes. Pour ce faire, faites précéder le mot du symbole ~.
Trouver une expression exacte à l'aide de guillemets doubles
Google recherche sur chaque page toutes les occurrences des mots que vous avez écrits dans la chaîne de requête, et il ne se soucie pas de la position relative des mots, tant que tous les mots spécifiés sont sur la page en même temps (c'est-à-dire l'action par défaut). Pour trouver la phrase exacte, vous devez la mettre entre guillemets. Par exemple:
"support livre"
Afin d'avoir au moins un des mots spécifiés, vous devez spécifier explicitement l'opération logique : OU. Par exemple:
sécurité OU protection du livre
De plus, vous pouvez utiliser le signe * dans la barre de recherche pour indiquer n'importe quel mot et. pour représenter n'importe quel personnage.
Trouver des mots à l'aide d'opérateurs supplémentaires
Il existe des opérateurs de recherche qui sont spécifiés dans la chaîne de recherche au format :
opérateur : terme_recherche
Les espaces à côté des deux points ne sont pas nécessaires. Si vous insérez un espace après les deux points, vous verrez un message d'erreur et avant celui-ci, Google les utilisera comme chaîne de recherche normale.
Il existe des groupes d'opérateurs de recherche supplémentaires : langues - indiquez dans quelle langue vous souhaitez voir le résultat, date - limitez les résultats des trois, six ou 12 derniers mois, occurrences - indiquez où dans le document vous devez rechercher la ligne : partout, dans le titre, dans l'URL, les domaines - recherchez sur le site spécifié ou, au contraire, excluez-le de la recherche ; recherche sécurisée - bloque les sites contenant le type d'informations spécifié et les supprime des pages de résultats de recherche.
Cependant, certains opérateurs ne nécessitent pas de paramètre supplémentaire, par exemple la requête " cache : www.google.com" peut être appelé comme une chaîne de recherche à part entière, et certains mots-clés, au contraire, nécessitent un mot de recherche, par exemple " site : www.google.com aide". À la lumière de notre sujet, regardons les opérateurs suivants :
Opérateur |
Description |
Nécessite un paramètre supplémentaire ? |
rechercher uniquement sur le site spécifié dans search_term |
||
rechercher uniquement dans les documents de type search_term |
||
rechercher les pages contenant search_term dans le titre |
||
rechercher des pages contenant tous les mots search_term dans le titre |
||
rechercher les pages contenant le mot search_term dans leur adresse |
||
trouver des pages contenant tous les mots search_term dans leur adresse |
Opérateur site: limite la recherche uniquement au site spécifié et vous pouvez spécifier non seulement le nom de domaine, mais également l'adresse IP. Par exemple, saisissez :
Opérateur type de fichier : Limite la recherche à un type de fichier spécifique. Par exemple:
À la date de publication de l'article, Google peut effectuer une recherche dans 13 formats de fichiers différents :
- Format de document portable Adobe (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (semaine 1, sem. 2, sem. 3, sem. 4, sem. 5, sem., sem., sem.)
- Lotus WordPro (lwp)
- MacWrite (mw)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word (doc)
- Microsoft Works (semaines, wps, wdb)
- Microsoft Write (écriture)
- Format de texte enrichi (rtf)
- Flash d'onde de choc (swf)
- Texte (ans, txt)
Opérateur lien: affiche toutes les pages qui pointent vers la page spécifiée.
Il est probablement toujours intéressant de voir combien d'endroits sur Internet vous connaissent. Essayons :
Opérateur cache : Affiche la version du site dans le cache de Google telle qu'elle était la dernière fois que Google a visité cette page. Prenons n'importe quel site qui change fréquemment et regardons :
Opérateur titre : recherche le mot spécifié dans le titre de la page. Opérateur tout le titre : est une extension - elle recherche tous les quelques mots spécifiés dans le titre de la page. Comparer:
titre : vol vers Mars
intitle:vol intitle:on intitle:mars
allintitle:vol vers mars
Opérateur URL : oblige Google à afficher toutes les pages contenant la chaîne spécifiée dans l'URL. Opérateur allinurl : recherche tous les mots dans une URL. Par exemple:
allinurl:acide acid_stat_alerts.php
Cette commande est particulièrement utile pour ceux qui n'ont pas SNORT - au moins ils peuvent voir comment cela fonctionne sur un système réel.
Méthodes de piratage utilisant Google
Ainsi, nous avons découvert qu'en utilisant une combinaison des opérateurs et des mots-clés ci-dessus, n'importe qui peut collecter les informations nécessaires et rechercher des vulnérabilités. Ces techniques sont souvent appelées Google Hacking.
Plan du site
Vous pouvez utiliser l'opérateur site: pour lister tous les liens que Google a trouvés sur un site. En règle générale, les pages créées dynamiquement par des scripts ne sont pas indexées à l'aide de paramètres. Certains sites utilisent donc des filtres ISAPI afin que les liens ne soient pas sous la forme /article.asp?num=10&dst=5, et avec des barres obliques /article/abc/num/10/dst/5. Ceci est fait pour que le site soit généralement indexé par les moteurs de recherche.
Essayons :
site : www.whitehouse.gov maison blanche
Google pense que chaque page d'un site Web contient le mot Whitehouse. C'est ce que nous utilisons pour obtenir toutes les pages.
Il existe également une version simplifiée :
site :whitehouse.gov
Et le meilleur, c'est que les camarades de whitehouse.gov ne savaient même pas que nous avions examiné la structure de leur site et même regardé les pages en cache que Google avait téléchargées pour lui-même. Cela peut être utilisé pour étudier la structure des sites et visualiser le contenu, restant indétectable pour le moment.
Afficher une liste de fichiers dans les répertoires
Les serveurs WEB peuvent afficher des listes de répertoires de serveurs au lieu de pages HTML classiques. Ceci est généralement effectué pour garantir que les utilisateurs sélectionnent et téléchargent des fichiers spécifiques. Cependant, dans de nombreux cas, les administrateurs n'ont pas l'intention d'afficher le contenu d'un répertoire. Cela se produit en raison d'une configuration incorrecte du serveur ou de l'absence de la page principale dans l'annuaire. En conséquence, le pirate informatique a la possibilité de trouver quelque chose d'intéressant dans le répertoire et de l'utiliser à ses propres fins. Pour retrouver toutes ces pages, il suffit de constater qu'elles contiennent toutes dans leur titre les mots : index de. Mais comme l'index de mots ne contient pas que de telles pages, nous devons affiner la requête et prendre en compte les mots-clés sur la page elle-même, donc des requêtes telles que :
intitle:index.of répertoire parent
intitle:index.of taille du nom
Étant donné que la plupart des inscriptions dans les annuaires sont intentionnelles, vous pourriez avoir du mal à trouver des inscriptions égarées du premier coup. Mais au moins vous pouvez déjà utiliser des listings pour déterminer la version du serveur WEB, comme décrit ci-dessous.
Obtention de la version du serveur WEB.
Connaître la version du serveur WEB est toujours utile avant de lancer une quelconque attaque de hacker. Encore une fois, grâce à Google, vous pouvez obtenir ces informations sans vous connecter à un serveur. Si vous regardez attentivement le listing du répertoire, vous constaterez que le nom du serveur WEB et sa version y sont affichés.
Apache1.3.29 - Serveur ProXad sur trf296.free.fr Port 80
Un administrateur expérimenté peut modifier ces informations, mais en règle générale, c'est vrai. Ainsi, pour obtenir ces informations il suffit d’envoyer une demande :
titre : index.du serveur.at
Pour obtenir des informations sur un serveur spécifique, nous clarifions la demande :
intitle:index.of server.at site:ibm.com
Ou vice versa, nous recherchons des serveurs exécutant une version spécifique du serveur :
intitle:index.of Apache/2.0.40 Serveur à
Cette technique peut être utilisée par un pirate informatique pour retrouver une victime. Si, par exemple, il dispose d'un exploit pour une certaine version du serveur WEB, alors il peut le trouver et essayer l'exploit existant.
Vous pouvez également obtenir la version du serveur en visualisant les pages installées par défaut lors de l'installation de la dernière version du serveur WEB. Par exemple, pour voir la page de test Apache 1.2.6, tapez simplement
intitle:Test.Page.for.Apache ça.a fonctionné !
De plus, certains systèmes d'exploitation installent et lancent immédiatement le serveur WEB lors de l'installation. Cependant, certains utilisateurs n’en sont même pas conscients. Naturellement, si vous constatez que quelqu'un n'a pas supprimé la page par défaut, il est alors logique de supposer que l'ordinateur n'a subi aucune personnalisation et qu'il est probablement vulnérable aux attaques.
Essayez de rechercher des pages IIS 5.0
allintitle:Bienvenue dans les services Internet Windows 2000
Dans le cas d'IIS, vous pouvez déterminer non seulement la version du serveur, mais également la version de Windows et le Service Pack.
Une autre façon de déterminer la version du serveur WEB consiste à rechercher des manuels (pages d'aide) et des exemples qui peuvent être installés par défaut sur le site. Les pirates ont trouvé de nombreuses façons d'utiliser ces composants pour obtenir un accès privilégié à un site. C'est pourquoi vous devez supprimer ces composants sur le site de production. Sans compter que la présence de ces composants peut fournir des informations sur le type de serveur et sa version. Par exemple, trouvons le manuel d'Apache :
inurl : modules de directives manuelles Apache
Utiliser Google comme scanner CGI.
Le scanner CGI ou scanner WEB est un utilitaire permettant de rechercher des scripts et des programmes vulnérables sur le serveur de la victime. Ces utilitaires doivent savoir quoi rechercher, pour cela ils disposent de toute une liste de fichiers vulnérables, par exemple :
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Nous pouvons trouver chacun de ces fichiers en utilisant Google, en utilisant en plus les mots index of ou inurl avec le nom du fichier dans la barre de recherche : nous pouvons trouver des sites avec des scripts vulnérables, par exemple :
allinurl:/random_banner/index.cgi
En utilisant des connaissances supplémentaires, un pirate informatique peut exploiter la vulnérabilité d'un script et utiliser cette vulnérabilité pour forcer le script à émettre n'importe quel fichier stocké sur le serveur. Par exemple, un fichier de mots de passe.
Comment se protéger du piratage de Google.
1. Ne publiez pas de données importantes sur le serveur WEB.
Même si vous avez publié les données temporairement, vous risquez de les oublier ou quelqu'un aura le temps de retrouver et de récupérer ces données avant de les effacer. Ne fais pas ça. Il existe de nombreuses autres façons de transférer des données qui les protègent du vol.
2. Vérifiez votre site.
Utilisez les méthodes décrites pour rechercher votre site. Vérifiez régulièrement votre site pour connaître les nouvelles méthodes qui apparaissent sur le site http://johnny.ihackstuff.com. N'oubliez pas que si vous souhaitez automatiser vos actions, vous devez obtenir une autorisation spéciale de Google. Si vous lisez attentivement http://www.google.com/terms_of_service.html, alors vous verrez la phrase : Vous ne pouvez pas envoyer de requêtes automatisées de quelque sorte que ce soit au système de Google sans l'autorisation expresse préalable de Google.
3. Vous n’aurez peut-être pas besoin de Google pour indexer votre site ou une partie de celui-ci.
Google vous permet de supprimer un lien vers votre site ou une partie de celui-ci de sa base de données, ainsi que de supprimer des pages du cache. De plus, vous pouvez interdire la recherche d'images sur votre site, interdire l'affichage de courts fragments de pages dans les résultats de recherche. Toutes les possibilités de suppression d'un site sont décrites sur la page. http://www.google.com/remove.html. Pour ce faire, vous devez confirmer que vous êtes bien le propriétaire de ce site ou insérer des balises dans la page ou
4. Utilisez le fichier robots.txt
On sait que les moteurs de recherche examinent le fichier robots.txt situé à la racine du site et n'indexent pas les parties marquées du mot Refuser. Vous pouvez l'utiliser pour empêcher l'indexation d'une partie du site. Par exemple, pour empêcher l'indexation de l'intégralité du site, créez un fichier robots.txt contenant deux lignes :
Agent utilisateur : *
Interdire : /
Que se passe-t-il d'autre
Pour que la vie ne vous ressemble pas, je dirai enfin qu'il existe des sites qui surveillent les personnes qui, en utilisant les méthodes décrites ci-dessus, recherchent des failles dans les scripts et les serveurs WEB. Un exemple d'une telle page est
Application.
Un peu sucré. Essayez par vous-même certaines des solutions suivantes :
1. #mysql dump filetype:sql - recherche des dumps de base de données MySQL
2. Rapport récapitulatif des vulnérabilités de l'hôte : vous montrera les vulnérabilités trouvées par d'autres personnes.
3. phpMyAdmin exécuté sur inurl:main.php - cela forcera la fermeture du contrôle via le panneau phpmyadmin
4. pas pour distribution confidentielle
5. Demander des détails sur les variables du serveur Control Tree
6. Exécuter en mode Enfant
7. Ce rapport a été généré par WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs – peut-être que quelqu'un a besoin de fichiers de configuration du pare-feu ? :)
10. intitle:index.of finances.xls – hmm....
11. intitle : Index des discussions dbconvert.exe – journaux de discussion icq
12.intext : Analyse du trafic de Tobias Oetiker
13. intitle : Statistiques d'utilisation générées par Webalizer
14. intitle:statistiques des statistiques Web avancées
15. intitle:index.of ws_ftp.ini – configuration ftp ws
16. inurl:ipsec.secrets contient des secrets partagés - clé secrète - bonne trouvaille
17. inurl:main.php Bienvenue sur phpMyAdmin
18. inurl:server-info Informations sur le serveur Apache
19. site : notes d'administration edu
20. ORA-00921 : fin inattendue de la commande SQL – obtention des chemins
21. titre : index.de trillian.ini
22. intitle : Index de pwd.db
23.intitle:index.of people.lst
24. intitle:index.of master.passwd
25.inurl : liste de passe.txt
26. intitle : Index de .mysql_history
27. intitle:index de intext:globals.inc
28. intitle:index.of administrateurs.pwd
29. intitle:Index.of etc ombre
30.intitle:index.ofsecring.pgp
31. inurl:config.php nom de base de données passe de base de données
32. inurl: effectuer le type de fichier: ini
Centre de formation "Informzashita" http://www.itsecurity.ru - un centre spécialisé leader dans le domaine de la formation à la sécurité de l'information (Licence du Comité de l'éducation de Moscou n° 015470, accréditation d'État n° 004251). Le seul centre de formation autorisé pour les systèmes de sécurité Internet et Clearswift en Russie et dans les pays de la CEI. Centre de formation agréé Microsoft (spécialisation Sécurité). Les programmes de formation sont coordonnés avec la Commission technique d'État de Russie, le FSB (FAPSI). Certificats de formation et documents d'État sur la formation avancée.
SoftKey est un service unique destiné aux acheteurs, développeurs, revendeurs et partenaires affiliés. De plus, il s'agit de l'un des meilleurs magasins de logiciels en ligne en Russie, en Ukraine et au Kazakhstan, qui propose aux clients une large gamme, de nombreux modes de paiement, un traitement rapide (souvent instantané) des commandes, un suivi du processus de commande dans la section personnelle, diverses réductions de le magasin et les fabricants BY.
Un langage de requête est un langage de programmation artificiel utilisé pour effectuer des requêtes dans des bases de données et des systèmes d'information.
En général, ces méthodes de requête peuvent être classées selon qu'elles sont utilisées pour une base de données ou pour la recherche d'informations. La différence est que les demandes adressées à ces services visent à obtenir des réponses factuelles aux questions posées, tandis que le moteur de recherche essaie de trouver des documents contenant des informations liées au domaine d'intérêt de l'utilisateur.
Bases de données
Les langages de requête de base de données incluent les exemples suivants :
- QL - orienté objet, fait référence au successeur de Datalog.
- Le langage de requête contextuel (CQL) est un langage formel de représentation de requêtes pour les systèmes de recherche d'informations (tels que les index Web ou les catalogues bibliographiques).
- CQLF (CODYASYL) - pour les bases de données CODASYL-TYPE.
- Langage de requête orienté concept (COQL) - utilisé dans les modèles associés (com). Il est basé sur les principes de modélisation des données conceptuelles et utilise des opérations telles que la projection et la déprojection de l'analyse multivariée, les opérations analytiques et l'inférence.
- DMX - utilisé pour les modèles
- Datalog est un langage de requête de base de données déductif.
- Gellish English est un langage qui peut être utilisé pour interroger les bases de données Gellish English et permet le dialogue (requêtes et réponses) et sert également à la modélisation des informations sur les connaissances.
- HTSQL - traduit les requêtes http en SQL.
- ISBL - utilisé pour PRTV (l'un des premiers systèmes de gestion de bases de données relationnelles).
- LDAP est un protocole de services de requêtes et d'annuaire qui s'exécute sur TCP/IP.
- MDX - requis pour les bases de données OLAP.

Moteurs de recherche
Le langage de requête de recherche, quant à lui, vise à trouver des données dans les moteurs de recherche. La différence est que les requêtes contiennent souvent du texte brut ou de l'hypertexte avec une syntaxe supplémentaire (telle que « et »/« ou »). Il diffère considérablement des langages standards similaires, qui sont régis par des règles de syntaxe de commande strictes ou contiennent des paramètres de position.
Comment les requêtes de recherche sont-elles classées ?
Il existe trois grandes catégories qui couvrent la plupart des requêtes de recherche : informationnelle, navigationnelle et transactionnelle. Bien que cette classification n’ait pas été établie théoriquement, elle a été confirmée empiriquement par la présence de requêtes réelles dans les moteurs de recherche.
Les requêtes d'informations sont celles qui couvrent des sujets généraux (tels qu'une ville ou un modèle de camion spécifique) et peuvent renvoyer des milliers de résultats pertinents.
Les requêtes de navigation sont des requêtes qui recherchent un seul site ou une seule page Web sur un sujet spécifique (par exemple, YouTube).

Transactionnel - reflète l'intention de l'utilisateur d'effectuer une certaine action, par exemple acheter une voiture ou réserver un billet.
Les moteurs de recherche prennent souvent en charge un quatrième type de requête, beaucoup moins couramment utilisé. Il s'agit de ce que l'on appelle des demandes de connexion, contenant un rapport sur la connectivité du graphique Web indexé (le nombre de liens vers une certaine URL, ou combien de pages sont indexées à partir d'un certain domaine).
Comment les informations sont-elles recherchées ?
Des caractéristiques intéressantes concernant la recherche sur le Web sont devenues connues :
La longueur moyenne des requêtes de recherche était de 2,4 mots.
- Environ la moitié des utilisateurs ont effectué une seule demande et un peu moins d’un tiers des utilisateurs ont effectué au moins trois demandes uniques consécutives.
- Près de la moitié des utilisateurs n’ont consulté que la ou les deux premières pages de résultats.
- Moins de 5 % des utilisateurs utilisent les fonctionnalités de recherche avancées (par exemple, sélection de catégories spécifiques ou recherche dans la recherche).
Fonctionnalités des actions personnalisées
L'étude a également révélé que 19 % des requêtes contenaient un terme géographique (par exemple, noms, codes postaux, caractéristiques géographiques, etc.). Il convient également de noter qu'en plus des requêtes courtes (c'est-à-dire comportant plusieurs termes), il existe souvent des modèles prévisibles dans lesquels les utilisateurs modifient leurs expressions de recherche.

Il a également été constaté que 33 % des requêtes d’un même utilisateur sont répétées et que dans 87 % des cas l’utilisateur cliquera sur le même résultat. Cela suggère que de nombreux utilisateurs utilisent des requêtes répétées pour réviser ou retrouver des informations.
Distributions de fréquence des demandes
De plus, les experts ont confirmé que les distributions de fréquence des requêtes correspondent à une loi de puissance. Autrement dit, une petite partie des mots-clés est observée dans la plus grande liste de requêtes (par exemple, plus de 100 millions) et ils sont les plus fréquemment utilisés. Les phrases restantes au sein des mêmes sujets sont utilisées moins fréquemment et plus individuellement. Ce phénomène, appelé principe de Pareto (ou « règle 80-20 »), a permis aux moteurs de recherche d'utiliser des techniques d'optimisation telles que l'indexation ou le partitionnement de bases de données, la mise en cache et le préchargement, et a également permis d'améliorer la performance du moteur de recherche. langage de requête.
Ces dernières années, il a été constaté que la durée moyenne des requêtes augmentait régulièrement au fil du temps. Ainsi, la requête moyenne en anglais est devenue plus longue. À cette fin, Google a introduit une mise à jour appelée « Hummingbird » (en août 2013), capable de traiter de longues expressions de recherche avec un langage de requête « familier » non protocolaire (comme « où est le café le plus proche ? »).

Pour les demandes plus longues, leur traitement est utilisé - elles sont divisées en phrases formulées dans un langage standard et les réponses aux différentes parties sont affichées séparément.
Requêtes structurées
Les moteurs de recherche prenant en charge les deux syntaxes utilisent des langages de requête plus avancés. Un utilisateur recherchant des documents couvrant plusieurs sujets ou facettes peut décrire chacun d'eux par la caractéristique logique du mot. À la base, un langage de requête logique est un ensemble de certaines expressions et signes de ponctuation.
Qu’est-ce que la recherche avancée ?
Le langage de requête de Yandex et de Google est capable d'effectuer une recherche plus ciblée si certaines conditions sont remplies. La recherche avancée peut effectuer une recherche par partie du titre de la page ou du préfixe du titre, ainsi que par catégories et listes de noms spécifiques. Il peut également limiter les recherches aux pages contenant certains mots dans le titre ou appartenant à certains groupes de sujets. Lorsqu'il est utilisé correctement, le langage de requête peut traiter des paramètres qui sont bien plus complexes que les résultats superficiels de la plupart des moteurs de recherche, y compris des mots spécifiés par l'utilisateur avec des terminaisons variables et des orthographes similaires. Lorsque vous présentez des résultats de recherche avancée, un lien vers les sections pertinentes de la page sera affiché.

Il est également possible de rechercher toutes les pages contenant une phrase spécifique, alors qu'avec une requête standard, les moteurs de recherche ne peuvent s'arrêter sur aucune page de discussion. Dans de nombreux cas, le langage de requête peut mener vers n’importe quelle page située dans les balises noindex.
Dans certains cas, une requête correctement formée permet de rechercher des informations contenant un certain nombre de caractères spéciaux et de lettres d'autres alphabets (caractères chinois par exemple).
Comment les caractères du langage de requête sont-ils lus ?
Les majuscules, les minuscules ainsi que certaines (trémas et accents) ne sont pas prises en compte dans la recherche. Par exemple, une recherche sur le mot clé Citroën ne trouvera pas les pages contenant le mot « Citroën ». Mais certaines ligatures correspondent à des lettres individuelles. Par exemple, une recherche sur « aeroskobing » permettra de trouver facilement des pages contenant « Ereskobing » (AE = Æ).
De nombreux caractères non alphanumériques sont constamment ignorés. Par exemple, il est impossible de trouver des informations pour une requête contenant la chaîne |L| (une lettre entre deux barres verticales), bien que ce caractère soit utilisé dans certains modèles de conversion. Les résultats contiendront uniquement les données de « LT ». Certains caractères et expressions sont traités différemment : une requête pour "crédit (Finance)" affichera les entrées avec les mots "crédit" et "finance", en ignorant les parenthèses, même s'il existe une entrée avec le nom exact "crédit (Finance)". ".

De nombreuses fonctions peuvent être utilisées à l’aide d’un langage de requête.
Syntaxe
Le langage de requête de Yandex et de Google peut utiliser certains signes de ponctuation pour affiner la recherche. Un exemple est les accolades - ((recherche)). La phrase qu'ils contiennent sera recherchée dans son intégralité, sans modification.
La phrase in vous permet de déterminer l'objet de recherche. Par exemple, un mot entre guillemets sera reconnu comme étant utilisé au sens figuré ou comme personnage fictif, sans guillemets - comme information à caractère plus documentaire.
De plus, tous les principaux moteurs de recherche prennent en charge le symbole « - » pour le « non » logique et également et/ou. L'exception concerne les termes qui ne peuvent pas être préfixés par un trait d'union ou un tiret.
Les correspondances d'expressions de recherche inexactes sont marquées d'un ~. Par exemple, si vous ne vous souvenez pas de la formulation exacte d'un terme ou d'un nom, vous pouvez le saisir dans la barre de recherche avec le symbole spécifié et vous pourrez obtenir des résultats aussi similaires que possible.
Options de recherche personnalisées
Il existe également des paramètres de recherche tels que intitle et incategory. Ce sont des filtres affichés séparés par deux points, sous la forme « filtre : chaîne de requête ». La chaîne de requête peut contenir le terme ou l’expression que vous recherchez, ou une partie ou la totalité du titre de la page.
La fonctionnalité "intitle: query" donne la priorité dans les résultats de recherche en fonction du titre, mais affiche également des résultats réguliers en fonction du contenu du titre. Plusieurs de ces filtres peuvent être utilisés simultanément. Comment profiter de cette opportunité ?
Une requête du type « intitle : nom de l'aéroport » renverra tous les articles contenant le nom de l'aéroport dans le titre. Si vous le formulez comme « titre du parking : nom de l’aéroport », alors vous obtiendrez des articles avec le nom de l’aéroport dans le titre et mentionnant le stationnement dans le texte.
La recherche à l'aide du filtre « incategory : Catégorie » fonctionne sur le principe d'afficher dans un premier temps les articles appartenant à un groupe ou une liste de pages spécifique. Par exemple, une requête de recherche telle que « Temples dans la catégorie : Histoire » renverra des résultats sur le thème de l'histoire des temples. Cette fonction peut également être utilisée comme fonction avancée en spécifiant divers paramètres.
Il est important pour toute entreprise de protéger les données confidentielles. La fuite des identifiants et des mots de passe des clients ou la perte de fichiers système situés sur le serveur peuvent non seulement entraîner des pertes financières, mais également détruire la réputation de l'organisation apparemment la plus fiable. Auteur de l'article - Vadim Kulish.
Compte tenu de tous les risques possibles, les entreprises introduisent les dernières technologies et dépensent d’énormes sommes d’argent pour tenter d’empêcher tout accès non autorisé à des données précieuses.
Cependant, avez-vous déjà pensé qu'en plus des attaques de pirates informatiques complexes et bien pensées, il existe des moyens simples de détecter des fichiers qui n’étaient pas protégés de manière fiable. Il s'agit d'opérateurs de recherche : des mots ajoutés aux requêtes de recherche pour produire des résultats plus précis. Mais tout d’abord.
Surfer sur Internet est impossible à imaginer sans les moteurs de recherche tels que Google, Yandex, Bing et d'autres services de ce type. Le moteur de recherche indexe de nombreux sites sur Internet. Pour ce faire, ils utilisent des robots de recherche qui traitent de grandes quantités de données et les rendent consultables.
Opérateurs de recherche Google populaires
L'utilisation des opérateurs suivants vous permet de rendre plus précis le processus de recherche des informations nécessaires :
* site : limite la recherche à une ressource spécifique
Exemple : demande site :exemple.com trouvera toutes les informations que Google contient par exemple.com.
* filetype : permet de rechercher des informations dans un type de fichier spécifique
Exemple : demande affichera la liste complète des fichiers du site présents dans le moteur de recherche Google.
* inurl : - recherche dans l'URL de la ressource
Exemple : demande site:exemple.com inurl:admin— recherche le panneau d'administration sur le site.
* intitle : - recherche dans le titre de la page
Exemple : demande site : exemple.com titre : "Index de"— recherche des pages sur example.com contenant une liste de fichiers
* cache : - recherche dans le cache Google
Exemple : demande cache:exemple.com renverra toutes les pages de la ressource example.com mises en cache dans le système
Malheureusement, les robots de recherche ne sont pas en mesure de déterminer le type et le degré de confidentialité des informations. Ils traitent donc de la même manière un article de blog, destiné à un large éventail de lecteurs, et une sauvegarde de base de données, qui est stockée dans le répertoire racine du serveur Web et ne peut être utilisée par des personnes non autorisées.
Grâce à cette fonctionnalité, ainsi qu'à l'utilisation d'opérateurs de recherche, les attaquants sont capables de détecter les vulnérabilités des ressources Web, diverses fuites d'informations (sauvegardes et messages d'erreur des applications Web), des ressources cachées, telles que des panneaux d'administration ouverts, sans mécanismes d'authentification et d'autorisation.
Quelles données sensibles peut-on trouver en ligne ?
Veuillez noter que les informations susceptibles d'être découvertes par les moteurs de recherche et susceptibles d'intéresser les pirates informatiques comprennent :
* Domaines de troisième niveau de la ressource recherchée
Les domaines de troisième niveau peuvent être découverts en utilisant le mot « site : ». Par exemple, une demande comme site :*.exemple.com listera tous les domaines de 3ème niveau pour example.com. De telles requêtes vous permettent de découvrir des ressources d'administration cachées, des systèmes de contrôle de version et d'assemblage, ainsi que d'autres applications dotées d'une interface Web.
* Fichiers cachés sur le serveur
Diverses parties d'une application Web peuvent apparaître dans les résultats de recherche. Pour les trouver, vous pouvez utiliser la requête type de fichier :php site :exemple.com. Cela vous permet de découvrir des fonctionnalités auparavant indisponibles dans l'application, ainsi que diverses informations sur le fonctionnement de l'application.
*Sauvegardes
Pour rechercher des sauvegardes, utilisez le mot-clé filetype:. Diverses extensions de fichiers sont utilisées pour stocker les sauvegardes, mais les extensions les plus couramment utilisées sont bak, tar.gz et sql. Exemple de demande : site :*.example.com type de fichier :sql. Les sauvegardes contiennent souvent des identifiants et des mots de passe pour les interfaces d'administration, ainsi que des données utilisateur et le code source du site Web.
* Erreurs d'application Web
Le texte d'erreur peut inclure diverses informations sur les composants système de l'application (serveur Web, base de données, plateforme d'application Web). Ces informations sont toujours très intéressantes pour les pirates, car elles leur permettent d'obtenir plus d'informations sur le système attaqué et d'améliorer leur attaque sur la ressource. Exemple de demande : site:exemple.com "avertissement" "erreur".
* Identifiants et mots de passe
Suite au piratage d'une application Web, les données des utilisateurs de ce service peuvent apparaître sur Internet. Demande type de fichier :txt "login" "mot de passe" vous permet de trouver des fichiers avec des identifiants et des mots de passe. De la même manière, vous pouvez vérifier si votre messagerie ou tout autre compte a été piraté. Il suffit de faire une demande type de fichier :txtnom_utilisateur_ou_email_mail".
Les combinaisons de mots-clés et de chaînes de recherche utilisées pour découvrir des informations sensibles sont appelées Google Dorks.
Les experts de Google les ont collectés dans leur base de données publique Google Hacking Database. Cela permet à un représentant de l'entreprise, qu'il s'agisse du PDG, du développeur ou du webmaster, d'effectuer une requête dans un moteur de recherche et de déterminer dans quelle mesure les données précieuses sont protégées. Tous les abrutis sont divisés en catégories pour faciliter la recherche.
Besoin d'aide ? Commandez une consultation avec des spécialistes des tests de sécurité a1qa.
Comment Google Dorks est entré dans l'histoire du piratage
Enfin, voici quelques exemples de la façon dont Google Dorks a aidé les attaquants à obtenir des informations importantes mais peu protégées :
Étude de cas n°1. Fuite de documents confidentiels sur le site Internet de la banque
Dans le cadre de l'analyse de sécurité du site officiel de la banque, un grand nombre de documents PDF ont été découverts. Tous les documents ont été trouvés à l'aide de la requête « site:bank-site filetype:pdf ». Le contenu des documents s'est avéré intéressant, car ils contenaient des plans des locaux dans lesquels se trouvaient les succursales bancaires dans tout le pays. Cette information serait d’un grand intérêt pour les braqueurs de banque.
Étude de cas n°2. Rechercher des données de carte de paiement
Très souvent, lorsque les boutiques en ligne sont piratées, les attaquants accèdent aux données des cartes de paiement des utilisateurs. Pour organiser l'accès partagé à ces données, les attaquants utilisent des services publics indexés par Google. Exemple de demande : « Numéro de carte » « Date d'expiration » « Type de carte » type de fichier : txt.
Cependant, il ne faut pas se limiter à des contrôles de base. Faites confiance à a1qa pour une évaluation complète de votre produit. Après tout, il est moins coûteux de prévenir le vol de données que d’en éliminer les conséquences.
L'obtention de données privées ne signifie pas toujours un piratage : elles sont parfois publiées publiquement. La connaissance des paramètres de Google et un peu d'ingéniosité vous permettront de trouver beaucoup de choses intéressantes - des numéros de carte de crédit aux documents du FBI.
AVERTISSEMENT
Toutes les informations sont fournies à titre informatif uniquement. Ni les éditeurs ni l'auteur ne sont responsables de tout dommage éventuel causé par les éléments de cet article.Aujourd’hui, tout est connecté à Internet, sans se soucier d’en restreindre l’accès. Ainsi, de nombreuses données privées deviennent la proie des moteurs de recherche. Les robots araignées ne se limitent plus aux pages Web, mais indexent tout le contenu disponible sur Internet et ajoutent constamment des informations non publiques à leurs bases de données. Découvrir ces secrets est facile : il vous suffit de savoir comment poser des questions à leur sujet.
Recherche de fichiers
Entre des mains compétentes, Google trouvera rapidement tout ce qui ne se trouve pas sur Internet, par exemple les informations personnelles et les fichiers à usage officiel. Elles sont souvent cachées comme une clé sous un tapis : il n'y a pas de réelles restrictions d'accès, les données se trouvent simplement au dos du site, là où aucun lien ne mène. L'interface Web standard de Google ne fournit que des paramètres de recherche avancés de base, mais même ceux-ci seront suffisants.
Vous pouvez limiter votre recherche Google à un type spécifique de fichier à l'aide de deux opérateurs : filetype et ext . Le premier précise le format que le moteur de recherche a déterminé à partir du titre du fichier, le second précise l'extension du fichier, quel que soit son contenu interne. Lors de la recherche dans les deux cas, il vous suffit de spécifier l'extension. Initialement, l'opérateur ext était pratique à utiliser dans les cas où le fichier n'avait pas de caractéristiques de format spécifiques (par exemple, pour rechercher des fichiers de configuration ini et cfg, qui pouvaient contenir n'importe quoi). Désormais, les algorithmes de Google ont changé et il n'y a plus de différence visible entre les opérateurs - les résultats sont dans la plupart des cas les mêmes.

Filtrage des résultats
Par défaut, Google recherche les mots et, en général, les caractères saisis dans tous les fichiers des pages indexées. Vous pouvez limiter la zone de recherche par domaine de premier niveau, par site spécifique ou par l'emplacement de la séquence de recherche dans les fichiers eux-mêmes. Pour les deux premières options, utilisez l'opérateur du site, suivi du nom du domaine ou du site sélectionné. Dans le troisième cas, tout un ensemble d'opérateurs permet de rechercher des informations dans les champs de service et les métadonnées. Par exemple, allinurl trouvera celui indiqué dans le corps des liens eux-mêmes, allinanchor - dans le texte équipé de la balise , allintitle - dans les titres des pages, allintext - dans le corps des pages.
Pour chaque opérateur, il existe une version allégée avec un nom plus court (sans le préfixe all). La différence est que allinurl trouvera des liens avec tous les mots, et inurl ne trouvera que des liens avec le premier d'entre eux. Le deuxième mot et les mots suivants de la requête peuvent apparaître n’importe où sur les pages Web. L'opérateur inurl diffère également d'un autre opérateur ayant une signification similaire - site. Le premier permet également de trouver n'importe quelle séquence de caractères dans un lien vers le document recherché (par exemple, /cgi-bin/), largement utilisé pour trouver des composants présentant des vulnérabilités connues.
Essayons-le en pratique. Nous prenons le filtre allintext et faisons en sorte que la demande produise une liste de numéros et de codes de vérification de cartes de crédit qui n'expireront que dans deux ans (ou lorsque leurs propriétaires en auront assez de nourrir tout le monde).
Allintext : date d'expiration du numéro de carte / cvv 2017 
Lorsque vous lisez dans l'actualité qu'un jeune hacker a « piraté les serveurs » du Pentagone ou de la NASA, volant des informations classifiées, nous parlons dans la plupart des cas d'une technique aussi basique d'utilisation de Google. Supposons que nous soyons intéressés par une liste d’employés de la NASA et leurs coordonnées. Une telle liste est sûrement disponible sous forme électronique. Pour des raisons de commodité ou par souci de surveillance, il peut également figurer sur le site Web de l’organisation lui-même. Il est logique que dans ce cas il n'y ait pas de liens vers celui-ci, puisqu'il est destiné à un usage interne. Quels mots peuvent contenir un tel fichier ? Au minimum - le champ « adresse ». Tester toutes ces hypothèses est facile.

Inurl : nasa.gov, type de fichier : xlsx « adresse »

Nous utilisons la bureaucratie
Des trouvailles comme celle-ci sont une belle touche. Une prise vraiment solide est fournie par une connaissance plus détaillée des opérateurs de Google pour les webmasters, du réseau lui-même et des particularités de la structure de ce qui est recherché. Connaissant les détails, vous pouvez facilement filtrer les résultats et affiner les propriétés des fichiers nécessaires afin d'obtenir des données vraiment précieuses dans le reste. C'est drôle que la bureaucratie vienne ici à la rescousse. Il produit des formulations standards pratiques pour rechercher des informations secrètes divulguées accidentellement sur Internet.
Par exemple, le cachet de déclaration de distribution, exigé par le département américain de la Défense, signifie des restrictions standardisées sur la distribution d'un document. La lettre A désigne les diffusions publiques dans lesquelles il n'y a rien de secret ; B - destiné uniquement à un usage interne, C - strictement confidentiel, et ainsi de suite jusqu'à F. La lettre X ressort séparément, ce qui marque une information particulièrement précieuse représentant un secret d'État du plus haut niveau. Laissez ceux qui sont censés le faire en service rechercher de tels documents, et nous nous limiterons aux fichiers portant la lettre C. Selon la directive DoDI 5230.24, ce marquage est attribué aux documents contenant une description des technologies critiques qui relèvent du contrôle des exportations. . Ces informations soigneusement protégées peuvent être trouvées sur les sites du domaine de premier niveau .mil, attribué à l'armée américaine.
« DÉCLARATION DE DISTRIBUTION C » inurl:navy.mil 
Il est très pratique que le domaine .mil ne contienne que des sites du ministère américain de la Défense et de ses organisations sous contrat. Les résultats de recherche avec une restriction de domaine sont exceptionnellement clairs et les titres parlent d'eux-mêmes. Rechercher des secrets russes de cette manière est pratiquement inutile : le chaos règne dans les domaines.ru et.rf, et les noms de nombreux systèmes d'armes sonnent comme botaniques (PP « Kiparis », canons automoteurs « Akatsia ») ou même fabuleux ( TOS "Buratino").

En étudiant attentivement n'importe quel document d'un site du domaine .mil, vous pouvez voir d'autres marqueurs pour affiner votre recherche. Par exemple, une référence aux restrictions à l'exportation « Sec 2751 », qui est également pratique pour rechercher des informations techniques intéressantes. De temps en temps, il est supprimé des sites officiels où il apparaissait autrefois, donc si vous ne parvenez pas à suivre un lien intéressant dans les résultats de recherche, utilisez le cache de Google (opérateur de cache) ou le site Internet Archive.
Grimper dans les nuages
En plus des documents gouvernementaux accidentellement déclassifiés, des liens vers des fichiers personnels de Dropbox et d'autres services de stockage de données créant des liens « privés » vers des données publiées publiquement apparaissent parfois dans le cache de Google. C’est encore pire avec les services alternatifs et faits maison. Par exemple, la requête suivante recherche les données de tous les clients Verizon sur lesquels un serveur FTP est installé et utilisent activement leur routeur.
Allinurl:ftp://verizon.net
Il existe aujourd'hui plus de quarante mille personnes intelligentes, et au printemps 2015, elles étaient bien plus nombreuses. Au lieu de Verizon.net, vous pouvez remplacer le nom de n'importe quel fournisseur bien connu, et plus il est célèbre, plus le piège peut être important. Grâce au serveur FTP intégré, vous pouvez voir les fichiers sur un périphérique de stockage externe connecté au routeur. Il s'agit généralement d'un NAS pour le travail à distance, d'un cloud personnel ou d'une sorte de téléchargement de fichiers peer-to-peer. Tous les contenus de ces médias sont indexés par Google et d'autres moteurs de recherche, vous pouvez donc accéder aux fichiers stockés sur des disques externes via un lien direct.

En regardant les configurations
Avant la migration généralisée vers le cloud, de simples serveurs FTP constituaient un stockage à distance, qui présentait également de nombreuses vulnérabilités. Beaucoup d’entre eux sont toujours d’actualité aujourd’hui. Par exemple, le programme populaire WS_FTP Professional stocke les données de configuration, les comptes d'utilisateurs et les mots de passe dans le fichier ws_ftp.ini. Il est facile à trouver et à lire, car tous les enregistrements sont enregistrés au format texte et les mots de passe sont cryptés avec l'algorithme Triple DES après un brouillage minimal. Dans la plupart des versions, il suffit de supprimer le premier octet.

Il est facile de déchiffrer ces mots de passe à l'aide de l'utilitaire WS_FTP Password Decryptor ou d'un service Web gratuit.

Lorsqu'on parle de piratage d'un site Web arbitraire, cela signifie généralement obtenir un mot de passe à partir des journaux et des sauvegardes des fichiers de configuration des CMS ou des applications de commerce électronique. Si vous connaissez leur structure typique, vous pouvez facilement indiquer les mots-clés. Les lignes comme celles trouvées dans ws_ftp.ini sont extrêmement courantes. Par exemple, dans Drupal et PrestaShop, il y a toujours un identifiant utilisateur (UID) et un mot de passe correspondant (pwd), et toutes les informations sont stockées dans des fichiers avec l'extension .inc. Vous pouvez les rechercher comme suit :
"pwd=" "UID=" ext:inc
Révéler les mots de passe du SGBD
Dans les fichiers de configuration des serveurs SQL, les noms d'utilisateur et les adresses e-mail sont stockés en texte clair et leurs hachages MD5 sont écrits à la place des mots de passe. À proprement parler, il est impossible de les déchiffrer, mais vous pouvez trouver une correspondance parmi les paires hachage-mot de passe connues.

Il existe encore des SGBD qui n'utilisent même pas le hachage de mot de passe. Les fichiers de configuration de chacun d'entre eux peuvent simplement être visualisés dans le navigateur.
Intext : DB_PASSWORD, type de fichier : env

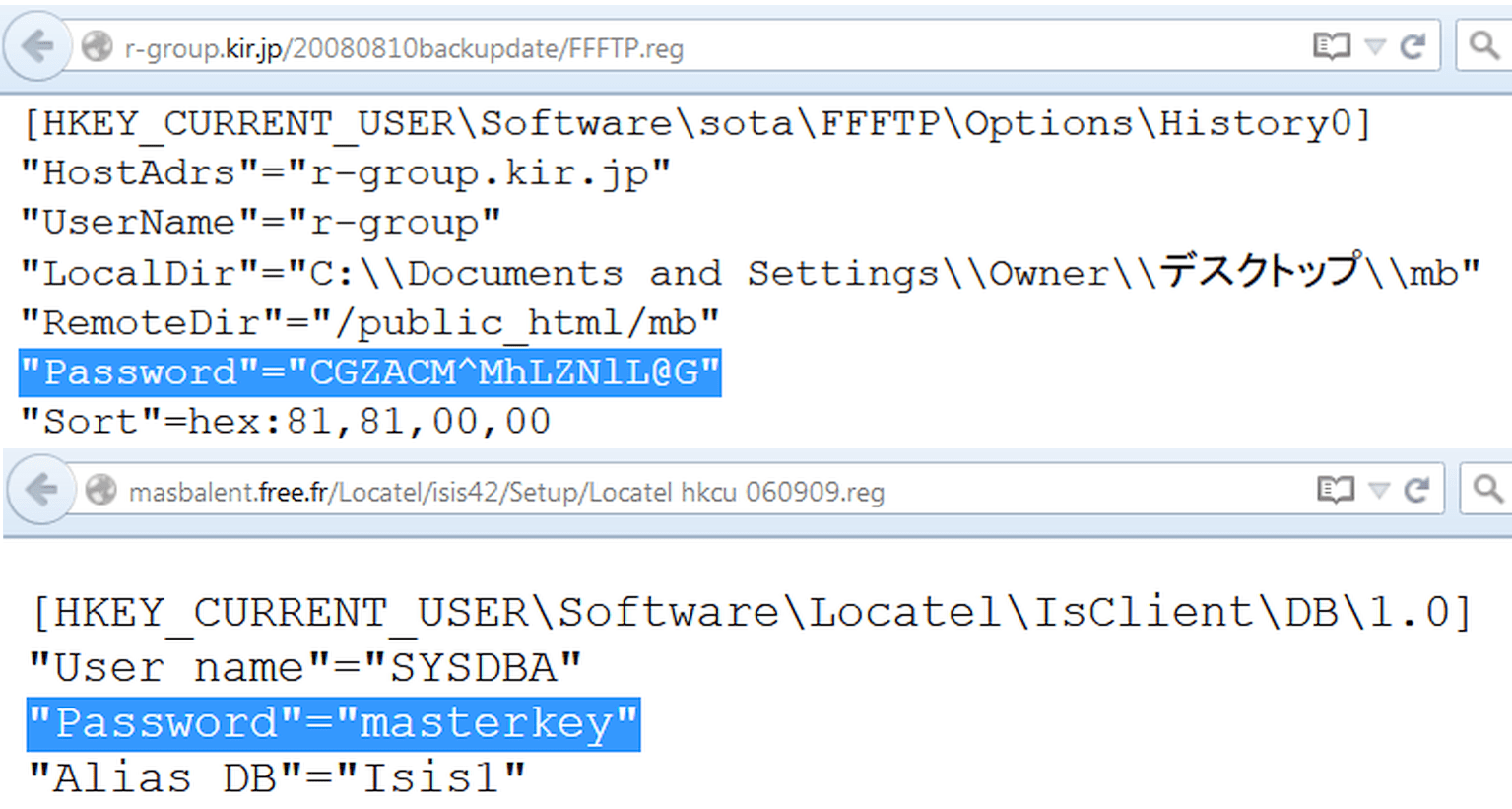
Avec l'avènement des serveurs Windows, la place des fichiers de configuration a été partiellement prise par le registre. Vous pouvez effectuer une recherche dans ses branches exactement de la même manière, en utilisant reg comme type de fichier. Par exemple, comme ceci :
Type de fichier :reg HKEY_CURRENT_USER "Mot de passe"=
N'oublions pas l'évidence
Parfois, il est possible d'accéder à des informations classifiées à l'aide de données ouvertes accidentellement et portées à l'attention de Google. L'option idéale consiste à trouver une liste de mots de passe dans un format commun. Seules les personnes désespérées peuvent stocker les informations de compte dans un fichier texte, un document Word ou une feuille de calcul Excel, mais il y en a toujours suffisamment.
Type de fichier : xls inurl : mot de passe

D’une part, il existe de nombreux moyens pour prévenir de tels incidents. Il est nécessaire de spécifier les droits d'accès adéquats dans htaccess, de patcher le CMS, de ne pas utiliser de scripts gauchers et de boucher les autres trous. Il existe également un fichier avec une liste d'exceptions robots.txt qui interdit aux moteurs de recherche d'indexer les fichiers et répertoires qui y sont spécifiés. D'un autre côté, si la structure du fichier robots.txt sur certains serveurs diffère de celle standard, il devient immédiatement clair ce qu'ils essaient de cacher dessus.

La liste des répertoires et fichiers de n'importe quel site est précédée de l'index standard de. Puisqu'à des fins de service, il doit apparaître dans le titre, il est logique de limiter sa recherche à l'opérateur intitle. Des choses intéressantes se trouvent dans les répertoires /admin/, /personal/, /etc/ et même /secret/.

Restez à l'écoute des mises à jour
La pertinence est ici extrêmement importante : les anciennes vulnérabilités sont corrigées très lentement, mais Google et ses résultats de recherche changent constamment. Il y a même une différence entre un filtre « dernière seconde » (&tbs=qdr:s à la fin de l'URL de requête) et un filtre « temps réel » (&tbs=qdr:1).
L'intervalle de temps de la dernière date de mise à jour du fichier est également indiqué implicitement par Google. Grâce à l'interface Web graphique, vous pouvez sélectionner l'une des périodes standards (heure, jour, semaine, etc.) ou définir une plage de dates, mais cette méthode n'est pas adaptée à l'automatisation.
D'après l'apparence de la barre d'adresse, vous ne pouvez que deviner un moyen de limiter la sortie des résultats en utilisant la construction &tbs=qdr:. La lettre y après fixe la limite d'un an (&tbs=qdr:y), m montre les résultats du mois dernier, w - pour la semaine, d - pour le jour passé, h - pour la dernière heure, n - pour la minute, et s - pour la seconde. Les résultats les plus récents que Google vient de faire connaître se trouvent grâce au filtre &tbs=qdr:1 .
Si vous avez besoin d'écrire un script astucieux, il sera utile de savoir que la plage de dates est définie dans Google au format Julian à l'aide de l'opérateur daterange. Par exemple, voici comment retrouver une liste de documents PDF avec le mot confidentiel, téléchargés du 1er janvier au 1er juillet 2015.
Type de fichier confidentiel : pdf plage de dates : 2457024-2457205
La plage est indiquée au format de date julienne sans tenir compte de la partie fractionnaire. Les traduire manuellement à partir du calendrier grégorien n'est pas pratique. Il est plus facile d'utiliser un convertisseur de date.
Ciblage et filtrage à nouveau
En plus de spécifier des opérateurs supplémentaires dans la requête de recherche, ils peuvent être envoyés directement dans le corps du lien. Par exemple, la spécification filetype:pdf correspond à la construction as_filetype=pdf . Cela permet de demander des éclaircissements. Disons que la sortie des résultats uniquement pour la République du Honduras est spécifiée en ajoutant la construction cr=countryHN à l'URL de recherche, et uniquement pour la ville de Bobruisk - gcs=Bobruisk. Vous pouvez trouver une liste complète dans la section développeur.
Les outils d'automatisation de Google sont conçus pour vous faciliter la vie, mais ils ajoutent souvent des problèmes. Par exemple, l’adresse IP d’un utilisateur est utilisée pour déterminer sa ville via WHOIS. Sur la base de ces informations, Google non seulement équilibre la charge entre les serveurs, mais modifie également les résultats de recherche. Selon les régions, pour une même demande, des résultats différents apparaîtront sur la première page, et certains d'entre eux pourront être complètement masqués. Le code à deux lettres après la directive gl=country vous aidera à vous sentir cosmopolite et à rechercher des informations sur n'importe quel pays. Par exemple, le code des Pays-Bas est NL, mais le Vatican et la Corée du Nord n'ont pas leur propre code dans Google.
Souvent, les résultats de recherche finissent par être encombrés même après avoir utilisé plusieurs filtres avancés. Dans ce cas, il est facile de clarifier la demande en y ajoutant plusieurs mots d'exception (un signe moins est placé devant chacun d'eux). Par exemple, les termes banque, noms et tutoriel sont souvent utilisés avec le mot Personnel. Par conséquent, des résultats de recherche plus propres seront affichés non pas par un exemple classique de requête, mais par un exemple raffiné :
Intitre : "Index de /Personnel/" -noms -tutoriel -banque
Un dernier exemple
Un hacker sophistiqué se distingue par le fait qu'il se procure tout seul tout ce dont il a besoin. Par exemple, le VPN est une solution pratique, mais soit coûteuse, soit temporaire et soumise à des restrictions. Souscrire un abonnement pour vous-même coûte trop cher. C'est bien qu'il existe des abonnements de groupe, et avec l'aide de Google, il est facile de faire partie d'un groupe. Pour ce faire, il suffit de rechercher le fichier de configuration Cisco VPN, qui possède une extension PCF assez non standard et un chemin reconnaissable : Program Files\Cisco Systems\VPN Client\Profiles. Une seule demande et vous rejoignez, par exemple, l'équipe conviviale de l'Université de Bonn.
Type de fichier : pcf vpn OR Group

INFOS
Google trouve des fichiers de configuration de mot de passe, mais beaucoup d'entre eux sont cryptés ou remplacés par des hachages. Si vous voyez des chaînes de longueur fixe, recherchez immédiatement un service de décryptage.Les mots de passe sont stockés cryptés, mais Maurice Massard a déjà écrit un programme pour les décrypter et le propose gratuitement via thecampusgeeks.com.
Google exécute des centaines de types différents d'attaques et de tests d'intrusion. Il existe de nombreuses options, affectant les programmes populaires, les principaux formats de bases de données, de nombreuses vulnérabilités de PHP, les nuages, etc. En sachant exactement ce que vous recherchez, il sera beaucoup plus facile de trouver les informations dont vous avez besoin (en particulier les informations que vous n'aviez pas l'intention de rendre publiques). Shodan n'est pas le seul à se nourrir d'idées intéressantes, mais chaque base de données de ressources réseau indexées !