Bash перенаправление вывода в файл. Перенаправление вывода в файл
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом - это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках - информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата - число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux - файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 - этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 - это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 - все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов "<" и ">" .
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n - повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:

Символ ">" перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте ">>" . Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок - это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:

Вы можете перенаправить стандартный поток ошибок в файл так:
ls -l /root/ 2> ls-error.log
$ cat ls-error.log

Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log

Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1

Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора "<" :
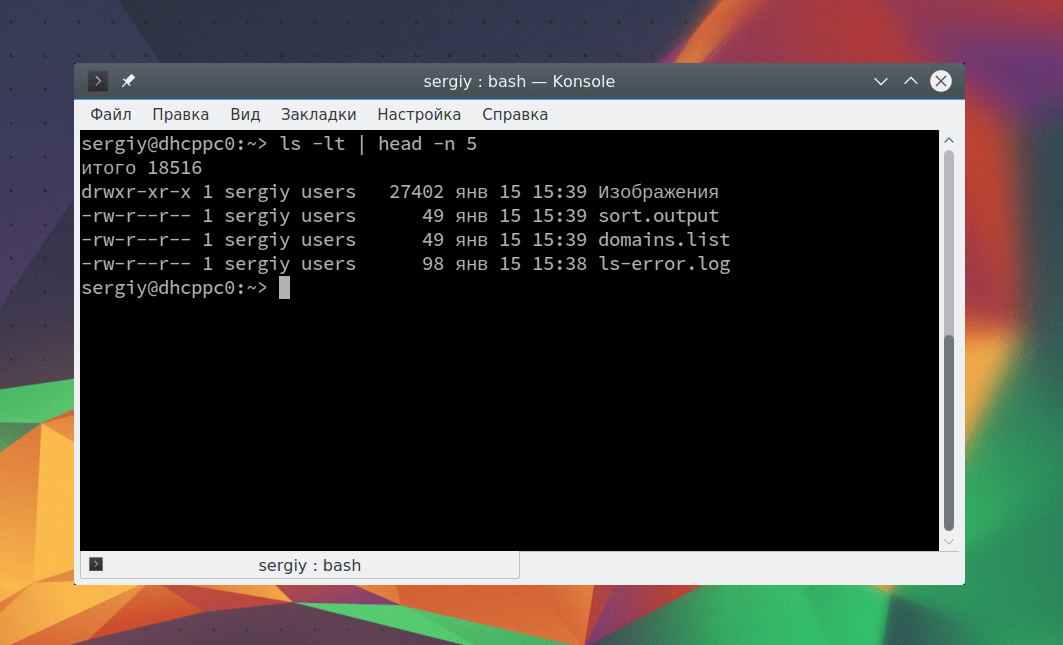
cat Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список: sort Таким образом, мы в одной команде перенаправляем ввод вывод linux. Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов: ls -lt | head -n 5 С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок: echo test/ tmp/ | xargs -n 1 cp -v testfile.sh Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда - это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например: echo "Тест работы tee" | tee file1 В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд. В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях! С помощью переназначения устройств ввода/вывода одна программа может направить свой вывод на вход другой или перехватить вывод другой программы, используя его в качестве своих входных данных. Таким образом, имеется возможность передавать информацию от процесса к процессу при минимальных программных издержках. Практически это означает, что для программ, которые используют стандартные входные и выходные устройства, операционная система позволяет: Из командной строки эти возможности реализуются следующим образом. Для того, чтобы перенаправить текстовые сообщения, выводимые какой-либо командой из командной строки, в текстовый файл, нужно использовать конструкцию команда > имя_файла.
Если при этом заданный для вывода файл уже существовал, то он перезаписывается (старое содержимое теряется), если не существовал создается. Можно также не создавать файл заново, а дописывать информацию, выводимую командой, в конец существующего файла. Для этого команда перенаправления вывода должна быть задана так: команда >> имя_файла
. С помощью символа < можно прочитать входные данные для заданной команды не с клавиатуры, а из определенного (заранее подготовленного) файла: команда < имя_файла Приведем несколько примеров перенаправления ввода/вывода. 1. Вывод результатов команды ping
в файл ping ya.ru > ping.txt
2. Добавление текста справки для команды XCOPY в файл copy.txt: XCOPY /? >> copy.txt
В случае необходимости сообщения об ошибках (стандартный поток ошибок) можно перенаправить в текстовый файл с помощью конструкции команда 2> имя_файла В этом случае стандартный вывод будет производиться на экран. Также имеется возможность информационные сообщения и сообщения об ошибках выводить в один и тот же файл. Делается это следующим образом: команда > имя_файла 2>&1
Например, в приведенной ниже команде стандартный выходной поток и стандартный поток ошибок перенаправляются в файл copy.txt: XCOPY A:\1.txt C: > copy.txt 2>&1
1403
Потоки вывода
Сообщения скриптов выводятся во вполне определенные потоки - потоки вывода. Таким образом то, что мы выводим через echo "Hello, world!" Не просто выводится на экран, а, с точки зрения системы, а конкретно - командных интерпретаторов sh и bash - выводится через определенный поток вывода. В случае echo - поток под номером 1 (stdout), с которым ассоциирован экран. Некоторые программы и скрипты так-же используют другой поток вывода - под номером 2 (stderr). В него они выводят сообщения об ошибках. Благодаря этому можно раздельно выхватывать из потоков обычные информационные сообщения и сообщения об ошибках и направлять и обрабатывать их раздельно. Например, Вы можете заблокировать вывод информационных сообщения, оставив только сообщения об ошибках. Или направить вывод сообщений об ошибках в отдельный файл для логирования. Что такое ">somefile"
Такой записью в Unix (в интерпретаторах bash и sh) указывается перенаправление потоков вывода. В следующем примере мы перенаправим все информационные (обычные) сообщения команды ls в файл myfile.txt, получив таким образом в этом файле просто список ls: $ ls > myfile.txt Однако давайте сделаем заведомо ошибочную операцию: $ ls /masdfasdf > myfile.txt Т.к. поток stderr (2) мы никуда не перенаправили - сообщение об ошибке появится на экране и НЕ появится в файле myfile.txt А теперь давайте выполним команду ls так, чтобы информационные данные записались в файл myfile.txt, а сообщения об ошибках - в файл myfile.err, при этом на экране во время выполнения не появится ничего: $ ls >myfile.txt 2>myfile.err Конечно, мы можем оба потока направить в один файл или в одно и то же устройство. 2>&1
Нередко в скриптах можно встретить такую запись. Она означает: "Поток с номером 2 перенаправить в поток с номером 1", или "Поток stderr - направить через поток stdout". Т.е. все сообщения об ошибках мы направляем через поток, через который обычно печатаются обычные, не ошибочные сообщения. $ ls /asfasdf 2>&1 $ ls /asfasdf >myfile.txt 2>&1 /dev/null
Однако иногда нам нужно просто скрыть все сообщения - не сохраняя их. Т.е. просто блокировать вывод. Для этого служит виртуальное устройство /dev/null. В следующем примере весь вывод обычных сообщений команды ls мы направим в /dev/null: $ ls > /dev/null $ ls > /dev/null 2>&1 $ ls >/dev/null 2>/dev/null $ ls 2>/dev/null Заметьте, что здесь уже нельзя указывать "2>&1", т.к. поток (1) не перенаправлен никуда и в таком случае сообщения об ошибках будут банально вывалены на экран. Что первее - яйцо или курица?
Я приведу Вам здесь 2 примера. Пример 1) $ ls >/dev/null 2>&1 $ ls 2>&1 >/dev/null Дело в том, что интерпретаторы читают и применяют перенаправления слева направо. И сейчас мы разберем оба примера. Пример 1 1) ">/dev/null" - мы направляем поток 1 (stdout) в /dev/null. Все сообщения, попадающие в поток (1) - будут направлены в /dev/null. 2) "2>&1" - мы перенаправляем поток 2 (stderr) в поток 1 (stdout). Но, т.к. поток 1 уже ассоциирован с /dev/null - все сообщения все-равно попадут в /dev/null. Результат: на экране - пусто. Пример 2 1) "2>&1" - мы перенаправляем поток ошибок stderr (2) в поток stdout (1). При этом, т.к. поток 1 по-умолчанию ассоциирован с терминалом - сообщения об ошибках мы успешно увидим на экране. 2) ">/dev/null" - а уже здесь мы перенаправляем поток 1 в /dev/null. И обычные сообщения мы не увидим. Результат: мы будем видеть сообщения об ошибках на экране, но не будет видеть обычные сообщения. Вывод: сначала перенаправьте поток, а потом на него ссылайтесь. Вы уже знакомы с двумя методами работы с тем, что выводят сценарии командной строки: Каждому процессу позволено иметь до девяти открытых дескрипторов файлов. Оболочка bash резервирует первые три дескриптора с идентификаторами 0, 1 и 2. Вот что они означают. Многие команды bash принимают ввод из STDIN , если в командной строке не указан файл, из которого надо брать данные. Например, это справедливо для команды cat . Когда вы вводите команду cat в командной строке, не задавая параметров, она принимает ввод из STDIN . После того, как вы вводите очередную строку, cat просто выводит её на экран. Итак, у нас есть некий файл с данными, к которому мы можем добавить другие данные с помощью этой команды: Pwd >> myfile
Перенаправление вывода команды в файл
Пока всё хорошо, но что если попытаться выполнить что-то вроде показанного ниже, обратившись к несуществующему файлу xfile , задумывая всё это для того, чтобы в файл myfile попало сообщение об ошибке. Ls –l xfile > myfile
При попытке обращения к несуществующему файлу генерируется ошибка, но оболочка не перенаправила сообщения об ошибках в файл, выведя их на экран. Но мы-то хотели, чтобы сообщения об ошибках попали в файл. Что делать? Ответ прост - воспользоваться третьим стандартным дескриптором. Итак, предположим, что надо перенаправить сообщения об ошибках, скажем, в лог-файл, или куда-нибудь ещё, вместо того, чтобы выводить их на экран. Ls -l xfile 2>myfile
cat ./myfile
Ls –l myfile xfile anotherfile 2> errorcontent 1> correctcontent
Оболочка перенаправит то, что команда ls обычно отправляет в STDOUT , в файл correctcontent благодаря конструкции 1> . Сообщения об ошибках, которые попали бы в STDERR , оказываются в файле errorcontent из-за команды перенаправления 2> . Если надо, и STDERR , и STDOUT можно перенаправить в один и тот же файл, воспользовавшись командой &> : После выполнения команды то, что предназначено для STDERR и STDOUT , оказывается в файле content . #!/bin/bash
echo "This is an error" >&2
echo "This is normal output"
Запустим скрипт так, чтобы вывод STDERR попадал в файл. ./myscript 2> myfile
#!/bin/bash
exec 1>outfile
echo "This is a test of redirecting all output"
echo "from a shell script to another file."
echo "without having to redirect every line"
Если просмотреть файл, указанный в команде перенаправления вывода, окажется, что всё, что выводилось командами echo , попало в этот файл. Команду exec можно использовать не только в начале скрипта, но и в других местах: #!/bin/bash
exec 2>myerror
echo "This is the start of the script"
echo "now redirecting all output to another location"
exec 1>myfile
echo "This should go to the myfile file"
echo "and this should go to the myerror file" >&2
Сначала команда exec задаёт перенаправление вывода из STDERR в файл myerror . Затем вывод нескольких команд echo отправляется в STDOUT и выводится на экран. После этого команда exec задаёт отправку того, что попадает в STDOUT , в файл myfile , и, наконец, мы пользуемся командой перенаправления в STDERR в команде echo , что приводит к записи соответствующей строки в файл myerror. Освоив это, вы сможете перенаправлять вывод туда, куда нужно. Теперь поговорим о перенаправлении ввода. Exec 0< myfile
#!/bin/bash
exec 0< testfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(($count + 1))
done
В одном из предыдущих материалов вы узнали о том, как использовать команду read для чтения данных, вводимых пользователем с клавиатуры. Если перенаправить ввод, сделав источником данных файл, то команда read , при попытке прочитать данные из STDIN , будет читать их из файла, а не с клавиатуры. Некоторые администраторы Linux используют этот подход для чтения и последующей обработки лог-файлов. Назначить дескриптор для вывода данных можно, используя команду exec: #!/bin/bash
exec 3>myfile
echo "This should display on the screen"
echo "and this should be stored in the file" >&3
echo "And this should be back on the screen"
После окончания чтения файла можно восстановить STDIN и пользоваться им как обычно: #!/bin/bash
exec 6<&0
exec 0< myfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(($count + 1))
done
exec 0<&6
read -p "Are you done now? " answer
case $answer in
y) echo "Goodbye";;
n) echo "Sorry, this is the end.";;
esac
В этом примере дескриптор файла 6 использовался для хранения ссылки на STDIN . Затем было сделано перенаправление ввода, источником данных для STDIN стал файл. После этого входные данные для команды read поступали из перенаправленного STDIN , то есть из файла. После чтения файла мы возвращаем STDIN в исходное состояние, перенаправляя его в дескриптор 6 . Теперь, для того, чтобы проверить, что всё работает правильно, скрипт задаёт пользователю вопрос, ожидает ввода с клавиатуры и обрабатывает то, что введено. #!/bin/bash
exec 3> myfile
echo "This is a test line of data" >&3
exec 3>&-
echo "This won"t work" >&3
Всё дело в том, что мы попытались обратиться к несуществующему дескриптору. Будьте внимательны, закрывая дескрипторы файлов в сценариях. Если вы отправляли данные в файл, потом закрыли дескриптор, потом - открыли снова, оболочка заменит существующий файл новым. То есть всё то, что было записано в этот файл ранее, будет утеряно. У этой команды есть множество ключей, рассмотрим самые важные. Ключ -a используется для выполнения операции логического И над результатами, возвращёнными благодаря использованию двух других ключей: Lsof -a -p $$ -d 0,1,2
Тип файлов, связанных с STDIN , STDOUT и STDERR - CHR (character mode, символьный режим). Так как все они указывают на терминал, имя файла соответствует имени устройства, назначенного терминалу. Все три стандартных файла доступны и для чтения, и для записи. Посмотрим на вызов команды lsof из скрипта, в котором открыты, в дополнение к стандартным, другие дескрипторы: #!/bin/bash
exec 3> myfile1
exec 6> myfile2
exec 7< myfile3
lsof -a -p $$ -d 0,1,2,3,6,7
Скрипт открыл два дескриптора для вывода (3 и 6) и один - для ввода (7). Тут же показаны и пути к файлам, использованных для настройки дескрипторов. Вот, например, как подавить вывод сообщений об ошибках: Ls -al badfile anotherfile 2> /dev/null
Cat /dev/null > myfile
В следующий раз поговорим о сигналах Linux, о том, как обрабатывать их в сценариях, о запуске заданий по расписанию и о фоновых задачах. Уважаемые читатели! В этом материале даны основы работы с потоками ввода, вывода и ошибок. Уверены, среди вас есть профессионалы, которые могут рассказать обо всём этом то, что приходит лишь с опытом. Если так - передаём слово вам. Доброго времени, читатели моего ! Теперь простыми словами опишем, что эти три пункта обозначают: stdout
- стандартный поток вывода. Это, говоря простым языком, та информация, которую мы видим в интерпретаторе при выполнении команд. То есть все сообщения (без сообщений об ошибках), которые выполняемая в интерпретаторе команда сообщает и выводит на терминал (читай - экран). (вывод на экран задан по умолчанию, но можно указать и вывод, например в файл или перенаправление в другую команду, как это делается, расскажу ниже) stderr
- поток ошибок. Это ошибки при выполнении команд в bash, которые по умолчанию выводятся на stdout, то есть на терминал (опять же, если не указан вывод в другое место) stdin
- поток ввода. Это, говоря простым языком - то, что мы вводим с клавиатуры в интерпретатор для выполнения команды. Очень хорошо данные потоки изображены на рисунке, взятом с http://rus-linux.net/: На данном изображении: Stdin
, показан зеленым, имеет дескриптор 0 Далее расскажу, как данные потоки можно перенаправить в/из файл. То есть при выполнении команды, чтобы сообщения или ошибки выводились не на экран, а записывались в файл. Для чего это нужно? Ну например вы выполняете какую-то команду, у которой вывод не помещается в окно терминала. Вы указываете сохранять стандартный вывод в один файл, а стандартный поток ошибок в другой. Тем самым, все ошибки и если нужно стандартный вывод, можно будет посмотреть подробно, открыв сохраненные файлы. Итак, перенаправление потоков выполняется следующим образом:
$ command n>file
В данной строке показано: выполнение команды command
и перенаправление потока (где n
= дескриптору потока) в файл file.
При выполнении данного перенаправления, если конечный файл существует, он будет перезаписан
. При этом, если n не указан, то предполагается стандартный вывод.
$ command n>>file
Данная команда имеет аналогичный синтаксис, но тут указан символ ">>". При данном перенаправлении, если конечный файл существует, то вывод команды будет добавлен к имеющимся данным.
$ command < file
в данном примере команда command
выполняется и использует в качестве источника ввода, файл file,
вместо ввода с клавиатуры Иногда возникает необходимость объединить стандартный поток ошибок со стандартным потоком вывода, чтобы можно было обрабатывать ошибки и обычные результаты работы программы вместе. для этих целей используется комбинация с символом: &. Пример выполнения данного действия: Find / -name .name_file > /path/to/file 2>&1
При выполнении данной команды, происходит поиск файла от корня файловой системы с именем .name_file
и перенаправление результатов поиска (stdout и stderr) в файл /path/to/file
. Конструкция > /path/to/file 2>&1
перенаправляет стандартный вывод в /path/to/file
и вывод ошибок в стандартный вывод. При этом: написание 2>&1 перед > не будет работать, так как когда интерпретатор прочитает 2>&1 , он еще не знает куда перенаправлен стандартный поток вывода, поэтому потоки ошибок и вывода не будут объединены.
$ command > file 2>&1
аналогична написанию:
$ command &> file
$ command 2>&file
Если необходимо проигнорировать вывод, его можно направить в устройство /dev/null, это своего рода "черная дыра", принимающая любое количество информации и превращающая ее в ничто. Думаю приведенной информации о перенаправлении потоко будет достаточно для понимания сути, теперь расскажу о конвеерной передаче
. Конвеер в Linux
- это возможность нескольких программ работать совместно, когда выход одной программы непосредственно передается на вход другой без использования промежуточных временных файлов. Синтаксис использования конвеера следующий:
$ command1 | command2
В данном примере выполняется команда command1
, ее поток вывода используется, как поток ввода при выполнении command2
. На сегодня все. Буду рад комментариям и дополнениям. Спасибо. С Уважением, Mc.Sim!


Использование тоннелей


Выводы
Примеры перенаправления ввода/вывода в командной строке
При этом после нажатия на Enter Вы не увидите ничего на экране, зато в файле myfile.txt будет находится все то, что должно было отобразиться на экране.
И что случится? Т.к. директории masdfasdf в корне файловой системы не существует (я так предполагаю - вдруг у Вас есть?), то команда ls сгенерирует ошибку. Однако вывалит эту ошибку она уже не через обычный поток stdout (1), а через поток ошибок stderr (2). А перенаправление задано лишь для stdout ("> myfile.txt").
Здесь нам встречается впервые указание номера потока в качестве перенаправления. Запись "2>myfile.err" указывает, что поток с номером 2 (stderr) нужно перенаправить в файл myfile.err.
А вот еще пример, в котором все сообщения перенаправляются в файл myfile.txt:
При этом все сообщения, как об ошибках, так и обычные, будут записаны в myfile.txt, т.к. поток stdout мы сначала перенаправлили в файл, а потом указали, что ошибки нужно вываливать в stdout - соответственно, в файл myfile.txt
На экране не будет отображено ничего, кроме сообщений об ошибках. А в следующем примере - и сообщения об ошибках будут блокированы:
Причем эта запись эквивалентна записи вида:
А в следующем примере мы заблокируем только сообщения об ошибках:
Пример 2)
С виду - от перестановки мест слогаемых сумма не меняется. Но порядок указателей перенаправления играет роль!
Иногда что-то надо показать на экране, а что-то - записать в файл, поэтому нужно разобраться с тем, как в Linux обрабатывается ввод и вывод, а значит - научиться отправлять результаты работы сценариев туда, куда нужно. Начнём с разговора о стандартных дескрипторах файлов.Стандартные дескрипторы файлов
Всё в Linux - это файлы, в том числе - ввод и вывод. Операционная система идентифицирует файлы с использованием дескрипторов.
Эти три специальных дескриптора обрабатывают ввод и вывод данных в сценарии.
Вам нужно как следует разобраться в стандартных потоках. Их можно сравнить с фундаментом, на котором строится взаимодействие скриптов с внешним миром. Рассмотрим подробности о них.STDIN
STDIN - это стандартный поток ввода оболочки. Для терминала стандартный ввод - это клавиатура. Когда в сценариях используют символ перенаправления ввода - < , Linux заменяет дескриптор файла стандартного ввода на тот, который указан в команде. Система читает файл и обрабатывает данные так, будто они введены с клавиатуры.STDOUT
STDOUT - стандартный поток вывода оболочки. По умолчанию это - экран. Большинство bash-команд выводят данные в STDOUT , что приводит к их появлению в консоли. Данные можно перенаправить в файл, присоединяя их к его содержимому, для этого служит команда >> .
То, что выведет pwd , будет добавлено к файлу myfile , при этом уже имеющиеся в нём данные никуда не денутся.
После выполнения этой команды мы увидим сообщения об ошибках на экране.
Попытка обращения к несуществующему файлу
STDERR
STDERR представляет собой стандартный поток ошибок оболочки. По умолчанию этот дескриптор указывает на то же самое, на что указывает STDOUT , именно поэтому при возникновении ошибки мы видим сообщение на экране.▍Перенаправление потока ошибок
Как вы уже знаете, дескриптор файла STDERR - 2. Мы можем перенаправить ошибки, разместив этот дескриптор перед командой перенаправления:
Сообщение об ошибке теперь попадёт в файл myfile .
Перенаправление сообщения об ошибке в файл
▍Перенаправление потоков ошибок и вывода
При написании сценариев командной строки может возникнуть ситуация, когда нужно организовать и перенаправление сообщений об ошибках, и перенаправление стандартного вывода. Для того, чтобы этого добиться, нужно использовать команды перенаправления для соответствующих дескрипторов с указанием файлов, куда должны попадать ошибки и стандартный вывод:
Перенаправление ошибок и стандартного вывода
Перенаправление STDERR и STDOUT в один и тот же файл
Перенаправление вывода в скриптах
Существует два метода перенаправления вывода в сценариях командной строки:▍Временное перенаправление вывода
В скрипте можно перенаправить вывод отдельной строки в STDERR . Для того, чтобы это сделать, достаточно использовать команду перенаправления, указав дескриптор STDERR , при этом перед номером дескриптора надо поставить символ амперсанда (&):
Если запустить скрипт, обе строки попадут на экран, так как, как вы уже знаете, по умолчанию ошибки выводятся туда же, куда и обычные данные.
Временное перенаправление
Как видно, теперь обычный вывод делается в консоль, а сообщения об ошибках попадают в файл.
Сообщения об ошибках записываются в файл
▍Постоянное перенаправление вывода
Если в скрипте нужно перенаправлять много выводимых на экран данных, добавлять соответствующую команду к каждому вызову echo неудобно. Вместо этого можно задать перенаправление вывода в определённый дескриптор на время выполнения скрипта, воспользовавшись командой exec:
Запустим скрипт.
Перенаправление всего вывода в файл
Вот что получится после запуска скрипта и просмотра файлов, в которые мы перенаправляли вывод.
Перенаправление вывода в разные файлы
Перенаправление ввода в скриптах
Для перенаправления ввода можно воспользоваться той же методикой, которую мы применяли для перенаправления вывода. Например, команда exec позволяет сделать источником данных для STDIN какой-нибудь файл:
Эта команда указывает оболочке на то, что источником вводимых данных должен стать файл myfile , а не обычный STDIN . Посмотрим на перенаправление ввода в действии:
Вот что появится на экране после запуска скрипта.
Перенаправление ввода
Создание собственного перенаправления вывода
Перенаправляя ввод и вывод в сценариях, вы не ограничены тремя стандартными дескрипторами файлов. Как уже говорилось, можно иметь до девяти открытых дескрипторов. Остальные шесть, с номерами от 3 до 8, можно использовать для перенаправления ввода или вывода. Любой из них можно назначить файлу и использовать в коде скрипта.
После запуска скрипта часть вывода попадёт на экран, часть - в файл с дескриптором 3 .
Перенаправление вывода, используя собственный дескриптор
Создание дескрипторов файлов для ввода данных
Перенаправить ввод в скрипте можно точно так же, как и вывод. Сохраните STDIN в другом дескрипторе, прежде чем перенаправлять ввод данных.
Испытаем сценарий.
Перенаправление ввода
Закрытие дескрипторов файлов
Оболочка автоматически закрывает дескрипторы файлов после завершения работы скрипта. Однако, в некоторых случаях нужно закрывать дескрипторы вручную, до того, как скрипт закончит работу. Для того, чтобы закрыть дескриптор, его нужно перенаправить в &- . Выглядит это так:
После исполнения скрипта мы получим сообщение об ошибке.
Попытка обращения к закрытому дескриптору файла
Получение сведений об открытых дескрипторах
Для того, чтобы получить список всех открытых в Linux дескрипторов, можно воспользоваться командой lsof . Во многих дистрибутивах, вроде Fedora, утилита lsof находится в /usr/sbin . Эта команда весьма полезна, так как она выводит сведения о каждом дескрипторе, открытом в системе. Сюда входит и то, что открыли процессы, выполняемые в фоне, и то, что открыто пользователями, вошедшими в систему.
Для того, чтобы узнать PID текущего процесса, можно использовать специальную переменную окружения $$ , в которую оболочка записывает текущий PID .
Вывод сведений об открытых дескрипторах
Вот что получится, если этот скрипт запустить.
Просмотр дескрипторов файлов, открытых скриптом
Подавление вывода
Иногда надо сделать так, чтобы команды в скрипте, который, например, может исполняться как фоновый процесс, ничего не выводили на экран. Для этого можно перенаправить вывод в /dev/null . Это - что-то вроде «чёрной дыры».
Тот же подход используется, если, например, надо очистить файл, не удаляя его:Итоги
Сегодня вы узнали о том, как в сценариях командной строки работают ввод и вывод. Теперь вы умеете обращаться с дескрипторами файлов, создавать, просматривать и закрывать их, знаете о перенаправлении потоков ввода, вывода и ошибок. Всё это очень важно в деле разработки bash-скриптов.
В данной статье хочу систематизировать свои знания по основным принципам работы программных потоков и каналов
в интерпретаторе и в общем в ОС Linux, а так же о возможностях перенаправления
данных потоков
.
В самом начале хочу отметить, что интерпретатор работает с тремя стандартными потоками:
Stdout
, показан красным, имеет дескриптор 1
Stderr
, показан синим, имеет дескриптор 2