Méthode de base artificielle avec solution détaillée. Résoudre des problèmes de programmation linéaire en utilisant la méthode des bases artificielles. Résoudre le ZLP par la méthode simplexe avec une base artificielle
Lorsqu'elle est suffisamment grande, la formule de Bernoulli produit des calculs fastidieux. Par conséquent, dans de tels cas, le théorème de Laplace local est utilisé.
Théorème(théorème de Laplace local). Si la probabilité p d’occurrence de l’événement A dans chaque essai est constante et différente de 0 et 1, alors la probabilité  le fait que l'événement A apparaîtra exactement k fois dans n essais indépendants est approximativement égal à la valeur de la fonction :
le fait que l'événement A apparaîtra exactement k fois dans n essais indépendants est approximativement égal à la valeur de la fonction :
 ,
,
 .
.
Il existe des tableaux dans lesquels se trouvent les valeurs des fonctions  , pour les valeurs positives x.
, pour les valeurs positives x.
Notez que la fonction  même
même
Ainsi, la probabilité que l’événement A apparaisse dans n essais est exactement k fois approximativement égale à
 , Où
, Où  .
.
Exemple. 1500 graines ont été semées sur le terrain expérimental. Trouvez la probabilité que les plants produisent 1 200 graines si la probabilité que le grain germe est de 0,9.
Solution. 
Théorème intégral de Laplace
La probabilité que dans neuf essais indépendants l’événement A apparaisse au moins k1 fois et au plus k2 fois est calculée à l’aide du théorème intégral de Laplace.
Théorème(Théorème intégral de Laplace). Si la probabilité p d'apparition de l'événement a dans chaque essai est constante et différente de 0 et 1, alors la probabilité que l'événement A dans n essais apparaisse au moins k 1 fois et pas plus de k 2 fois est approximativement égale à la valeur d'une certaine intégrale:
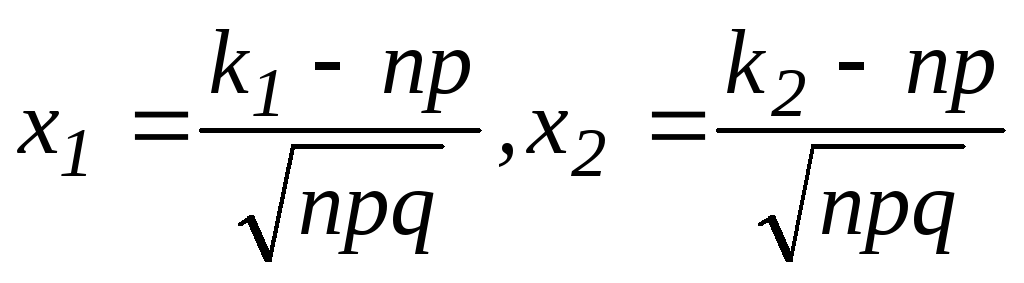 .
.
Fonction  appelée fonction intégrale de Laplace, elle est impaire et sa valeur se retrouve dans le tableau des valeurs positives x.
appelée fonction intégrale de Laplace, elle est impaire et sa valeur se retrouve dans le tableau des valeurs positives x.
Exemple. En laboratoire, à partir d'un lot de graines avec un taux de germination de 90%, 600 graines ont été semées, qui ont germé, pas moins de 520 et pas plus de 570.
Solution.

La formule de Poisson
Supposons que n essais indépendants soient effectués, la probabilité d'occurrence de l'événement A dans chaque essai est constante et égale à p. Comme nous l’avons déjà dit, la probabilité d’occurrence de l’événement A dans des essais indépendants peut être trouvée exactement k fois en utilisant la formule de Bernoulli. Lorsque n est suffisamment grand, le théorème local de Laplace est utilisé. Cependant, cette formule ne convient pas lorsque la probabilité qu'un événement se produise dans chaque essai est faible ou proche de 1. Et lorsque p=0 ou p=1, elle n'est pas du tout applicable. Dans de tels cas, utilisez le théorème de Poisson.
Théorème(Théorème de Poisson). Si la probabilité p d'apparition de l'événement A dans chaque essai est constante et proche de 0 ou 1, et que le nombre d'essais est suffisamment grand, alors la probabilité que dans n essais indépendants l'événement A apparaisse exactement k fois est trouvée par la formule formule:
 .
.
Exemple. Le manuscrit compte mille pages de texte dactylographié et contient mille fautes de frappe. Trouvez la probabilité qu'une page prise au hasard contienne au moins une faute de frappe.
Solution.



Questions Pour autotests
Formuler la définition classique de la probabilité d’un événement.
Théorèmes d'état pour l'addition et la multiplication des probabilités.
Définir groupe completévénements.
Écrivez la formule de la probabilité totale.
Écrivez la formule de Bayes.
Écrivez la formule de Bernoulli.
Écrivez la formule de Poisson.
Notez la formule de Laplace locale.
Écrivez la formule intégrale de Laplace.
Thème 13. Variable aléatoire et ses caractéristiques numériques
Littérature: ,,,,,.
L'un des principaux concepts de la théorie des probabilités est le concept de variable aléatoire. C'est le nom usuel d'une grandeur variable qui prend ses valeurs selon les cas. Il existe deux types de variables aléatoires : discrètes et continues. Les variables aléatoires sont généralement notées X, Y, Z.
Une variable aléatoire X est dite continue (discrète) si elle ne peut prendre qu'un nombre fini ou dénombrable de valeurs. Une variable aléatoire discrète X est définie si toutes ses valeurs possibles x 1 , x 2 , x 3 , ... x n (dont le nombre peut être fini ou infini) et les probabilités correspondantes p 1 , p 2 , p 3 , ... p sont donnés n.
La loi de distribution d'une variable aléatoire discrète X est généralement donnée par le tableau :
La première ligne contient des valeurs possibles variable aléatoire X, et la deuxième ligne montre les probabilités de ces valeurs. La somme des probabilités avec lesquelles la variable aléatoire X prend toutes ses valeurs est égale à un, c'est-à-dire
р 1 +р 2 + р 3 +…+р n =1.
La loi de distribution d'une variable aléatoire discrète X peut être représentée graphiquement. Pour ce faire, les points M 1 (x 1, p 1), M 2 (x 2, p 2), M 3 (x 3, p 3), ... M n (x n, p n) sont construits dans un rectangle système de coordonnées et relié par des segments droits La figure résultante est appelée le polygone de distribution de la variable aléatoire X.
Exemple. La valeur discrète X est donnée par la loi de distribution suivante :
Il est nécessaire de calculer : a) l'espérance mathématique M(X), b) la variance D(X), c) l'écart type σ.
Solution . a) L'espérance mathématique M(X) d'une variable aléatoire discrète X est la somme des produits par paires de toutes les valeurs possibles de la variable aléatoire par les probabilités correspondantes de ces valeurs possibles. Si une variable aléatoire discrète X est spécifiée à l'aide du tableau (1), alors l'espérance mathématique M(X) est calculée à l'aide de la formule
M(X)=x 1 ∙p 1 +x 2 ∙p 2 +x 3 ∙p 3 +…+x n ∙p n. (2)
L'espérance mathématique M(X) est aussi appelée valeur moyenne de la variable aléatoire X. En appliquant (2), on obtient :
M(X)=48∙0,2+53∙0,4+57∙0,3 +61∙0,1=54.
b) Si M(X) est l'espérance mathématique d'une variable aléatoire X, alors la différence X-M(X) est appelée déviation variable aléatoire X à partir de la valeur moyenne. Cette différence caractérise la diffusion d'une variable aléatoire.
Variance(diffusion) d'une variable aléatoire discrète X est l'espérance mathématique (valeur moyenne) de l'écart carré de la variable aléatoire par rapport à son espérance mathématique. Ainsi, par définition nous avons :
D(X)=M2. (3)
Calculons toutes les valeurs possibles de l'écart carré.
2 =(48-54) 2 =36
2 =(53-54) 2 =1
2 =(57-54) 2 =9
2 =(61-54) 2 =49
Pour calculer la dispersion D(X), on établit la loi de répartition de l'écart carré puis on applique la formule (2).
ré(X)= 36∙0,2+1∙0,4+9∙0,3 +49∙0,1=15,2.
A noter que la propriété suivante est souvent utilisée pour calculer la variance : la variance D(X) est égale à la différence entre l'espérance mathématique du carré de la variable aléatoire X et le carré de son espérance mathématique, soit
D(X)-M(X2)-2. (4)
Pour calculer la dispersion à l'aide de la formule (4), on établit la loi de distribution de la variable aléatoire X 2 :
Trouvons maintenant l'espérance mathématique M(X 2).
M(X 2)= (48) 2 ∙0,2+(53) 2 ∙0,4+(57) 2 ∙0,3 +(61) 2 ∙0,1=
460,8+1123,6+974,7+372,1=2931,2.
En appliquant (4), on obtient :
D(X)=2931,2-(54)2 =2931,2-2916=15,2.
Comme vous pouvez le constater, nous avons obtenu le même résultat.
c) La dimension de la variance est égale au carré de la dimension de la variable aléatoire. Ainsi, pour caractériser la dispersion des valeurs possibles d'une variable aléatoire autour de sa valeur moyenne, il est plus pratique de considérer une valeur égale à la valeur arithmétique de la racine carrée de la variance, c'est-à-dire  . Cette valeur est appelée écart type de la variable aléatoire X et est notée σ. Ainsi
. Cette valeur est appelée écart type de la variable aléatoire X et est notée σ. Ainsi
σ=  . (5)
. (5)
En appliquant (5), on a : σ=  .
.
Exemple. La variable aléatoire X est distribuée selon la loi normale. Espérance mathématique M(X)=5 ; varianceD(X)=0,64. Trouvez la probabilité qu'à la suite du test X prenne une valeur dans l'intervalle (4;7).
Solution On sait que si une variable aléatoire X est spécifiée par une fonction différentielle f(x), alors la probabilité que X prenne une valeur appartenant à l'intervalle (α, β) est calculée par la formule
 . (1)
. (1)
Si la valeur X est distribuée selon la loi normale, alors la fonction différentielle
 ,
,
Où UN=M(X) et σ=  . Dans ce cas, on obtient de (1)
. Dans ce cas, on obtient de (1)
 . (2)
. (2)
La formule (2) peut être transformée à l'aide de la fonction de Laplace.
Faisons une substitution. Laisser  . Alors
. Alors  ou dx=σ∙
dt.
ou dx=σ∙
dt.
Ainsi  , où t 1 et t 2 sont les limites correspondantes pour la variable t.
, où t 1 et t 2 sont les limites correspondantes pour la variable t.
En réduisant de σ, on a

De la substitution saisie  il s'ensuit que
il s'ensuit que  Et
Et  .
.
Ainsi,
 (3)
(3)
D'après les conditions du problème on a : a=5 ; σ=  =0,8 ; α = 4 ; β = 7. En substituant ces données dans (3), nous obtenons :
=0,8 ; α = 4 ; β = 7. En substituant ces données dans (3), nous obtenons :
 =Ф(2,5)-Ф(-1,25)=
=Ф(2,5)-Ф(-1,25)=
=F(2,5)+F(1,25)=0,4938+0,3944=0,8882.
Exemple. On pense que l'écart de longueur des pièces fabriquées par rapport à la norme est une variable aléatoire distribuée selon une loi normale. Longueur standard (espérance mathématique) a=40 cm, écart type σ=0,4 cm Trouvez la probabilité que l'écart de la longueur par rapport à la norme soit. valeur absolue pas plus de 0,6 cm.
Solution.Si X est la longueur de la pièce, alors selon les conditions du problème, cette valeur doit être dans l'intervalle (a-δ,a+δ), où a=40 et δ=0,6.
En mettant α= a-δ et β= a+δ dans la formule (3), on obtient

 . (4)
. (4)
En substituant les données disponibles dans (4), nous obtenons :
Par conséquent, la probabilité que la longueur des pièces fabriquées soit comprise entre 39,4 et 40,6 cm est de 0,8664.
Exemple. Le diamètre des pièces fabriquées par une usine est une variable aléatoire distribuée selon une loi normale. Longueur de diamètre standard a=2,5 cm, écart type σ = 0,01. Dans quelles limites peut-on pratiquement garantir la longueur du diamètre de cette pièce si un événement avec une probabilité de 0,9973 est considéré comme fiable ?
Solution. Selon les conditions du problème on a :
a = 2,5 ; =0,01 ; .
En appliquant la formule (4), on obtient l'égalité :
 ou
ou  .
.
D'après le tableau 2, nous constatons que la fonction de Laplace a cette valeur à x=3. Ainsi,  ; d'où σ=0,03.
; d'où σ=0,03.
De cette façon, on peut garantir que la longueur du diamètre variera entre 2,47 et 2,53 cm.
Théorème 2 (Moivre-Laplace (local)). UN dans chacun n tests indépendants est égal à r névénement de test UN se produira une fois, est à peu près égal (plus n, plus la valeur de la fonction est précise)
![]() ,
,
Où ![]() , . Le tableau des valeurs des fonctions est donné en annexe. 1.
, . Le tableau des valeurs des fonctions est donné en annexe. 1.
Exemple 6.5. Probabilité de trouver cèpes entre autres est égal à . Quelle est la probabilité que parmi 300 cèpes il y en ait 75 ?
Solution. Selon les conditions du problème ![]() , . Nous trouvons
, . Nous trouvons  . Du tableau, nous trouvons
. Du tableau, nous trouvons ![]() .
.
 .
.
Répondre: ![]() .
.
Théorème 3 (Moivre-Laplace (intégrale)). Si la probabilité qu'un événement se produise UN dans chacun n tests indépendants est égal à r et est différent de zéro et un, et que le nombre de tests est suffisamment grand, alors la probabilité que dans n tests nombre de réussites m est compris entre et , à peu près égal (plus n, plus c'est précis)
 ,
,
Où r- probabilité de réussite à chaque test, ,  , les valeurs sont données en annexe. 2.
, les valeurs sont données en annexe. 2.
Exemple 6.6. Dans un lot de 768 pastèques, chaque pastèque n’est probablement pas mûre. Trouvez la probabilité que le nombre de pastèques mûres soit compris entre 564 et 600.
Solution. Par condition Par le théorème intégral de Laplace

Répondre:
Exemple 6.7. La ville est visitée quotidiennement par 1 000 touristes qui sortent déjeuner pendant la journée. Chacun d'eux choisit pour le déjeuner l'un des deux restaurants de la ville, avec des probabilités égales et indépendamment l'un de l'autre. Le propriétaire d'un des restaurants souhaite que, avec une probabilité d'environ 0,99, tous les touristes qui viennent dans son restaurant puissent y dîner en même temps. Combien de places doit-il y avoir dans son restaurant pour cela ?
Solution. Laisser UN= « le touriste a dîné avec le propriétaire intéressé. » Occurrence d'un événement UN Considérons cela comme un « succès » ![]() , . On s'intéresse à ce plus petit nombre k, que la probabilité d'occurrence n'est pas inférieure à k« succès » dans une séquence d'essais indépendants avec une probabilité de succès r= 0,5 est approximativement égal à 1 – 0,99 = 0,01. C'est précisément la probabilité que le restaurant soit surpeuplé. On s'intéresse donc à ce plus petit nombre k, Quoi . Appliquons le théorème intégral de Moivre-Laplace
, . On s'intéresse à ce plus petit nombre k, que la probabilité d'occurrence n'est pas inférieure à k« succès » dans une séquence d'essais indépendants avec une probabilité de succès r= 0,5 est approximativement égal à 1 – 0,99 = 0,01. C'est précisément la probabilité que le restaurant soit surpeuplé. On s'intéresse donc à ce plus petit nombre k, Quoi . Appliquons le théorème intégral de Moivre-Laplace

D'où il suit que
 .
.
Utiliser le tableau pour F(X) (Annexe 2), on trouve ![]() , Moyens . Le restaurant devrait donc disposer de 537 places assises.
, Moyens . Le restaurant devrait donc disposer de 537 places assises.
Répondre: 537 places.
Du théorème intégral de Laplace nous pouvons obtenir la formule
 .
.
Exemple 6.8. La probabilité qu'un événement se produise dans chacun des 625 essais indépendants est de 0,8. Trouvez la probabilité que la fréquence relative d'occurrence d'un événement s'écarte de sa probabilité en valeur absolue de pas plus de 0,04.
Théorème intégral de Laplace
Théorème. Si la probabilité p d'occurrence de l'événement A dans chaque essai est constante et différente de zéro et un, alors la probabilité que le nombre m d'occurrence de l'événement A dans n essais indépendants soit compris entre a et b (inclus) , avec suffisamment grand nombre tests n est approximativement égal à
La formule intégrale de Laplace, ainsi que la formule locale de Moivre-Laplace, plus précise est la plus n et plus la valeur est proche de 0,5 p Et q. Le calcul utilisant cette formule donne une erreur insignifiante si la condition est remplie npq≥ 20, bien que le respect de la condition puisse être considéré comme acceptable npq > 10.
Fonction Ф( x) sous forme de tableau (voir annexe 2). Pour utiliser ce tableau vous devez connaître les propriétés de la fonction Ф( x):
1. Fonction Ф( x) – étrange, c'est-à-dire F(– x) = – Ф( x).
2. Fonction Ф( x) – croissante de façon monotone, et comme x → +∞ Ф( x) → 0,5 (en pratique on peut supposer que déjà à x≥ 5F( x) ≈ 0,5).
Exemple 3.4. En utilisant les conditions de l'exemple 3.3, calculez la probabilité que de 300 à 360 étudiants (inclus) réussissent l'examen du premier coup.
Solution. Nous appliquons le théorème intégral de Laplace ( npq≥20). On calcule :
![]() = –2,5;
= –2,5; ![]() = 5,0;
= 5,0;
P. 400 (300 ≤ m≤ 360) = Ф(5,0) – Ф(–2,5).
Compte tenu des propriétés de la fonction Ф( x) et en utilisant le tableau de ses valeurs, on trouve : Ф(5,0) = 0,5 ; Ф(–2,5) = – Ф(2,5) = – 0,4938.
Nous obtenons P. 400 (300 ≤ m ≤ 360) = 0,5 – (– 0,4938) = 0,9938. ◄
Écrivons les conséquences du théorème intégral de Laplace.
Corollaire 1. Si la probabilité p d'occurrence de l'événement A dans chaque essai est constante et différente de zéro et un, alors avec un nombre n d'essais indépendants suffisamment grand, la probabilité que le nombre m d'occurrence de l'événement A diffère du produit np pas plus de ε > 0
| | (3.8) |
Exemple 3.5. Dans les conditions de l'exemple 3.3, trouvez la probabilité qu'entre 280 et 360 étudiants réussissent l'examen de théorie des probabilités du premier coup.
Solution. Calculer la probabilité R. 400 (280 ≤ m≤ 360) peut être similaire à l’exemple précédent en utilisant la formule intégrale de base de Laplace. Mais c'est plus facile à faire si vous remarquez que les limites de l'intervalle 280 et 360 sont symétriques par rapport à la valeur n.p.=320. Alors, d’après le corollaire 1, on obtient
![]() = = ≈
= = ≈
≈ ![]() = 2Ф(5,0) ≈ 2 0,5 ≈ 1,
= 2Ф(5,0) ≈ 2 0,5 ≈ 1,
ceux. Il est presque certain qu’entre 280 et 360 étudiants réussiront l’examen du premier coup. ◄
Corollaire 2. Si la probabilité p d'occurrence de l'événement A dans chaque essai est constante et différente de zéro et un, alors avec un nombre n d'essais indépendants suffisamment grand, la probabilité que la fréquence m/n de l'événement A soit comprise entre α à β (inclus) est égal à
| | (3.9) |
| Où | , . | (3.10) |
Exemple 3.6. Selon les statistiques, en moyenne 87 % des nouveau-nés vivent jusqu'à 50 ans. Trouvez la probabilité que sur 1 000 nouveau-nés, la proportion (fréquence) de ceux qui survivent jusqu'à 50 ans soit comprise entre 0,9 et 0,95.
Solution. La probabilité qu'un nouveau-né vive jusqu'à 50 ans est r= 0,87. Parce que n= 1000 est grand (c'est-à-dire la condition npq= 1000·0,87·0,13 = 113,1 ≥ 20 satisfait), alors on utilise le corollaire 2 du théorème intégral de Laplace. On retrouve :
2,82, = 7,52.
![]() = 0,5 – 0,4976 = 0,0024. ◄
= 0,5 – 0,4976 = 0,0024. ◄
Corollaire 3. Si la probabilité p d'occurrence de l'événement A dans chaque essai est constante et différente de zéro et un, alors avec un nombre n d'essais indépendants suffisamment grand, la probabilité que la fréquence m/n de l'événement A diffère de sa probabilité p de pas plus queΔ > 0 (en valeur absolue) est égal à
| | (3.11) |
Exemple 3.7. Selon les conditions du problème précédent, trouvez la probabilité que sur 1000 nouveau-nés, la proportion (fréquence) de ceux qui survivent jusqu'à 50 ans ne différera pas de la probabilité de cet événement de plus de 0,04 (en valeur absolue).
Solution. En utilisant le corollaire 3 du théorème intégral de Laplace, on trouve :
![]() = 2F(3,76) = 2·0,4999 = 0,9998.
= 2F(3,76) = 2·0,4999 = 0,9998.
Puisque inégalité équivaut à inégalité, ce résultat signifie qu'il est presque certain que de 83 à 91 % des nouveau-nés sur 1000 vivront jusqu'à 50 ans. ◄
Précédemment, nous avons établi que pour les essais indépendants, la probabilité que le nombre m occurrences de l'événement UN V n le test est trouvé en utilisant la formule de Bernoulli. Si n est grand, alors utilisez la formule asymptotique de Laplace. Cependant, cette formule ne convient pas si la probabilité de l'événement est faible ( r≤ 0,1). Dans ce cas ( n super, r peu) appliquer le théorème de Poisson
La formule de Poisson
Théorème. Si la probabilité p d’occurrence de l’événement A dans chaque essai tend vers zéro (p → 0) avec une augmentation illimitée du nombre n d'essais (n→ ∞), et le produit np tend vers un nombre constant λ (np → λ), alors la probabilité P n (m) que l'événement A apparaisse m fois dans n les essais indépendants satisfont à l'égalité limite
Algorithme de méthode base artificielle présente les caractéristiques suivantes :
1. En raison du fait que la solution de référence initiale du problème étendu contient des variables artificielles incluses dans la fonction objectif avec un coefficient - M.(dans une tâche maximale) ou + M.(dans le problème minimum), les estimations des expansions de vecteurs de conditions sont constituées de deux termes et  , dont l'un ne dépend pas de M., et l'autre
, dont l'un ne dépend pas de M., et l'autre  dépend de M.. Parce que M. arbitrairement grand par rapport à l'unité ( M>> 1), puis dans la première étape du calcul pour retrouver les vecteurs introduits dans la base, seuls les termes des estimations sont utilisés
dépend de M.. Parce que M. arbitrairement grand par rapport à l'unité ( M>> 1), puis dans la première étape du calcul pour retrouver les vecteurs introduits dans la base, seuls les termes des estimations sont utilisés  .
.
2. Les vecteurs correspondant à des variables artificielles dérivées de la base de la solution de référence sont exclus de la prise en compte.
3. Une fois tous les vecteurs correspondant aux variables artificielles exclus de la base, le calcul continue comme d'habitude méthode simplexe en utilisant des estimations indépendantes de M.
4. La transition de la résolution du problème étendu à la résolution du problème initial s'effectue à l'aide des théorèmes 4.1 à 4.3 prouvés ci-dessus.
Exemple 4.4. Résoudre le problème programmation linéaire méthode de base artificielle

 .
.
Solution. Créons une tâche étendue. Nous introduisons des variables artificielles non négatives avec un coefficient (toujours) +1 dans les membres gauches des équations du système de contraintes. Il est pratique d’écrire les variables artificielles introduites à droite des équations. Dans la première équation nous entrons , dans la seconde - . Ce problème est un problème de recherche du maximum, ils sont donc introduits dans la fonction objectif avec un coefficient - M.. Nous obtenons

Le problème a une solution de référence initiale  avec base unitaire
avec base unitaire  .
.
Nous calculons des estimations des vecteurs de condition sur la base de la solution de référence et de la valeur fonction objectif sur la solution de référence.




 .
.  .
.
Nous écrivons les données sources dans tableau simplexe(Tableau 4.6).

Tableau 4.6
Parallèlement, les estimations et  pour faciliter les calculs, nous écrivons sur deux lignes : dans la première - les termes qui ne dépendent pas de M., dans le second - les termes
pour faciliter les calculs, nous écrivons sur deux lignes : dans la première - les termes qui ne dépendent pas de M., dans le second - les termes  , selon M.. Valeurs
, selon M.. Valeurs  pratique à indiquer sans M., en gardant toutefois à l’esprit qu’il y est présent.
pratique à indiquer sans M., en gardant toutefois à l’esprit qu’il y est présent.
La solution de support initiale n’est pas optimale, puisque le problème maximum a des estimations négatives. Nous sélectionnons le numéro du vecteur entré dans la base de la solution de référence, et le numéro du vecteur sorti de la base. Pour ce faire, nous calculons les incréments de la fonction objectif lors de l'introduction de chacun des vecteurs avec une estimation négative dans la base et trouvons le maximum de cet incrément. Dans ce cas, les modalités des devis (sans M.) est négligé tant qu’au moins un terme  (Avec M.) ne sera pas différent de zéro. À cet égard, la ligne contenant les termes d'évaluation peut ne pas figurer dans le tableau tant qu'elle est présente.
(Avec M.) ne sera pas différent de zéro. À cet égard, la ligne contenant les termes d'évaluation peut ne pas figurer dans le tableau tant qu'elle est présente.  . On retrouve à k= 3.
. On retrouve à k= 3.
Dans la troisième colonne " ", nous sélectionnons le coefficient 1 dans la deuxième ligne comme élément de résolution et effectuons la transformation de Jordan.
Le vecteur dérivé de la base est exclu de la considération (barré). On obtient la solution de référence  avec base
avec base  (Tableau 4.7). La solution n'est pas optimale car il existe une estimation négative
(Tableau 4.7). La solution n'est pas optimale car il existe une estimation négative  = —
1.
= —
1.
Tableau 4.7

Dans la colonne " " nous prenons le seul élément positif comme permissif et passons à un nouveau solution de référence  avec base
avec base  (Tableau 4.8).
(Tableau 4.8).

Tableau 4.8
Cette solution de référence est la seule solution optimale au problème étendu, puisque dans le problème maximum, les estimations de tous les vecteurs non inclus dans la base sont positives. D'après le théorème 4.1, le problème original a également une solution optimale, qui est obtenue à partir de la solution optimale du problème étendu en écartant zéro variable artificielle, c'est-à-dire X* = (0,0,6,2).
Répondre:maximum Z(X) = -10 à  .
.
Exemple 4.5. Résoudre un problème de programmation linéaire avec contraintes mixtes en utilisant la méthode des bases artificielles


Solution. Nous apportons le problème de programmation linéaire sous forme canonique. Pour ce faire, nous introduisons des variables supplémentaires respectivement dans les première et troisième contraintes. Nous obtenons

 .
.
Nous créons un problème étendu pour lequel nous introduisons des variables artificielles dans les deuxième et troisième équations, respectivement. Nous obtenons

Ce problème étendu a une solution de support initiale
Avec base unitaire  ,
,  . Nous calculons des estimations des vecteurs de condition sur la base de la solution de référence et les écrivons dans le tableau simplex de la même manière que dans l'exemple précédent. La solution n’est pas optimale, puisque dans le problème minimum les vecteurs et ont des estimations positives. Améliorer les solutions de support. Chaque solution de référence possède son propre tableau. Tous les tableaux peuvent être écrits les uns en dessous des autres, en les combinant en un seul tableau (tableau 4.9).
. Nous calculons des estimations des vecteurs de condition sur la base de la solution de référence et les écrivons dans le tableau simplex de la même manière que dans l'exemple précédent. La solution n’est pas optimale, puisque dans le problème minimum les vecteurs et ont des estimations positives. Améliorer les solutions de support. Chaque solution de référence possède son propre tableau. Tous les tableaux peuvent être écrits les uns en dessous des autres, en les combinant en un seul tableau (tableau 4.9).
Tableau 4.9

Nous déterminons lequel des vecteurs ou dans la base de la solution de support initiale conduira à une plus grande réduction fonction cible. On retrouve à k= 2, c'est-à-dire qu'il vaut mieux introduire le vecteur dans la base. On obtient la deuxième solution de support avec la base  . Fonction objectif
. Fonction objectif  . Cette solution n'est pas non plus optimale, puisque le vecteur a une valeur positive
. Cette solution n'est pas non plus optimale, puisque le vecteur a une valeur positive  . On introduit le vecteur dans la base, on obtient la troisième solution de référence avec la base
. On introduit le vecteur dans la base, on obtient la troisième solution de référence avec la base  . Fonction objectif
. Fonction objectif  . Cette solution est optimale, mais pas la seule, puisque le vecteur non inclus dans la base a une estimation nulle. Il est donc nécessaire de passer à une nouvelle solution de référence, qui sera également optimale. Pour ce faire, vous devez introduire le vecteur dans la base.
. Cette solution est optimale, mais pas la seule, puisque le vecteur non inclus dans la base a une estimation nulle. Il est donc nécessaire de passer à une nouvelle solution de référence, qui sera également optimale. Pour ce faire, vous devez introduire le vecteur dans la base.
Passons à la quatrième solution de référence (optimale)
Avec base  , alors que
, alors que  . Les solutions optimales au problème étendu n’ont aucune variable artificielle. Par conséquent (d’après le théorème 4.1), le problème initial a également deux solutions optimales
. Les solutions optimales au problème étendu n’ont aucune variable artificielle. Par conséquent (d’après le théorème 4.1), le problème initial a également deux solutions optimales  Et
Et  . Variables supplémentaires dans solution optimale Nous n'écrivons pas la tâche initiale.
. Variables supplémentaires dans solution optimale Nous n'écrivons pas la tâche initiale.
Répondre:  à
à  ,
, ![]() ,
,  ,
,  .
.
Le mot simplexe
Le mot simplex en lettres anglaises (translit) - simpleks
Le mot simplex se compose de 8 lettres : e et k l m p s s
Significations du mot simplexe. Qu’est-ce que le simplexe ?
Simplexe
Simplex (du latin simplex - simple) (mathématique), le polyèdre convexe le plus simple numéro donné dimensions n.m. Lorsque n = 3, la structure tridimensionnelle est un tétraèdre arbitraire, y compris irrégulier.
BST. - 1969-1978
Un simplexe est un polygone convexe dans un espace à n dimensions avec n+1 sommets qui ne se trouvent pas dans le même hyperplan. S. sont distingués comme une classe distincte car dans l'espace à n dimensions, n points se trouvent toujours dans le même hyperplan.
slovar-lopatnikov.ru
SIMPLEX est un polygone convexe dans un espace à n dimensions avec n+1 sommets qui ne se trouvent pas dans le même hyperplan. S. sont distingués comme une classe distincte car dans l'espace à n dimensions, n points se trouvent toujours dans le même hyperplan.
Lopatnikov. - 2003
Sous simplexe
Sub simplex Conseil d'utilisation et posologie : Par voie orale, pendant ou après les repas et, si nécessaire, avant le coucher. Agiter vigoureusement le flacon avant utilisation.
Résoudre le ZLP par la méthode simplexe avec une base artificielle
Pour que la suspension commence à s'écouler de la pipette...
Sab simplex Principe actif ›› Siméthicone* (Siméthicone*) Nom latin Sab simplex ATX :›› A02DA Médicaments carminatifs Groupe pharmacologique…
Dictionnaire des médicaments. — 2005
SAB® SIMPLEX (SAB® SIMPLEX) Suspension buvable de couleur blanche à gris-blanc, légèrement visqueuse, avec une odeur fruitée caractéristique (vanille-framboise). 100 ml de siméthicone 6,919 g…
CHOC SIMPLEX
CHOQUET SIMPLEX est un ensemble convexe compact non vide X dans un espace localement convexe E, qui a la propriété suivante : lorsque E est plongé en hyperplan dans l'espace, il existe un cône saillant.
Simplex de Sheffield
"Sheffield-Simplex" - véhicule blindé léger avec mitrailleuse Forces armées Empire russe. Développé par la société britannique Sheffield-Simplex sur la base du châssis de sa propre voiture de tourisme...
fr.wikipedia.org
Norditropine Simplex
Norditropin Simplex Indications : Retard de croissance chez les enfants dû à un déficit en hormone de croissance ou à une insuffisance rénale chronique (à l'âge prépubère), syndrome de Shereshevsky-Turner...
NORDITROPIN® SIMPLEX® (NORDITROPIN SimpleXx) Solution pour administration sous-cutanée 1,5 ml (1 cartouche) somatropine 10 mg 1,5 ml - cartouches (1) - emballage de cellules de contour (1) - emballages en carton.
Répertoire des médicaments "Vidal"
SIMPLEX STANDARD
SIMPLEX STANDARD - 1) S. s. - un simplexe de dimension n dans l'espace avec des sommets aux points e i=(0,..., 1,..., 0), i=0,..., n (le l'unité est allumée i-ème place), c'est-à-dire
Encyclopédie mathématique. — 1977-1985
Méthode double simplexe
La méthode du double simplex peut être utilisée pour résoudre un problème de programmation linéaire dont les termes libres du système d'équations peuvent être n'importe quel nombre. Dans un algorithme simplexe régulier, le plan doit toujours être réalisable.
fr.wikipedia.org
langue russe
Simplex/.
Dictionnaire d'orthographe morphémique. - 2002
Rechercher des conférences
Un exemple de résolution d'un problème en utilisant la méthode des bases artificielles.
Trouver le minimum d'une fonction F=-2×1+3×2 – 6×3 – x4 dans des conditions

Solution.Écrivons-le cette tâche sous la forme du problème principal : trouver le maximum de la fonction F1=2×1 – 3×2 + 6×3 + x4 dans des conditions

Dans le système d'équations du dernier problème, considérons les vecteurs des coefficients pour les inconnues :
A1= A2= UN 3= UN 4= UN 5= UN 6=
Parmi les vecteurs A1,…, UN 6 seulement deux simples ( UN 4 et UN 5). Donc dans côté gauche de la troisième équation du système de restrictions, on ajoute une variable supplémentaire non négative x 7 et considérons le problème étendu de la maximisation de la fonction
F=2×1 – 3×2 + 6×3 + x4 – Mx7
dans des conditions

Le problème étendu a un plan de référence X=(0; 0; 0; 24; 22; 0; 10), défini par un système de trois vecteurs unitaires : UN 4 , A5 , A7 .
Tableau 1
| je | Base | σ | A0 | -3 | —M. | |
| A1 | A2 | A3 | A4 | A5 | A6 | P7 |
| A4 | -2 | |||||
| A5 | ||||||
| A7 | —M. | -1 | -1 | |||
| m+1 | -8 | |||||
| m+2 | -10 | -1 | -2 |
Nous compilons le tableau (1) de l'itération I, contenant cinq lignes. Pour remplir les 4ème et 5ème lignes on trouve F 0 et valeurs de différence zj – cj(j=):
F 0 = 24 à 10 M ;
z1–c1= 0–M.;
z2–c2 = 4+M.;
z3–c3= –8–2M.;
z4–c4=0+M.;
z5–c5=0+M.;
z6–c6= 0+M.;
z7–c7=0+M.;
Valeurs F 0 et zj-cj se composent de deux termes, dont l'un contient M., et l'autre ne l'est pas.
Pour la commodité du processus itératif, le nombre composé de M., écrivez à la 5ème ligne, et le terme qui ne contient pas M., – en 4ème ligne.
A la 5ème ligne du tableau 1 dans les colonnes des vecteurs Aj (j= ) il y a deux nombres négatifs (-1 Et -2). La présence de ces nombres indique que ce plan de référence pour le problème étendu n'est pas optimal. Passons au nouveau plan de référence du problème étendu.
Méthode de base artificielle.
On introduit le vecteur dans la base A3. Pour déterminer le vecteur exclu de la base, on trouve θ=min(22/4; 10/2)=10/2. Par conséquent, le vecteur A7 exclus de la base. Cela n'a aucun sens d'entrer ce vecteur dans l'une des bases suivantes, donc à l'avenir la colonne de ce vecteur ne sera pas remplie (Tableaux 2 et 3).
Nous composons le tableau II d'itération (Tableau 2). Il ne contient que quatre lignes, puisque le vecteur artificiel est exclu de la base.
Tableau2
| je | Base | σ | A0 | -3 | |
| A1 | A2 | A3 | A4 | A5 | A6 |
| A4 | -1 | ||||
| A5 | -1 | ||||
| A3 | 1/2 | -1/2 | -1/2 | ||
| m+1 | -4 |
Comme le montre le tableau. 2, pour le problème d'origine la référence est le plan X=(0;0;5;34;2).
Vérifions son optimalité. Pour ce faire, considérons les éléments de la 4ème ligne. Dans cette ligne de la colonne vectorielle A6 disponible nombre négatif(-4). Par conséquent, ce plan de référence n’est pas optimal et peut être amélioré en introduisant le vecteur A6. Le vecteur est exclu de la base A5. Nous compilons le tableau III d'itération.
Tableau 3
Dans la 4ème ligne du tableau 3 parmi les nombres ∆j pas de points négatifs. Cela signifie que le nouveau plan de référence trouvé du problème d'origine X*=(0 ; 0 ; 11/2 ; 35 ; 0 ; 1) est optimal. À cet égard, la valeur forme linéaireFmax = 68.
La solution à ce problème peut être réalisée à l'aide d'un seul tableau dans lequel toutes les itérations sont enregistrées séquentiellement.
©2015-2018 poisk-ru.ru
Tous les droits appartiennent à leurs auteurs. Ce site ne revendique pas la paternité, mais fournit utilisation gratuite.
Violation du droit d'auteur et violation des données personnelles
Une condition nécessaire pour utiliser la méthode simplexe est la présence d'un plan de référence, c'est-à-dire une solution de base acceptable système canoniqueéquations. Pour ce faire, vous devez remplir conditions suivantes:
- le système doit avoir une structure canonique (par étapes) ;
- il n'y a que des contraintes d'égalité ;
- les membres droits des contraintes sont positifs ;
- variables de tâche sont positifs.
Sans ces conditions, il est impossible d’obtenir un plan de référence. Cependant, dans les problèmes réels, les conditions énumérées ne sont pas toujours remplies.
Existe méthode spéciale, appelée base artificielle, qui permet d'obtenir un plan de référence initial dans tout problème de programmation linéaire.
Réduisons le problème de programmation linéaire à sa forme standard :
Laissez tout /? > 0, mais certaines ou toutes les variables de base sont négatives, X ; 0. Il n’existe donc pas de plan de référence.
Complétons les équations de contraintes par des variables artificielles (nous supposons que toutes xj j-1, n).
Présentons T variables (par nombre d'équations) : x lM ceux qui sont dans nouveau système sera basique et négatif X-
En conséquence, nous obtenons le problème équivalent suivant.

Voici les variables xn+i n'ont rien à voir avec le problème de programmation linéaire d'origine. Elles servent uniquement à obtenir un plan de référence et sont appelées variables artificielles. Et le nouveau
la fonction cible /(.t) est formée pour l'exhaustivité du problème.
Dans un plan de référence optimal, les variables artificielles devraient être nulles. Sinon, les conditions du problème initial seront violées.
Dans le plan de référence initial, les variables artificielles sont basiques, c'est-à-dire non égales à zéro, mais en plan optimal les variables artificielles doivent être nulles. Cela signifie que les variables artificielles doivent devenir libres de manière optimale. Cette traduction est l'idée principale de la méthode : la traduction de variables artificielles de variables de base en variables libres. Examinons le mécanisme d'une telle traduction à l'aide d'un exemple.

Réécrivons le ZLP en formulaire standard. Pour ce faire, nous introduisons des variables supplémentaires x ) , x A, x 5 , x 6 et écris le problème dans forme canonique.

Variables libres x, X 2 = 0, auquel cas les variables de base prendront les valeurs x 3 = -5, x 4 = -5, x 5 = 7, x 6 = 9. Puisque certaines des variables de base sont négatives, il n’existe pas de plan de référence. Pour obtenir le plan de référence initial, nous introduisons les variables x 7, x 8 dans les deux premières équations de contraintes et formulons un problème auxiliaire :

Ainsi, la base initiale est
Table simplex avec base artificielle
|
X4 |
|||||||||||
Écrivons les séquences plans de référence.
Pour les trois premières étapes d'incrémentation Et à sont calculés uniquement à partir de variables artificielles incluses dans la fonction objectif artificielle /(x) =x 7 + x 8 avec coefficient c, = 1.
Dans la troisième étape, les variables artificielles sont exclues, puisque toutes Et à sont positifs.

Ainsi, la méthode simplexe avec introduction de variables artificielles comprend deux étapes.
Formation et solution d'un problème LP auxiliaire avec introduction de variables artificielles. Les variables artificielles du plan de référence initial sont fondamentales. Une fonction objectif artificielle ne comprend que des variables artificielles. Dès réception des plans de référence adjacents, nous transférons les variables artificielles des variables de base aux variables gratuites. En conséquence, le plan de référence optimal pour le problème auxiliaire /(x) = 0 a été obtenu.
Le plan de référence optimal pour le problème LP auxiliaire est le plan de référence initial pour le problème LP principal. Le problème est résolu pour la fonction objectif originale /(x) en utilisant la méthode simplex habituelle.
Remarques
- 1. L'introduction de variables artificielles est requise dans deux cas :
- un certain nombre de variables de base x sont négatives sous forme canonique ;
- s'il est difficile de le réduire à une forme canonique, ajoutez simplement une variable artificielle à n'importe quelle équation de contrainte.
- 2. Se produisant dans la pratique contrôle automatique Les problèmes de programmation linéaire contiennent de 500 à 1 500 contraintes et plus de 1 000 variables. Il est clair que des problèmes de cette dimension ne peuvent être résolus qu'avec l'aide d'un ordinateur et d'un outil spécial. logiciel. La complexité de l'algorithme réside dans le fait que :
- PPP nécessite forme canonique;
- PPP pour des problèmes de cette taille nécessite l'utilisation de gros ordinateurs (et calcul parallèle), puisque la méthode simplex stocke la table entière.
- 3. L'efficacité de calcul de la méthode simplex peut être évaluée par les indicateurs suivants :
- nombre de marches (plans de soutènement adjacents) ;
- coûts de temps informatique.
Il existe de telles estimations théoriques pour tâche standard programmation linéaire avec T restrictions et variables :
- nombre moyen de pas * 2 T et se situe dans la plage)